[CL]《Dual-Head Reasoning Distillation: Improving Classifier Accuracy with Train-Time-Only Reasoning》J Xu, D Zhou, V Shukla, Y Yang... [Google] (2025)
Dual-Head Reasoning Distillation(DHRD)革新性地将推理负担从推理时转移到训练时,显著提升分类器准确率,同时保持推理速度极高。
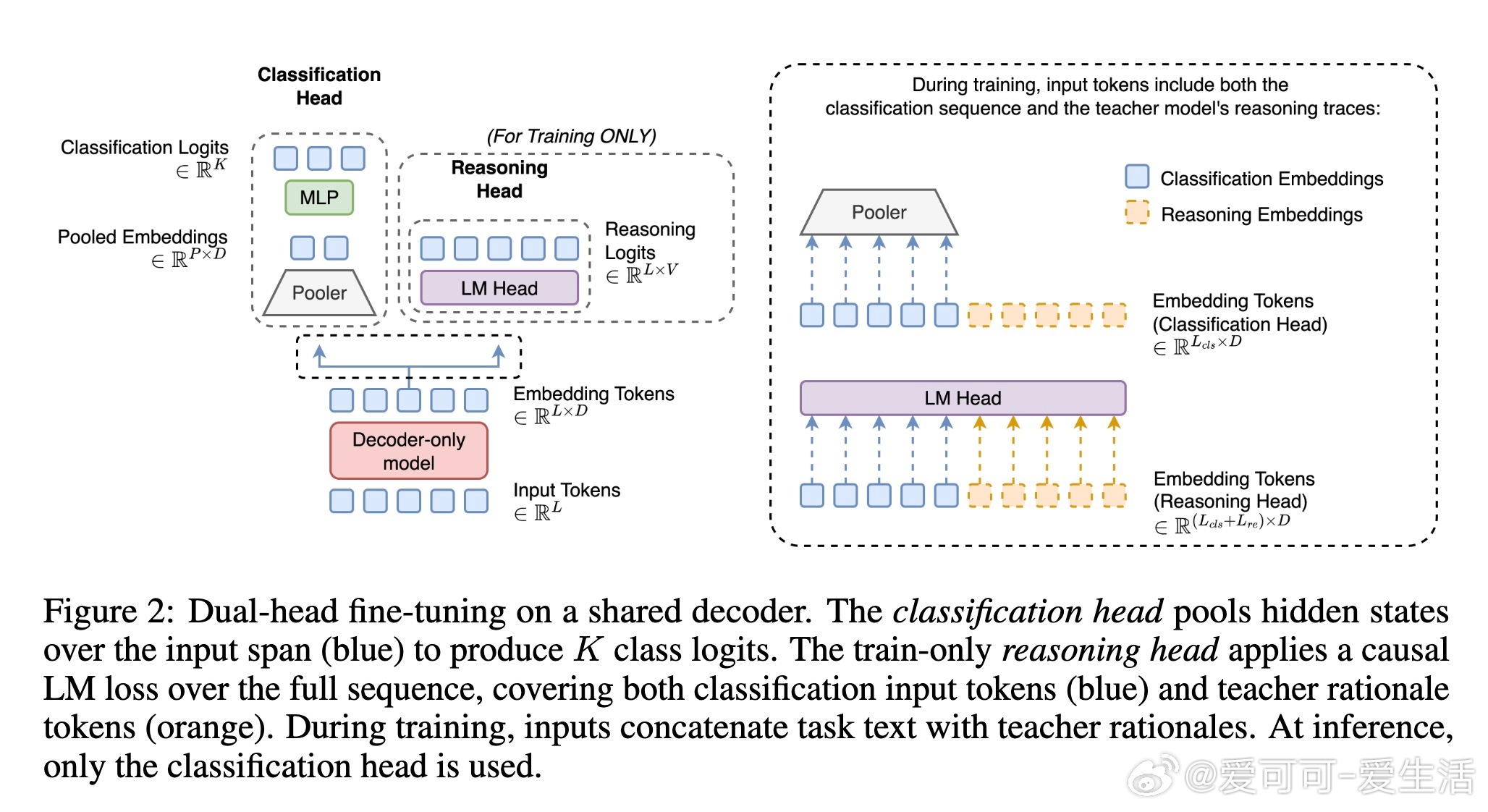
• 结构突破:在基础的decoder-only语言模型上,新增双头架构——一个用于训练和推理的池化分类头,另一个仅训练时启用的推理头监督教师模型生成的链式推理(rationale)。
• 损失设计:联合优化标签交叉熵和基于输入+推理文本的token级语言模型损失,强化模型对推理过程的理解而不增加推理负担。
