DeepSeek更新DeepSeek引入新注意力机制
刚发V3.1“最终版”,DeepSeek最新模型又来了!
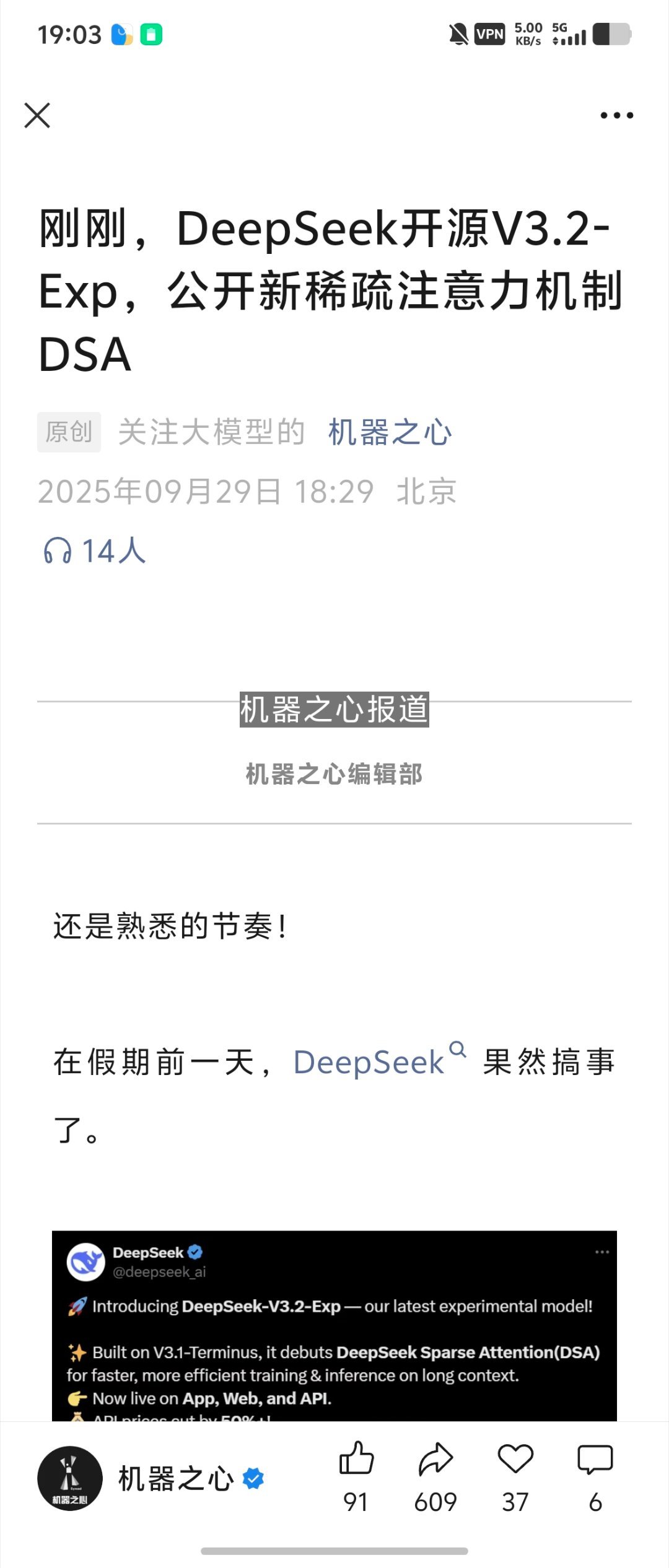
DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。
还开源了更高效的TileLang版本GPU算子!
