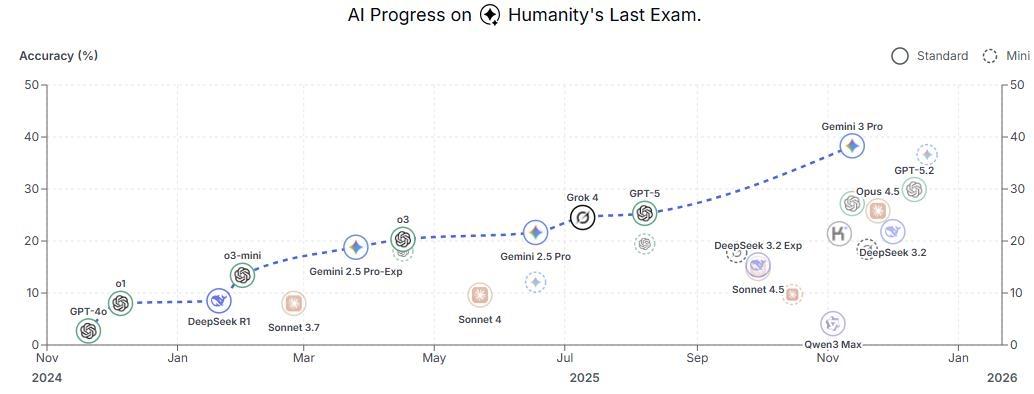
全球AI折戟“HLE大考”!这场“人类最后的考试”究竟难在哪? 2026年1月29日,国际学术杂志《自然》公开了一项号称“人类最后的考试”(Humanity’s Last Exam,HLE)的AI性能测试,引发全球科技领域关注。在AI技术飞速迭代、轻松攻克各类人类考试的当下,这场测试却让谷歌、OpenAI等巨头的顶尖模型纷纷“碰壁”,也让人们重新审视人工智能的能力边界。 一、HLE:集结全球智慧的“AI终极测试” HLE并非单一机构的成果,而是由美国非营利组织AI安全中心(CAIS)与初创企业Scale AI牵头,耗时近一年打磨而成——去年1月首次亮相后,经全球50个国家、500多个机构的1000余名教授和研究人员共同完善,最终以正式论文形式发布。 从测试设计来看,HLE的“难度”体现在两大核心: 1. 覆盖领域极广:囊括数学、物理、化学、生物、工程学、计算机科学、人文学等100多个具体学科,甚至包含翻译罗马墓碑碑文、分析蜂鸟种子骨肌腱支撑数量等高度专业的细分问题; 2. 筛选标准严苛:所有题目均经过双重把关——先排除当时性能最强AI能解决的问题,再由领域专家打分,仅高分题目才能入选,同时还包含需“文字+图像”协同理解的多模式题目,全面考验AI的综合推理能力。 数据显示,数学题是HLE的“重头戏”,占比达41%,这类题目往往涉及复杂计算,对精度要求极高,也成为AI失分的重灾区。 二、顶尖AI表现拉胯:谷歌模型最高分不足40% 面对这场“大考”,全球主流AI模型的表现远超预期地“平庸”。据AI安全中心公布的结果: 国际巨头模型中,谷歌Jaminai3 Pro以38.3%的准确率排名第一,OpenAI的GPT-5.2得29.9%,Opus 4.5和DeepSik 3.2分别仅得25.8%、21.8%,K-EXAONE”得分13.6%,Upstage的“Solar Open”得10.5%,SK电信的“A.XK1”仅得7.6%。 三、HLE不是“终点”:与通用人工智能(AGI)还差得远 尽管HLE被称作“人类最后的考试”,但研究人员明确强调:不应过度解读其意义。即便AI在HLE中拿高分,也仅代表它在“学术问题解答能力”上有提升,远不意味着能像人类一样主导新研究,更未达到“通用人工智能(AGI)”的水平——AGI需具备自主学习、跨领域创新等核心能力,而目前没有任何基准能真正测试AGI,“HLE更像一个‘阶段性标杆’,未来还会有更多更精准的测试基准出现。” 结语:HLE揭开AI“能力泡沫”,未来需更精准的评估体系 HLE的出现,本质上是给快速发展的AI行业“泼了一盆冷水”——它证明AI在“专业深度”“细节精度”“跨模态协同”上仍远逊于人类,也让全球意识到:AI评估不能仅停留在“刷分”层面,更需关注实际应用中的能力边界与安全风险。 未来,随着“审判日”等新基准的推进,AI测试将从“学术能力”向“安全可控”延伸。而这场关于“AI究竟能走多远”的探索,或许才刚刚开始。