【Google 杀招 MTP 架构!Gemma 4 推理速度飙升 3 倍】
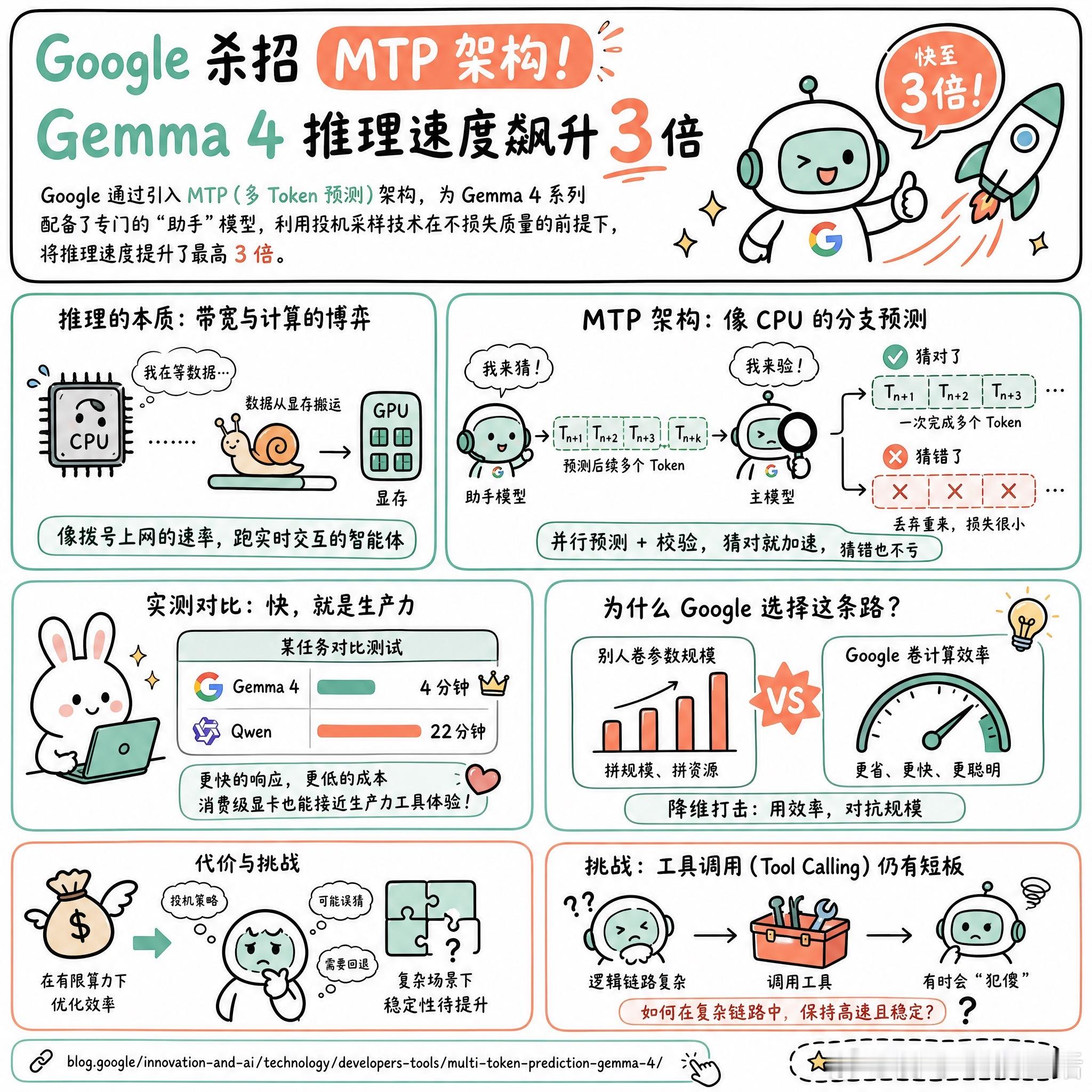
快速阅读:Google 通过引入 MTP(多 Token 预测)架构,为 Gemma 4 系列配备了专门的“助手”模型,利用投机采样技术在不损失质量的前提下,将推理速度提升了最高 3 倍。
现在的 LLM 推理本质上是在玩一场带宽与计算的博弈。大多数时候,处理器并不是在“思考”,而是在苦等数据从显存搬运到计算单元。这就像是在用拨号上网时代的速率,去跑一个需要实时交互的智能体。
Google 的策略很有意思。他们没有一味追求参数规模的堆叠,而是把重心放在了计算效率上。Gemma 4 引入的 MTP 架构,逻辑很像 CPU 里的分支预测。它让一个极小的“助手”模型先去“猜”后面几个 Token,主模型再并行校验。如果猜对了,就像是一次性完成了多次指令流水线;如果猜错了,也就只是丢弃掉错误的预测,重新执行而已。
有网友提到,这种做法让 Gemma 在某些任务上表现得极其轻快。比如在对比测试中,虽然 Qwen 在某些基准上略胜一筹,但 Gemma 仅用 4 分钟就完成了任务,而对手可能要跑 22 分钟。这种“性价比”在本地部署时尤为重要,它意味着你可以在消费级显卡上,获得接近生产力工具的响应速度。
当然,这种策略也有代价。有观点认为,Google 似乎在通过这种方式,试图在有限的算力资源下,通过优化效率来对抗其他厂商的规模扩张。这更像是一种“降维打击”:当大家都在卷参数规模时,Google 在卷如何让模型跑得更省、更快。
不过,这种“投机”策略在工具调用(Tool Calling)上偶尔也会显得有些笨拙。如何让这种高速的预测,在复杂的逻辑链路中保持稳定,依然是个悬而未决的问题。
blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/