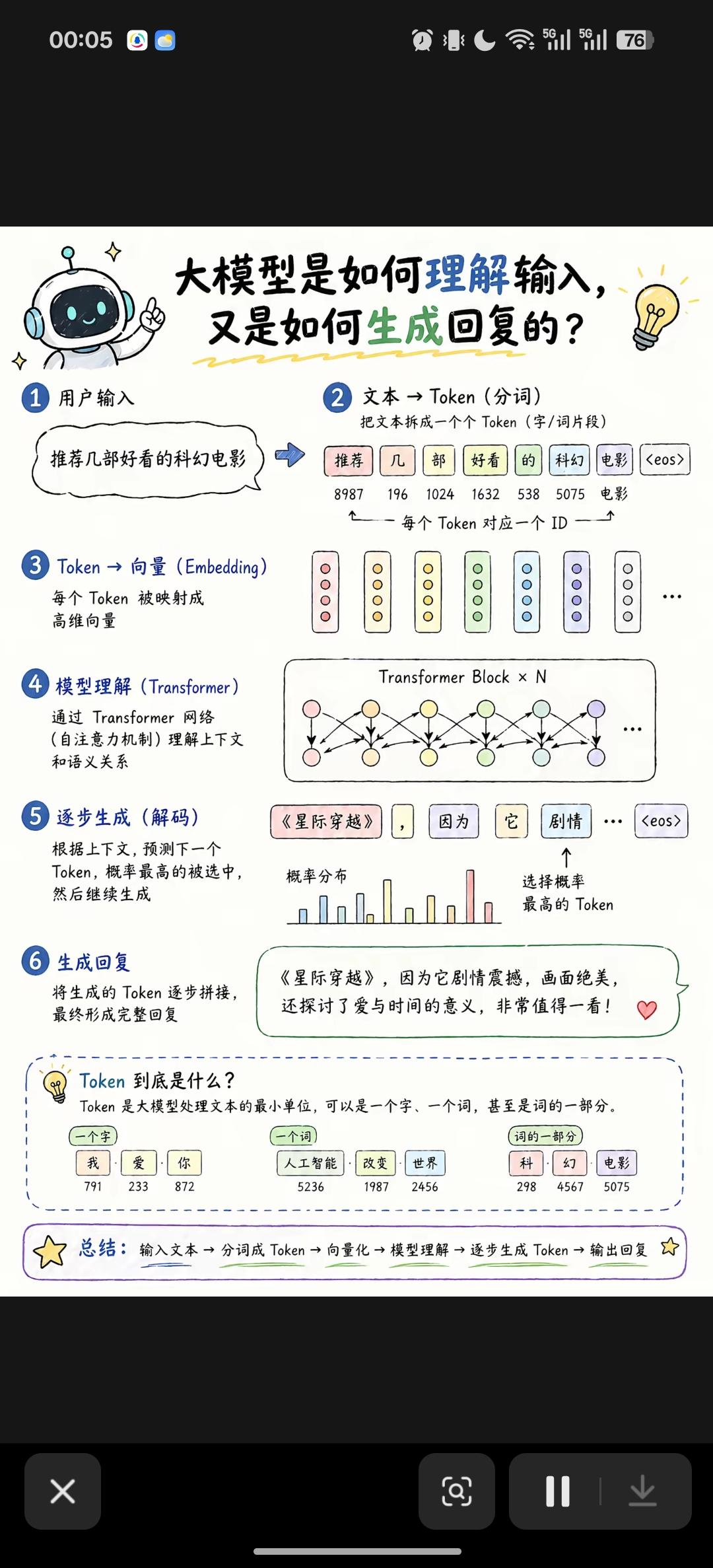
大模型输入理解与生成回复全流程解析 这张图用通俗的方式,完整拆解了大模型从接收提问到输出回答的6步核心流程,同时解释了核心概念Token。 一、完整执行6步流程 1. 用户输入 用户提出自然语言问题,示例: 推荐几部好看的科幻电影 。 2. 文本 → Token(分词) 将整句文本拆分成最小语义单位Token,每个Token对应唯一数字ID,末尾会添加结束标记 。 示例拆分: 推荐、几、部、好看、的、科幻、电影 。 3. Token → 向量(Embedding嵌入) 把每个Token映射为高维数字向量,将文字转化为模型能读懂的数字形式,同时携带语义信息。 4. 模型理解(Transformer) 通过多层Transformer网络的自注意力机制,学习Token之间的上下文关系、语义逻辑,完成对问题的深度理解。 5. 逐步生成(解码) 模型基于已理解的上下文,逐个预测下一个Token,计算每个候选词的概率,选择概率最高的输出,循环迭代直到生成结束标记。 6. 生成最终回复 将逐一生成的Token拼接成完整句子,输出自然语言回复。 二、核心概念:Token是什么 Token是大模型处理文本的最小单位,形式分为3类: - 单个汉字:如 我、爱、你 - 完整词语:如 人工智能、改变、世界 - 词语片段:如 科、幻、电影 同时Token也是计费、上下文长度、成本核算的核心单位。 三、极简总结公式 输入文本 → 分词成Token → 向量化 → Transformer模型理解 → 逐Token生成 → 输出完整回复 大模型数据困境 ai大模型营销 大模型代码 量化大模型 大模型推荐系统 ai免费大模型 场景理解与生成