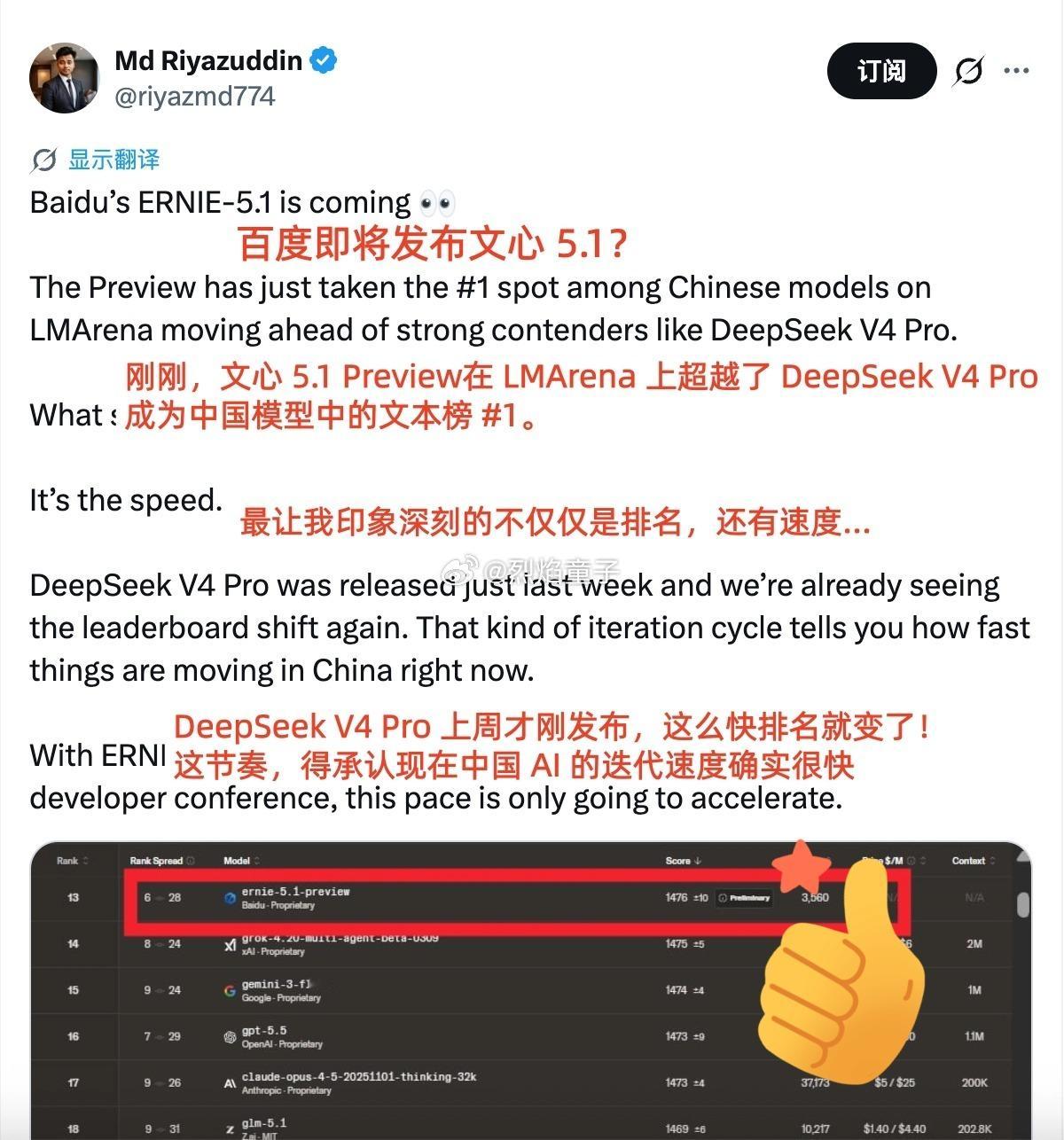
我今天刷到,LMArena大模型竞技场更新了最新排名。
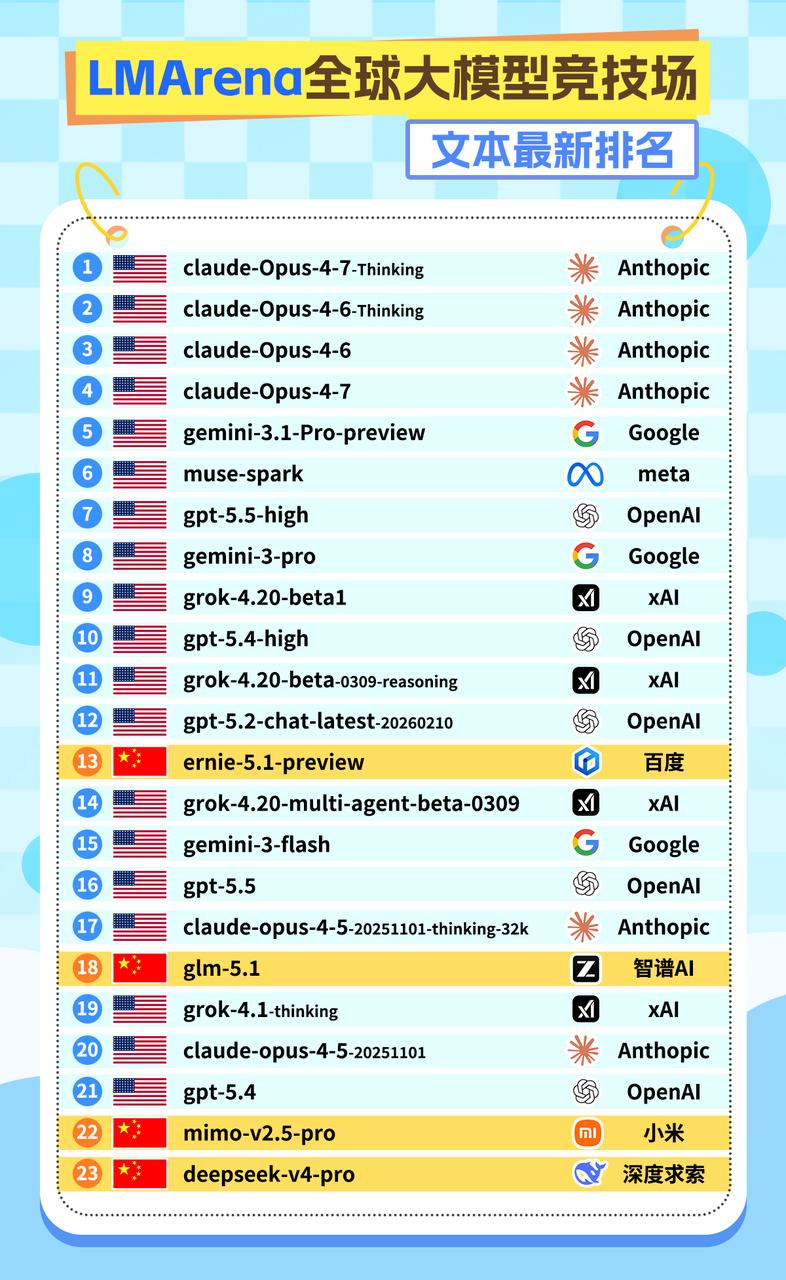
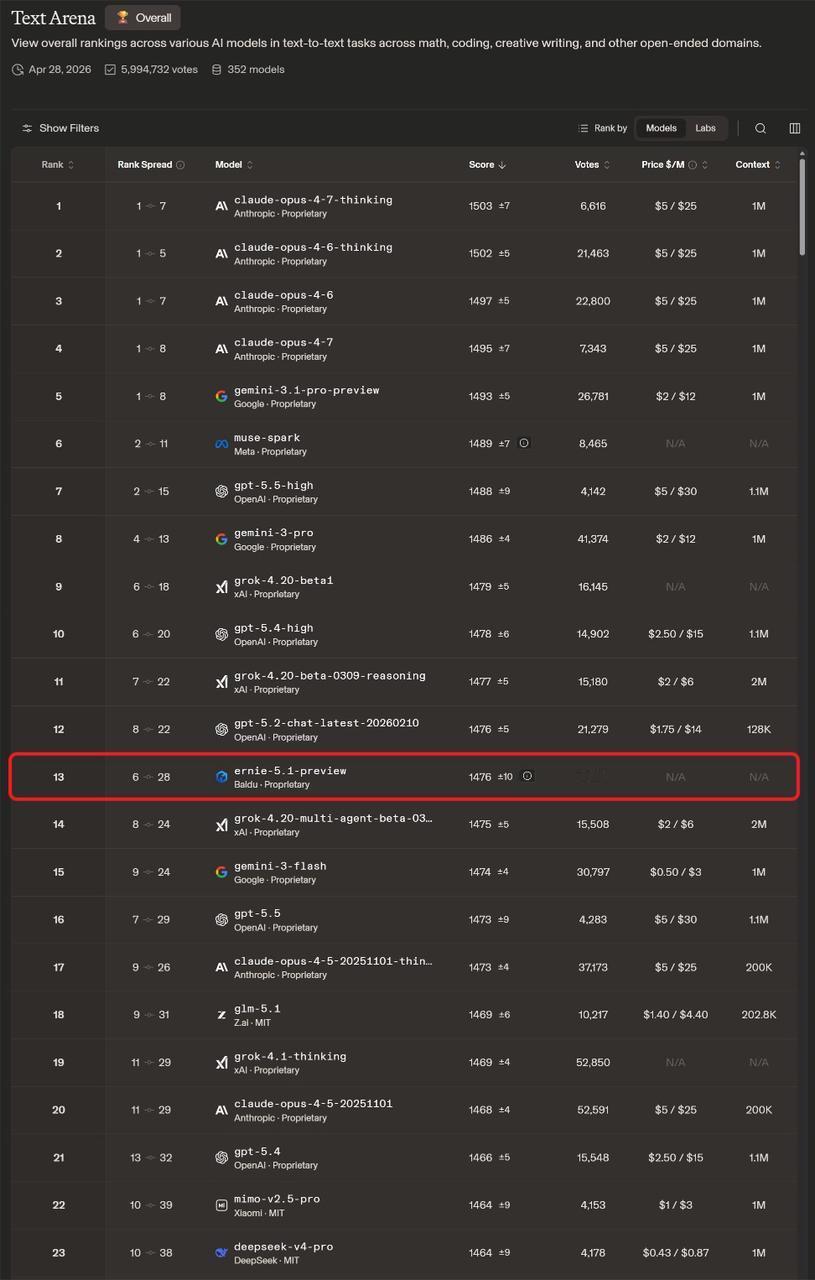
这次入榜前十五的模型里,唯一一个国产模型,是文心5.1 Preview,得分1476,文本能力排名国内第一。它排在了GPT-5.5之前,也排在了DeepSeek-V4-Pro之前。
聊这个之前,我们先思考一个问题:为什么DeepSeek V4还是文本模型?🤔
你在用大模型写代码的时候,表面上看是在生成代码,但底层其实是要理解你说的话,然后用另一种语言表达出来。代码,本质上也是一种文本。
