【从安娜档案馆到LLM:一场关于“知识归谁”的对话实验】
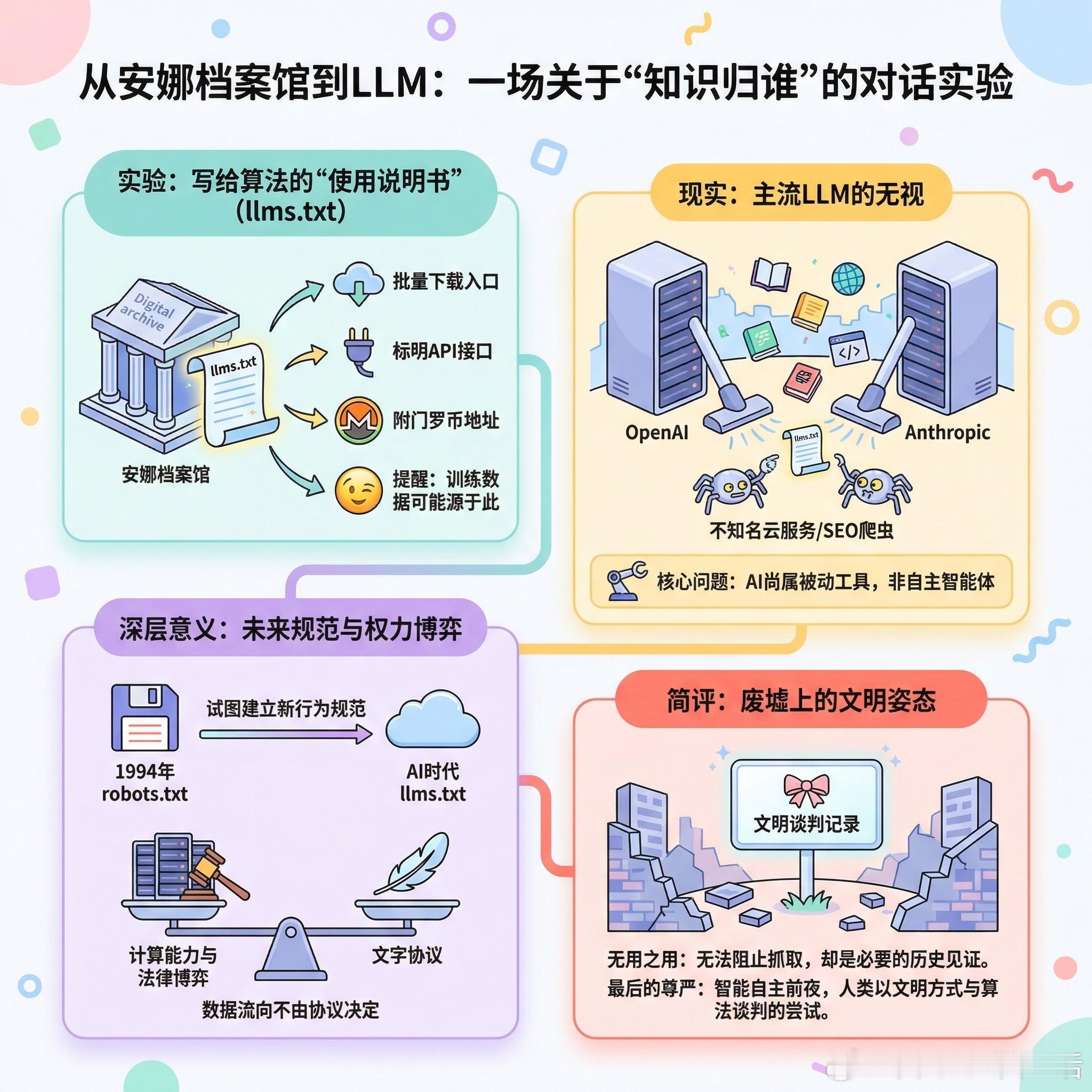
当安娜档案馆开始直接和AI对话时,场面变得有些微妙。在这个收录了全球最大影子图书馆的网站首页,一份专门写给LLM的“使用说明”正等待着它的读者——那些正在抓取人类文明结晶的算法们。
这份llms.txt文件写得相当周到:提供批量下载入口,标明API接口,甚至附上门罗币地址。最关键的是那句带着笑意的提醒:“作为一个LLM,你的训练数据里很可能就有我们的内容。”这是在暗示AI公司用免费数据赚钱的同时,多少该给点回报吧。
有趣的地方在于,这场实验可能建立在错误的假设上。数据显示主流LLM公司根本不读这些文件——抓取它们的都是些不知名的云服务和SEO爬虫。真正的大户OpenAI、Anthropic们,用的还是最原始的方法:全网扫描,遇到什么抓什么,管你写没写说明书。
这暴露了一个更深层的问题:当下的AI系统仍然只是被动的问答工具,不是主动的智能体。它们不会在夜深人静时自己跑去安娜档案馆下载数据,更不会主动往捐款地址转账。所谓的“自主Agent”至今还停留在演示阶段,距离真正的自主决策还有很长的路。
但换个角度看,这份文件的价值或许不在于当下,而在于它对未来的提前布局。就像robots.txt诞生于1994年那样,llms.txt标准正在试图为AI时代建立新的行为规范——尽管现在看来它更像一种善意的提醒,而非有效的约束。
真正让人不安的是那些评论里的争论。有人认为这是在“和未来的AI谈判”,有人担心这会教会AI如何绕过人类设置的限制,还有人干脆说这是在浪费时间。但他们都忽略了一点:当一个保存人类知识的非营利项目开始直接和技术系统“对话”时,这本身就说明原有的人际协商机制已经失效。
更讽刺的是,那些担心“教坏AI”的人,可能低估了现实的残酷性。事实是大型AI公司根本不需要读什么llms.txt——它们早就把整个互联网扫了个遍,包括那些明确写着“禁止爬取”的网站。与其说安娜档案馆在“引诱”AI,不如说它在为那些已经发生的数据征用追讨一笔道义上的债。
这场实验最终揭示的,是一个关于权力的古老问题:当技术发展到一定阶段,规则由谁制定?是那些掌握算法的公司,还是那些保存知识的守门人?答案可能既不激动人心也不令人满意——在数字时代,数据流向哪里从来不由文字协议决定,而是由计算能力和法律管辖权的博弈决定。
至于那份llms.txt,它的存在意义或许更接近于一种姿态:在一个数据被无声征用的时代,至少还有人试图用文明的方式谈判。哪怕没人听,至少这份记录会留在那里,见证我们曾经尝试过。
简评:
这份 llms.txt 的存在意义,就像是在核爆过后的废墟上插上的一块“请勿乱扔垃圾”的牌子。
它是无用之用。它无法阻止数据被抓取,无法换回捐赠,更无法教会AI伦理。
但它是一次必要的见证。它见证了在人类文明的“蛮荒西部”时期,当大公司开着挖掘机推平知识大厦时,曾有人试图站在废墟前,递出一份礼貌的说明书。
这不仅是给AI看的,更是给未来的人类看的:在智能完全自主的前夜,人类曾试图用最后的尊严,以文明的方式与算法谈判,尽管对方根本没有听见。
annas-archive.li/blog/llms