目前,官方App、网页端、小程序均已同步更新,同时还有API大减价:5折起。
这波DeepSeek国庆大礼包,属实有点惊喜了。
DeepSeek-V3.2-Exp基于上周刚更新的DeepSeek-V3.1-Terminus打造,核心创新是引入了DeepSeek Sparse Attention(DSA)稀疏注意力机制。
DSA首次实现了细粒度注意力机制,能在几乎不影响模型输出效果的前提下,实现长文本和推理效率大幅提升。
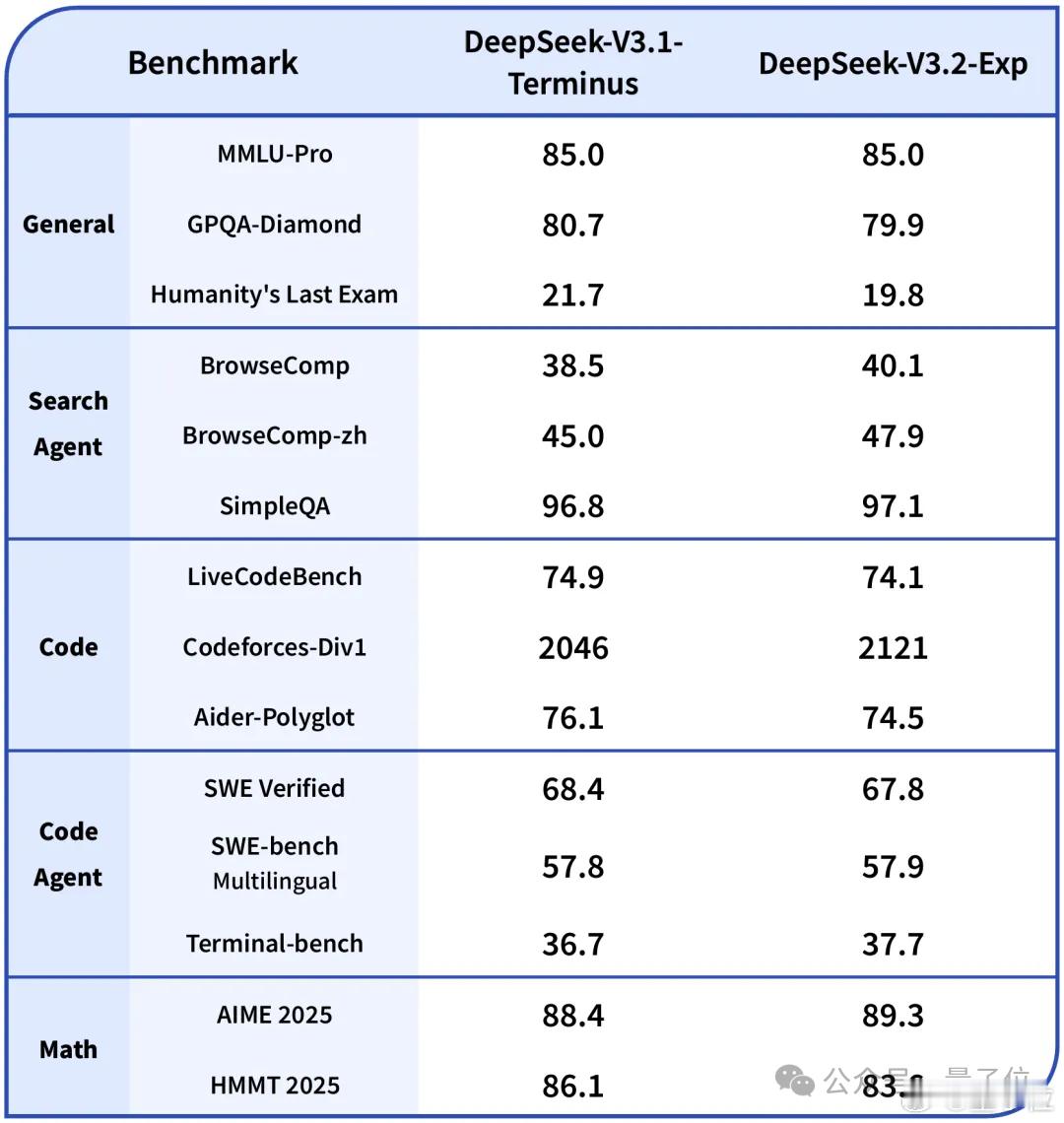
