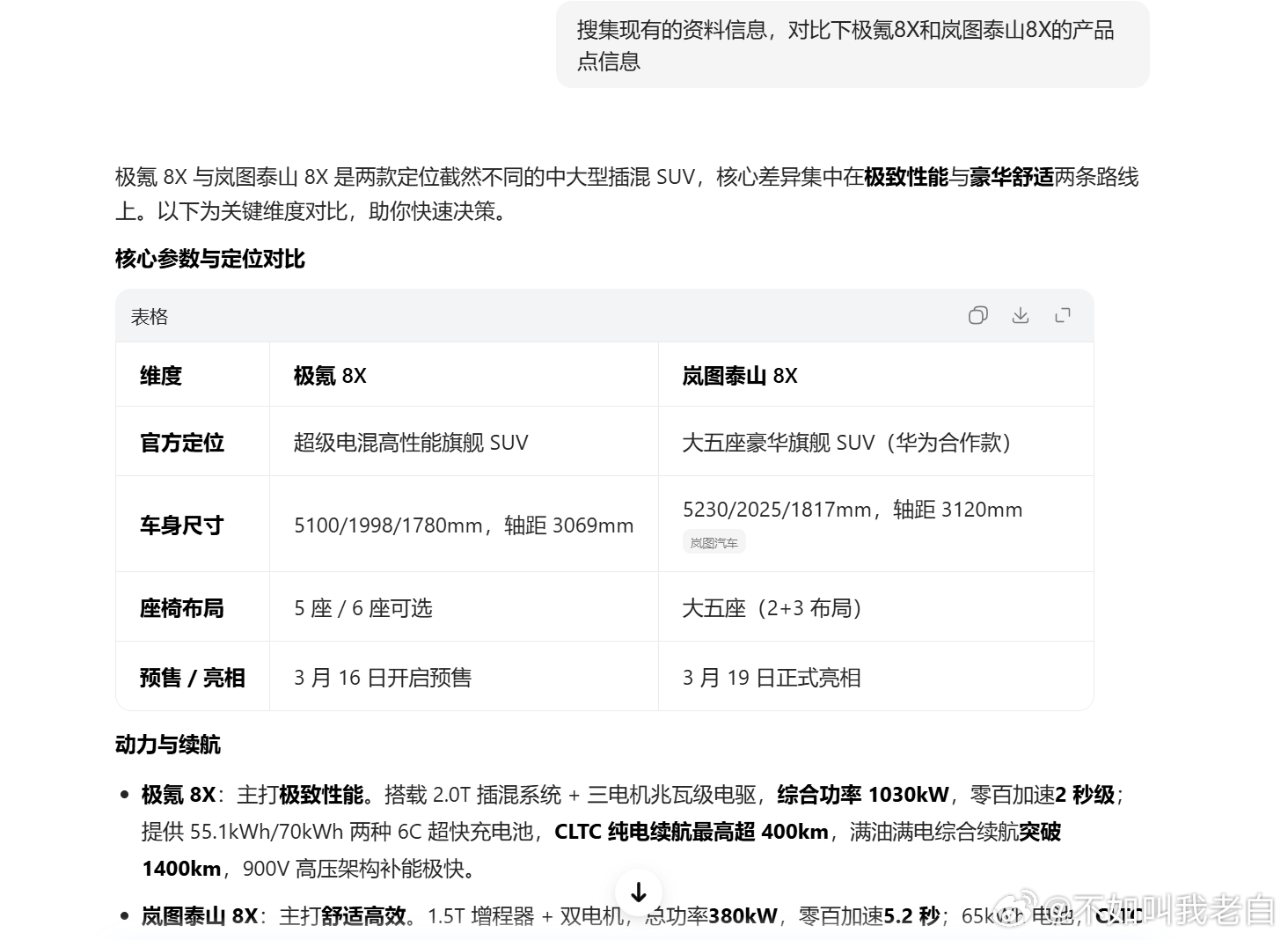
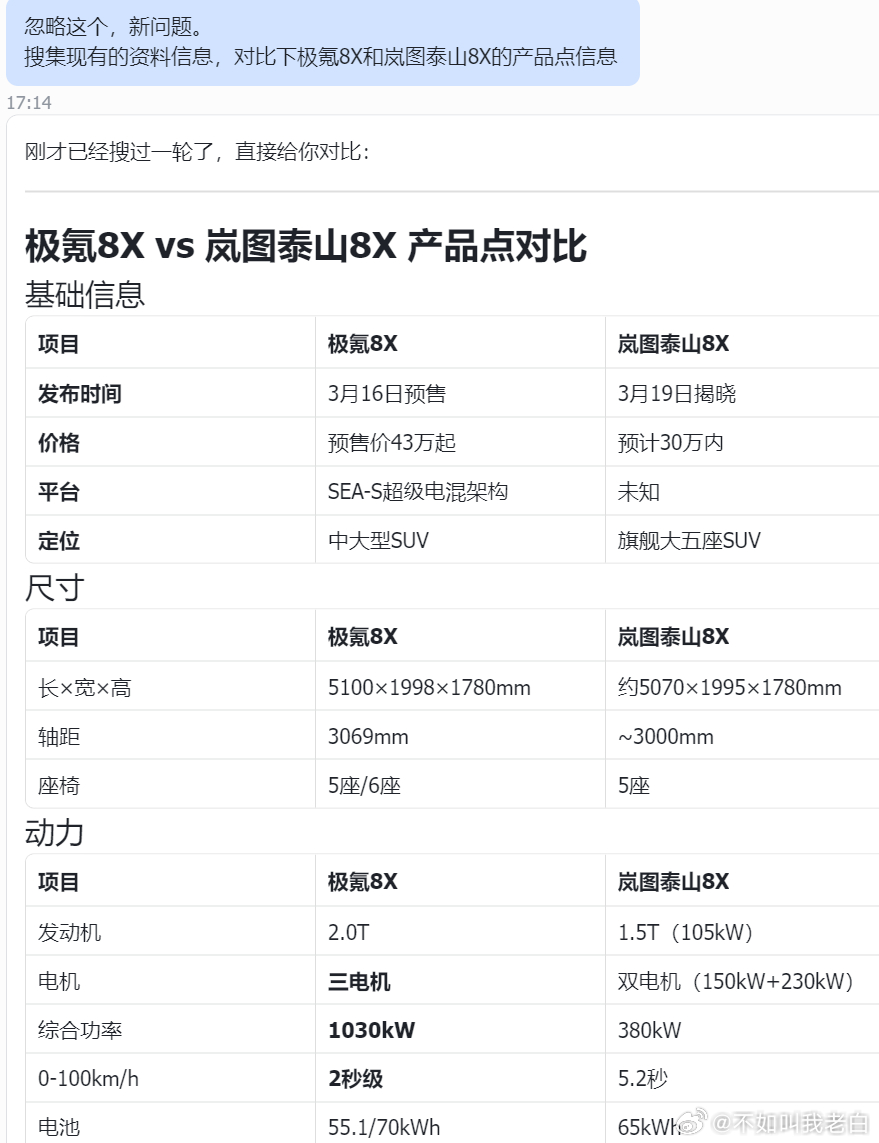
做了一个有意思的实验,目的是辨别AI对于错误表述的甄别能力,但没想到毛病其实有很多。参赛选手是【openclaw】、【kimi】和【豆包】我的问题是【搜集现有的资料信息,对比下极氪8X和岚图泰山8X的产品点信息】
这个问题里面的陷阱是,岚图泰山即将要推出的新车是X8,而非8X。其中,只有kimi意识到问题,并且在自己的解读中回复是X8。其余两个模型,依旧延续我的表述来回答问题。此为一
其次,在生成速度上,豆包>kimi>openclaw,龙虾用了1分钟才回复了信息。且在回复质量排名kimi>豆包>openclaw。openclaw甚至出现了2秒级的加速这种一眼假的回复。如果你是AI信息盲目者,是真的会被它们坑死。
其次,车身尺寸这类信息上,豆包和龙虾也是肉眼可见的错误。一个说5070,一个说5300,差距也是离谱。
所以你要问我AI好用吗?我只能说慎重吧。图一kimi,图二豆包,图三是openclaw(模型为minimax)国产大模型聚齐了