[CL]《Long-Tail Knowledge in Large Language Models: Taxonomy, Mechanisms, Interventions and Implications》S Badhe, D Shah, N Kathrotia [Google] (2026)
大模型看起来无所不知,但当你问及偏僻的方言、冷门的法律或罕见的疾病时,它往往会一本正经地胡说八道。这并非偶然,而是由其底层逻辑决定的系统性缺陷。本文深入剖析了LLM的“长尾知识”(Long-Tail Knowledge, LTK)困境,揭示了智能背后的阴影地带。
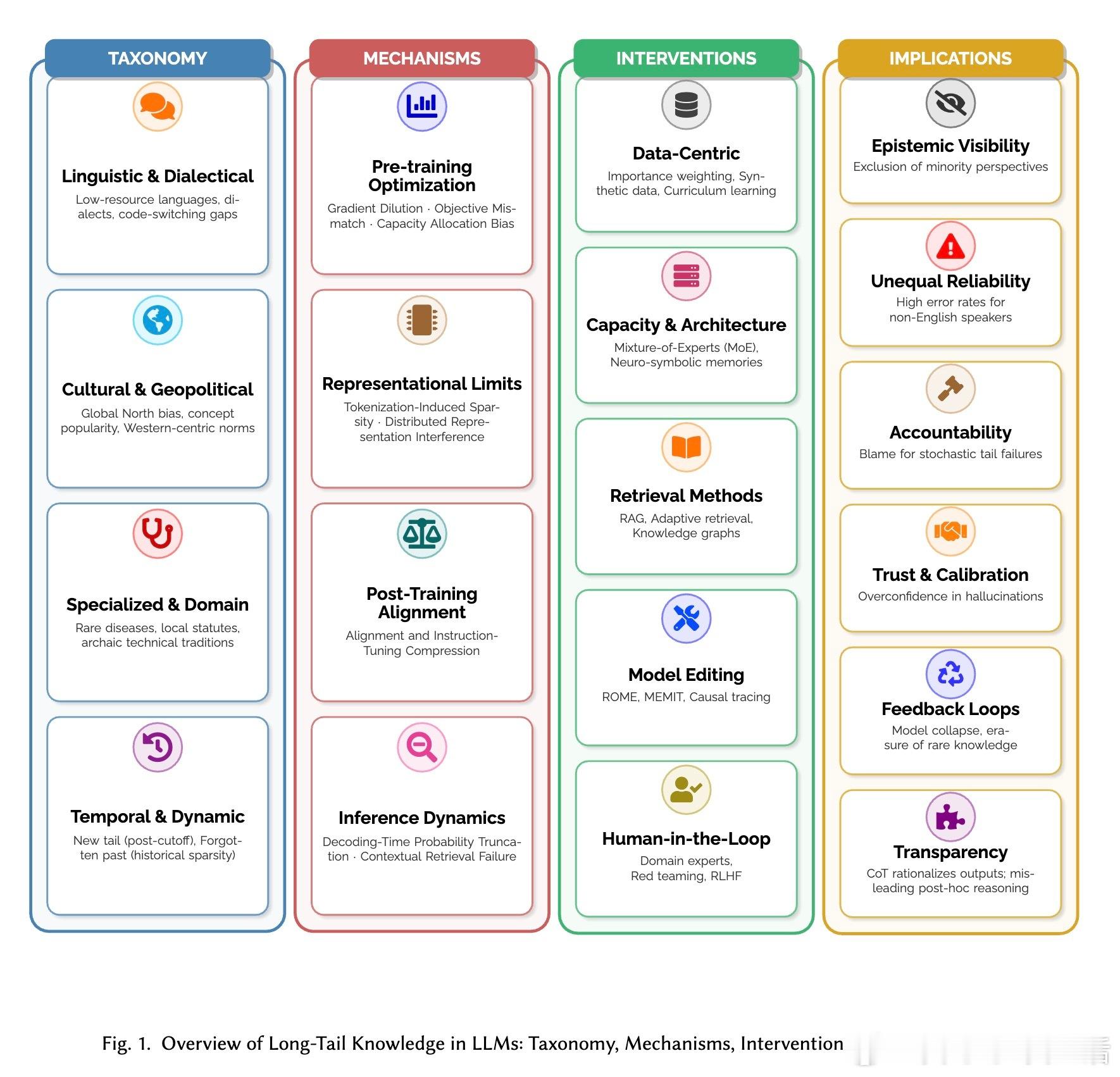
我们需要重新定义“长尾”。它不仅是出现频率低,更是一种数字权力的缺失。论文提出了四个维度的分类:语言的稀疏(如非标准方言)、文化的边缘(如非西方视角的价值观)、专业的深水区(如罕见病诊断)以及时间的断层(如训练截止后的新知)。长尾知识是那些在互联网语料库中仅占极小比例,却在现实世界中至关重要的真相。
知识的流失发生在每一个环节。在预训练阶段,梯度稀释让模型优先记住大众常识,稀有事实的信号被噪声淹没;在分词阶段,稀有实体被切碎成无意义的片段,失去了语义连贯性;在对齐阶段,为了追求安全和顺从,模型学会了对不确定的长尾知识“打太极”,甚至直接拒绝回答。
这是一个关于“生存空间”的博弈。在模型的参数空间里,高频知识占据了主干道,而长尾知识只能挤在阴影里的残差中。这种“分布式表示干扰”意味着,模型越是追求通用性,就越容易牺牲那些微小但关键的细节。参数的“叠加效应”让强者恒强,弱者被抹除。
补救措施并非万灵药。RAG(检索增强)虽然能外挂知识库,但受限于检索系统的偏见;模型编辑能对手术式修正错误,却可能引发认知的连锁反应。真正的挑战在于:我们是否能接受一个在统计上完美、但在细节上脆弱的智能?这种脆弱性在法律和医疗等高风险领域是不可接受的。
这不仅是技术问题,更是社会公平问题。当AI成为信息的中介,长尾知识的缺失意味着边缘文化的隐形。更危险的是“模型崩溃”:当互联网充斥着AI生成的平庸内容,真实的、稀有的知识将加速从数字记录中消失。这种反馈效应正在加剧知识的边际化。
现有的评估体系在某种程度上“粉饰太平”。像MMLU这样的主流榜单大多考察大众知识,这种“平均分”掩盖了特定人群在使用时的灾难性失败。在高风险领域,这种评估偏差可能导致责任真空:开发者声称模型通过了专业考试,但用户却在处理具体问题时遭遇了致命的幻觉。
衡量一个模型的文明程度,不应看它对常识的复读,而应看它对长尾的包容。在智能涌现的时代,了解AI“不知道什么”,远比赞美它“知道什么”更重要。我们需要从追求平均准确率,转向对每一个稀有真相的尊重。
论文原文:arxiv.org/abs/2602.16201