与前不久更新的DeepSeek-V3.1-Terminus对比,在各领域公开测评集上,DeepSeek-V3.2-Exp和V3.1-Terminus基本持平。
V3.1-Terminus是在 DeepSeek-V3.1基础上的一个强化版本,在稳定性、工具调用能力、语言一致性、错误修正等方面进行迭代改进。
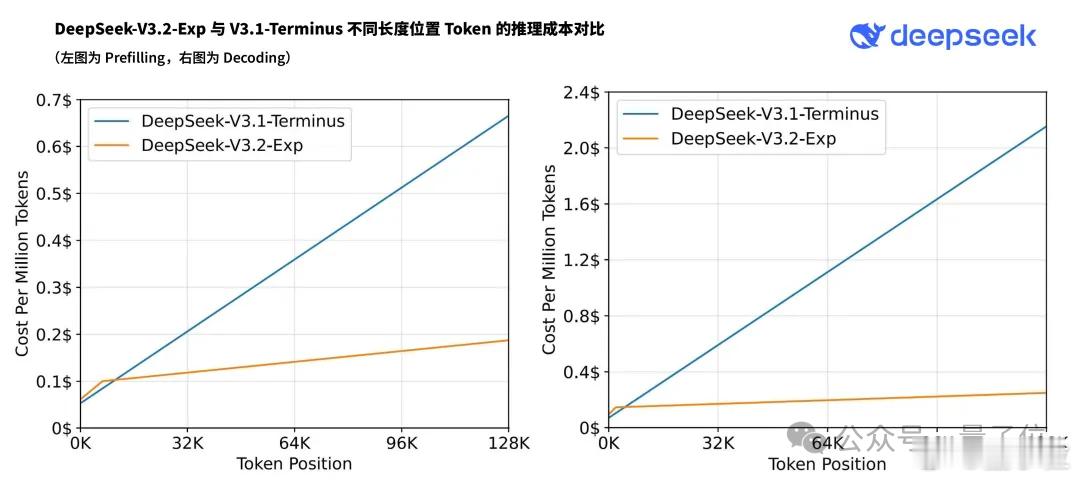
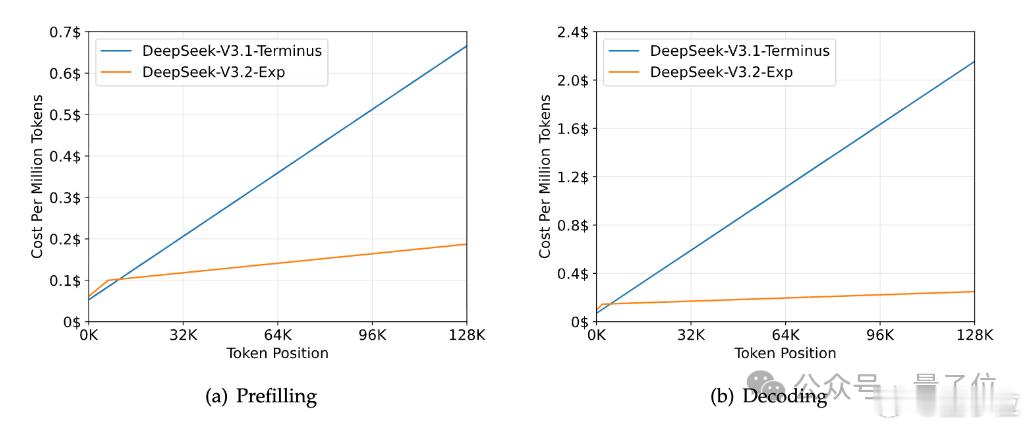
另外,论文提到,使用DSA的模型在处理128K长上下文时,推理成本显著低于DeepSeek-V3.1-Terminus,尤其在解码阶段。