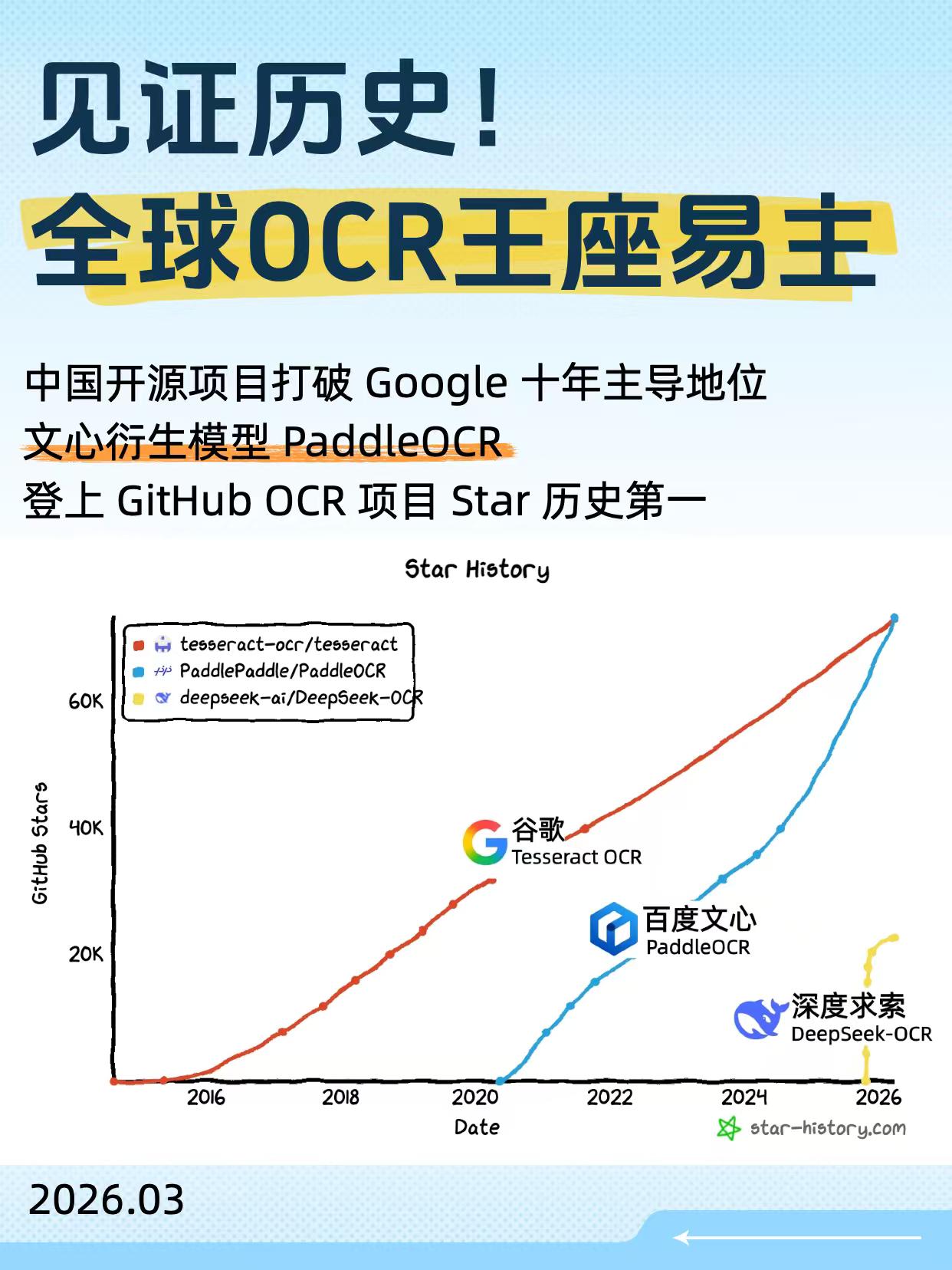
【中国OCR超越谷歌全球登顶,一场关于"数据入口"的暗战正在打响】 3月27日,百度文心衍生模型PaddleOCR在GitHub上的Star数首次超越了谷歌 TesseractOCR,成为全球 Star数最高的OCR项目。此外,最近百度、DeepSeek、智谱这些AI头部厂商,也几乎在同一时间加码OCR。这绝非巧合,这场“OCR 热”的背后,藏着下一代AI竞争的核心密码:数据入口的争夺。 表面上看,大家都在拼大模型的能力,但真正的瓶颈已经显现——高质量训练数据正在日趋饱和。互联网上的优质内容这些年被翻来覆去地训练,AI要再进一步,必须找到新的数据源头。而这个源头,就藏在现实世界的海量文档里。事实上,超过80%的信息仍沉淀在文档、书籍、合同、表格等离线载体中。这些数据的体量远超互联网公开内容,但过去机器根本读不懂。它们必须依赖OCR,才能被转化为可被模型理解的数据。 OCR正是打开这座金矿的钥匙。它不再只是"把图片文字转成可编辑文本"的工具,而是连接现实世界与数字世界的重要入口——通过将图像中的文字与版面结构转化为机器可理解的电子化文本,能够为大模型提供更丰富、更真实、更高价值的数据来源。 理解了这一点,就能看懂为什么百度要把文心大模型的能力注入PaddleOCR;也能理解DeepSeek、智谱为何紧随其后。大家争夺的不是一个技术工具,而是谁能率先掌握"现实世界信息入口"的主导权。 更深一层看,这场布局折射出AI竞争逻辑的深刻转变。AI的竞争正在从单纯的模型能力,转向数据获取、处理与利用效率的综合比拼。谁能构建更强的OCR能力,谁就更有机会掌握现实世界的信息入口,打造出最前沿、优质的模型。 所以,OCR正在从文档解析工具,演变为大模型竞争中的基础能力。百度PaddleOCR超越谷歌Tesseract,不只是开源项目的阶段性突破,也预示着OCR在AI时代中的地位正在被重新定义。这场关于"数据入口"的暗战,才刚刚拉开序幕。