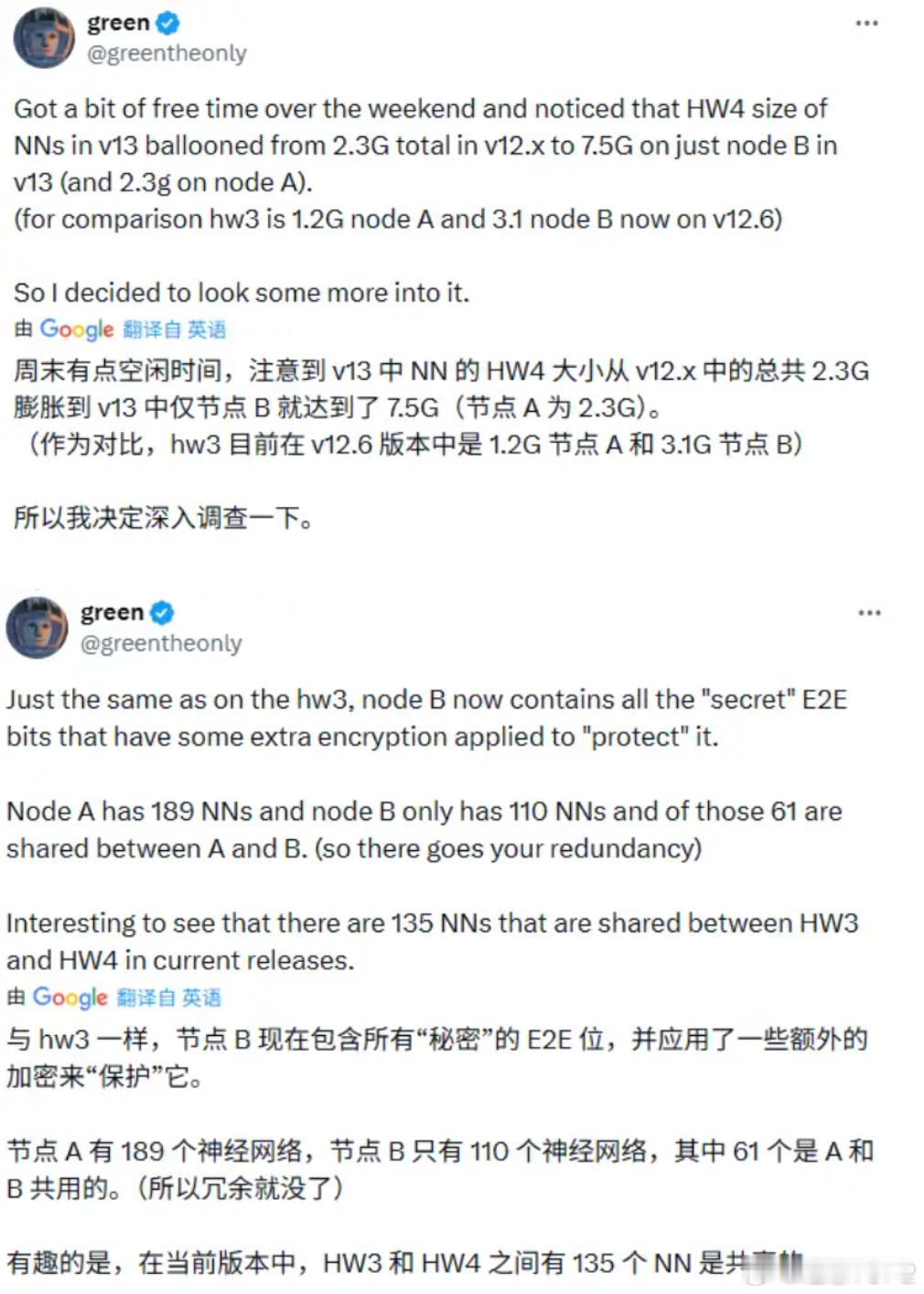
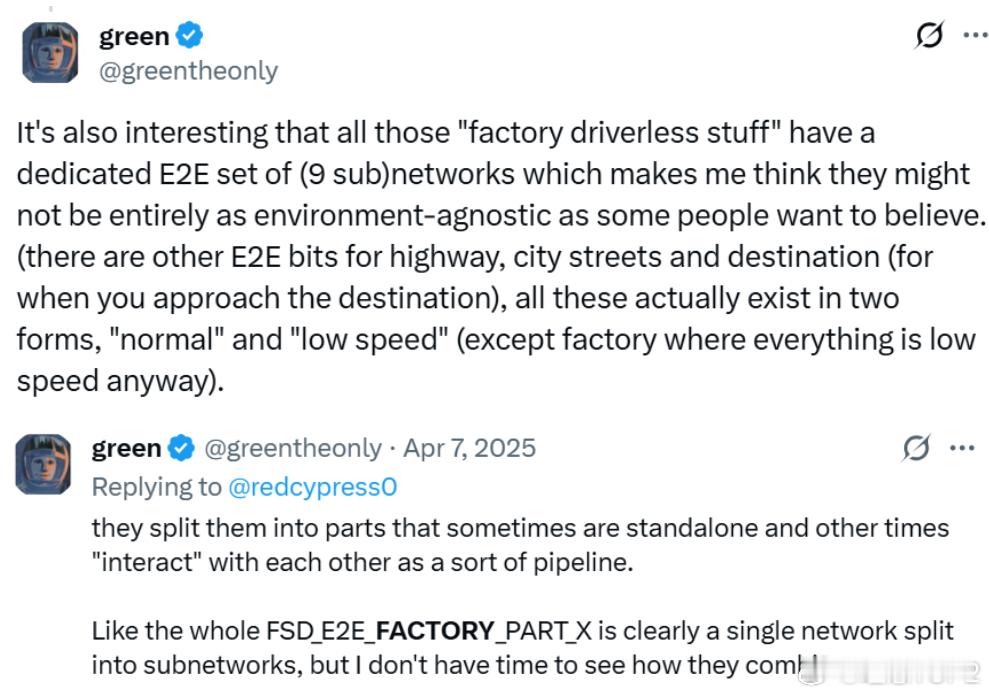
能看懂|讲清楚为什么刘延说特斯拉FSD是近200个小场景模型的组合2026年1月19日知乎用户刘延发布《智驾行业学习笔记|特斯拉FSD模型的非共识》最关键的一点是基于X用户green在2025年4月发的推文,如果认可green说的为真,则V13就一定有189个神经网络模型。节点 A 包含 189 个神经网络,而节点 B 包含 110 个神经网络,61 个神经网络为节点 A 与节点 B 所共享。HW3 与 HW4 平台之间共享的神经网络数量总计达到 135 个。HW3 平台在当前的 v12.6 版本中,其节点 A 大小为 1.2G,节点 B 大小为 3.1G;HW4在v13版本中,节点 A 大小为 2.3G,节点B 的大小增至 7.5G。图1为什么如果green说的为真,就一定有189个小模型?因为green是对固件的反向分析,实实在在数出来有189个独立的神经网络文件。green是是一位持续通过逆向工程的手段,深入挖掘特斯拉的车辆固件和硬件系统,有极高技术造诣的白帽黑客。与特斯拉的关系是一种微妙的对抗与合作共存的状态,green曾通过特斯拉漏洞赏金计划报告安全漏洞,受到了官方认可。另一方面green对保密信息的持续挖掘也会破坏特斯拉的节奏,正是green的存在才让V13有189个小模型变成一件几乎无可辩驳的事。green:同样有趣的是,所有那些‘工厂内无人驾驶功能’都拥有一套专用的端到端(E2E)网络组(包含 9 个子网络),这让我觉得,它们可能并不像某些人希望相信的那样完全‘不挑环境’(即具备通用的环境适应性)。 (此外,还有针对高速公路、城市街道和目的地——即当你接近目的地时——的其他 E2E 模块,所有这些实际上都存在两种形态:‘常速’和‘低速’——工厂模式除外,因为那里本来就全都是低速场景。green:他们把这些网络拆分成了若干部分,这些部分有时是独立运行的,有时又像某种流水线一样相互交互。举个例子,整个 FSD_E2E_FACTORY_PART_X(工厂端到端某部分)显然就是一个单一网络被拆解成了多个子网络,不过我现在还没时间去研究它们具体是如何重新组合在一起运作的。图2 刘延和猩红线歌者讨论中认为FSD没有agent那么智能,背后的锚点是认为LLM Agent更像是是推理,先思考,在决定调用哪个工具,每个agent都能独立处理复杂问题,FSD更像是人体的器官,肺只负责呼吸(工厂模型只用于工厂),心脏只负责跳动(城市模型只用于城市)。图3刘延提到HW3能跑36赫兹就肯定是小模型,背后的逻辑链是这样的36赫兹意味着处理一帧画面的时间必须小于1/36≈27.7ms一个100亿参数的模型在INT8精度下大约9.3GB,在INT4精度下大约4.7GB。自动驾驶行业一般是INT8精度,INT4被认为是激进精度。由于HW3只有68 GB/s的显存带宽,即使是INT4精度下,只能有 4.7/68≈69ms根本跑不到36赫兹。68 GB/s的显存带宽要想跑到36赫兹,理论模型最大上限是27.7ms*68GB/s≈1.88GB,这根本放不下单一的能处理所有情况的大模型。而green说HW3的模型大小为节点A大小为1.2GB,节点B大小为3.1GB,正好也能匹配。基于以上这些点,刘延认为特斯拉强在工程而非科学,特斯拉的丝滑,并非完全来自于它的算力和模型,有很大一部分是来自于特斯拉重写了车控操作系统,让从控制到执行的延时低了很多。理想汽车理想汽车理想i6理想i8理想MEGA理想VLA理想L6理想L7理想L8理想L9