复杂推理也是一样,模型在一步步推导的过程中,依赖的是对语言逻辑的把控。多模态能力稍微复杂一点,但在图像和语音进入模型之后,最终的理解、生成、输出,仍然要走文本这条路。
「文本能力是地基,其他能力都是在地基上盖起来的。」
所以即便到了DeepSeek V4这个量级,它的核心形态依然是文本模型,这是大模型发展到现在,依然没有被绕开的底层逻辑。
那这次文心赢在哪?在同一张榜单上,文心5.1 Preview排在了DeepSeek-V4-Pro和GPT-5.5前面。这俩,都是最近才发布、行业内讨论热度最高的模型。
我们先看文心这次用了什么技术。据了解,这次文心能力跃迁的背后,有一个关键技术叫"多维弹性预训练"。
正常训练一个模型,就像你专门为某个身高定制一套西装,量体裁衣,做完只适合那一个人穿。而弹性预训练更像是在做一套可伸缩的服装版型,训练一次,可以裁出大号、中号、小号,都能穿,都合身。通过一次训练,同时生成多种不同规模的模型。
那这带来了什么实际价值?——成本。文心5.1 Preview以同规模模型约6%的预训练成本,实现了基础效果的领先。更重要的是,这套机制让迭代速度变快了。
过去一段时间,国内模型在文本这条赛道上,整体处于追赶的状态。
这次不一样的地方在于:文心5.1 Preview拿到的这个位置,是在全球竞争最激烈的文本能力榜单上,稳定出现在了前十五名里,而且是唯一的国产模型。
目前文心5.1 Preview已经在百度千帆模型广场开启邀测,面向企业用户和开发者。另外,有消息称文心大模型5.1可能会在5月百度Create 2026开发者大会上正式亮相。
感兴趣的开发者可以去千帆平台申请体验。我最近打算去测一下,有结论了会继续写。