《Scaling Laws for Deepfake Detection》
深度伪造检测的缩放律:ScaleDF数据集与关键洞见
深度伪造技术迅猛发展,正威胁社会安全,从误传信息到侵犯隐私,亟需可靠检测方法。在生成与检测的“军备竞赛”中,如何让检测模型适应层出不穷的新伪造形式?本文基于最新研究,系统探讨了数据规模与模型性能的预测关系,揭示了类似大语言模型的“规模定律”。通过构建史上最大数据集ScaleDF,本文证明:增加真实图像领域和伪造方法的多样性,能显著提升检测鲁棒性。这不仅仅是数据堆积,更是数据驱动的工程范式转变,帮助我们预估所需资源,主动应对AI伪造浪潮。
ScaleDF:前所未有的深度伪造检测数据集
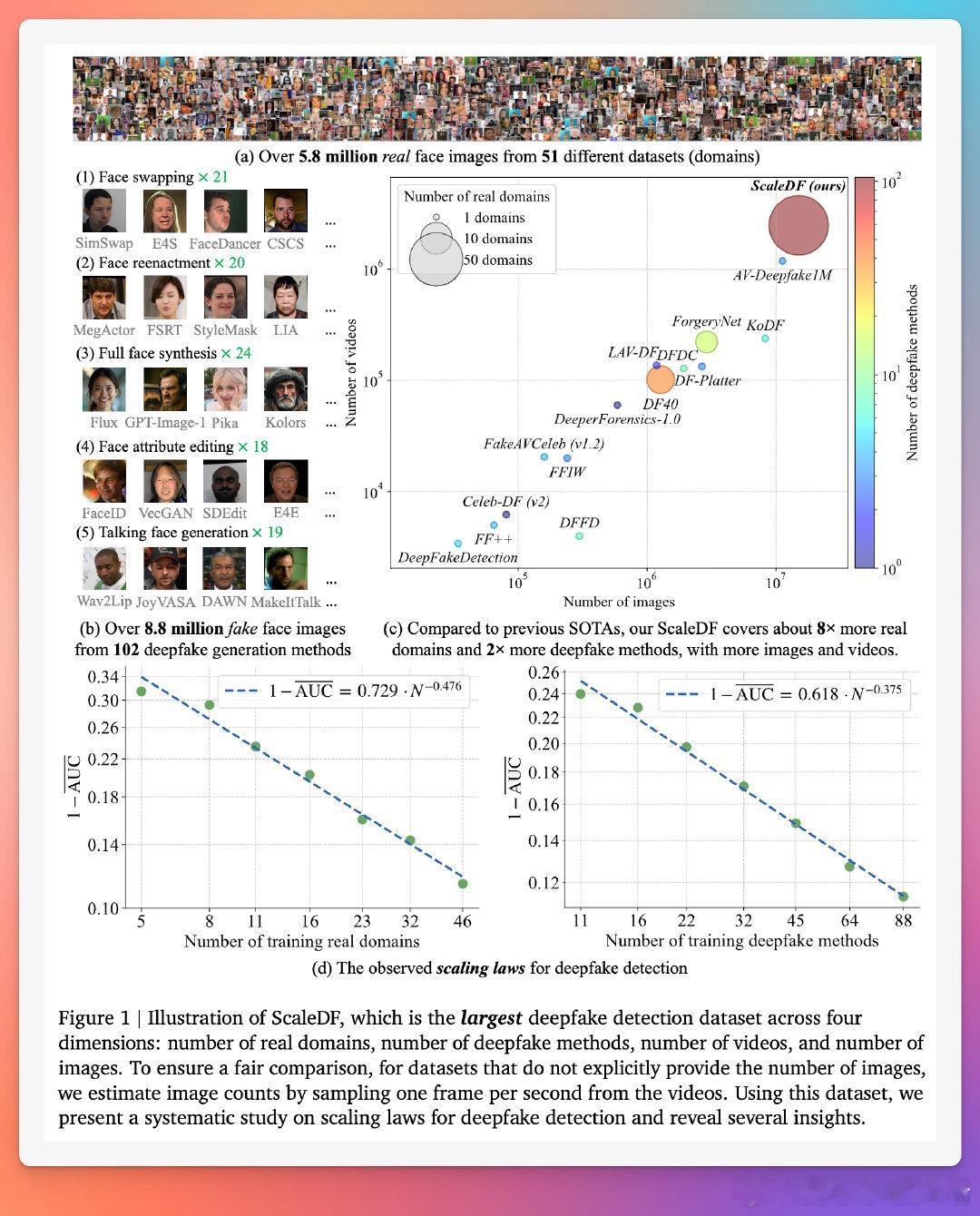
现有数据集规模小、多样性不足(如DF40仅6个真实领域、40种伪造方法),难以支撑规模研究。为此,我们 curation 出ScaleDF——领域内最大数据集,涵盖51个真实图像数据集(领域,约580万张图像)和102种深度伪造生成方法(约880万张假图像),总计超1400万张面部图像/视频帧。
- 真实数据收集原则:包容性。我们整合所有公开可用真实面部数据集,覆盖面部检测、识别、年龄估计、表情分析、语音识别、遮挡鲁棒、多光谱生物识别等10大任务。排除多数专为深度伪造设计的集(如FaceForensics++例外,因其广泛使用),避免过拟合。每个数据集仅随机采样部分图像(如VGGFace2从331万中取20万),确保多样性和平衡。测试时采用“跨领域”评估,选择鲜见于近期大面部集的领域。
- 伪造数据生成:五类102种方法。参考最新综述,将伪造方法分为面部交换(FS,21种)、面部重演(FR,20种)、全脸合成(FF,24种)、面部属性编辑(FE,18种)和说话面部生成(TF,19种)。覆盖主要架构:仿射映射、3D建模、VAE、GAN、扩散模型、流匹配和自回归模型。生成时,使用训练真实数据产生训练伪造样本,测试数据产生测试样本,实现“跨方法”评估。视频采样3帧/秒,转为图像训练(未来可扩展时序伪造)。
与现有数据集比较(表1),ScaleDF在真实领域(51 vs. DF40的6)、伪造方法(102 vs. 40)、视频数(90万+ vs. 10万+)和图像总量上领先8-5倍。这不仅支持规模定律研究,还为未来检测系统奠基。
规模定律观察:性能可预测的幂律衰减
我们将深度伪造检测视为二元分类,使用Vision Transformer (ViT-Base)作为骨干,在ScaleDF上训练,评估7个基准(DeepFakeDetection、Celeb-DF V2等),指标为平均AUC和EER。关键发现:模型性能随数据规模呈幂律关系,无饱和迹象,类似于LLM和图像分类的规模定律。
- 随真实领域数(N)扩展:采样5-46个领域训练,检测误差(1-AUC)呈幂律衰减:1-\overline{AUC} = A \cdot N^{-\alpha} (A=0.729, \alpha=0.476, R^2=0.982)。例如,从5个领域到46个,平均AUC从0.62升至0.89。预测:达AUC 0.95需约300个领域。这强调多样性而非单纯数量——更多领域捕捉真实面部变异(如光照、姿势、人口统计),提升泛化。
- 随伪造方法数(N)扩展:采样11-88种方法,类似幂律:1-\overline{AUC} = A \cdot N^{-\alpha} (A=0.618, \alpha=0.375, R^2=0.990)。AUC从0.76升至0.89。预测:达AUC 0.95需约700种方法。EER分析一致(幂律,R^2>0.98)。这证明,覆盖新兴方法(如GPT-Image-1扩散模型)是反制伪造的关键。
- 随训练图像数(N)扩展:固定46领域+88方法,采样比例1/4至1/1000,总图像从1400万降至1.4万,双饱和幂律:1-\overline{AUC} = c + K(N + N_0)^{-\gamma} (c=0.112, K=2.1\times10^4, N_0=1.34\times10^5, \gamma=0.915, R^2=0.999)。性能在10^7图像后渐饱和,表明同源数据增量有限。但若扩展领域/方法,饱和阈值将推移——数据多样性是上限。
- 模型规模扩展:ViT从小(21.7M参数)到大(630M),性能至303M饱和(AUC 0.90)。ScaleDF当前支持300M模型;未来更多多样数据可解锁更大模型。
这些定律非图像数量驱动(采样1/10图像仅微降性能0.01 AUC),而是多样性所致。思考:这将检测从试错艺术转为数据工程——预估资源,优先采集新领域/方法,应对伪造演化。
规模下的附加观察:实用洞见与局限
规模化实验揭示更多:
- 预训练作用:在大规模ScaleDF上,ImageNet、CLIP、SigLIP预训练性能相似(AUC差女),需采样缓解公平性;未涉时序伪造或水印(如SynthID)。
结语:数据中心范式与未来方向
ScaleDF与规模定律证明:通过预测关系,我们可构建更鲁棒检测系统,聚焦多样性而非海量同质数据。这激发数据中心方法,反制伪造“军备竞赛”。然而,规模非灵丹妙药——对全新伪造仍需算法突破,如从多方法中提炼通用伪造表示。我们呼吁社区利用ScaleDF探索这些前沿,推动生成AI安全。
原论文链接:arxiv.org/abs/2510.16320