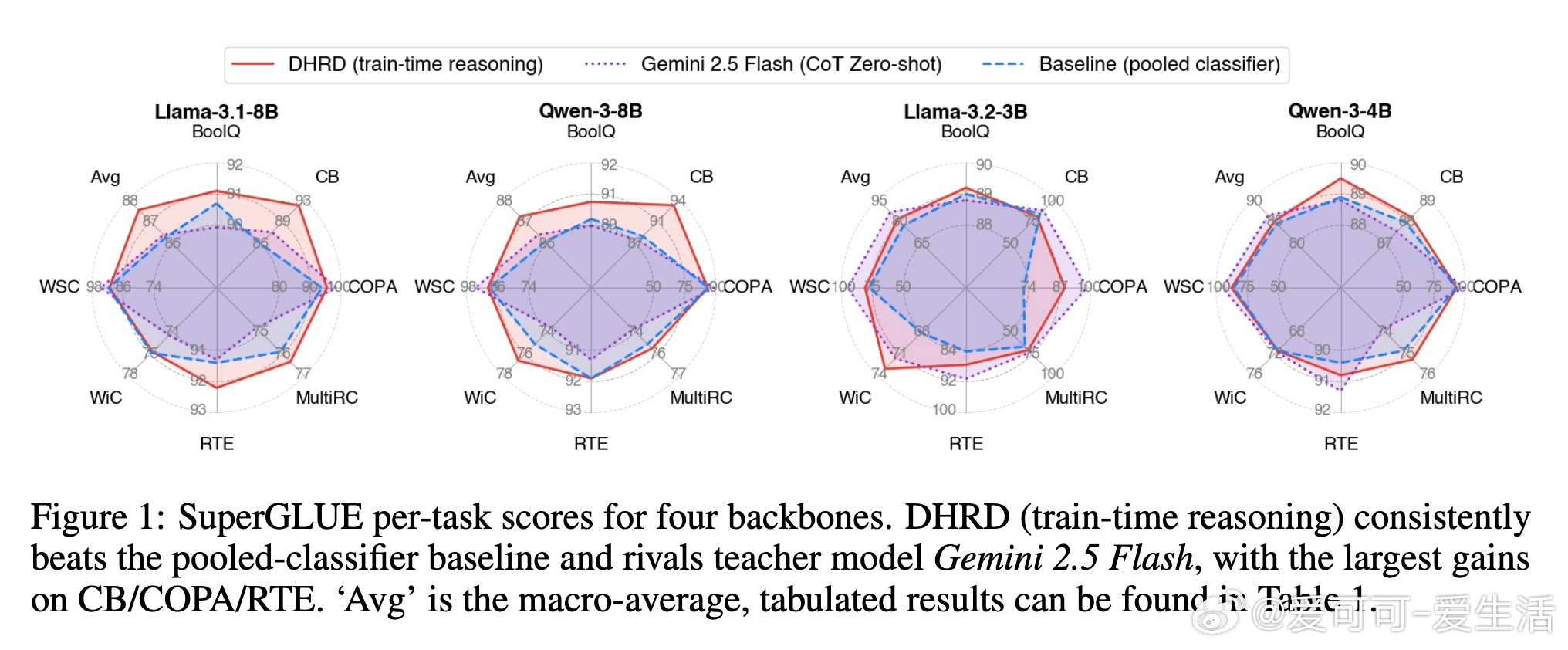
• 任务效果:在SuperGLUE七大任务上,DHRD对比传统池化分类器平均提升0.65%至5.47%,在蕴含关系与因果推理任务(CB、RTE、COPA)表现尤为突出。
• 推理效率:测试阶段仅启用分类头,避免生成推理文本,推理速度比传统Chain-of-Thought解码快96至142倍,适合高吞吐场景。
• 消融分析:性能提升依赖于输入、推理文本与标签的严格对齐,推理文本错位或缺失会显著降低准确率,表明推理监督非简单正则化。
• 训练细节:采用Gemini 2.5 Flash模型生成教师推理文本,结合LoRA微调,保证大模型在有限计算资源下稳健训练。
• 应用启示:通过训练时引入推理监督,模型在不牺牲速度的前提下学会“思考”,为知识密集型问答和安全审核等任务提供更精准的语义验证手段。
心得:
1. 推理能力无需推理时显式生成,训练时的隐式学习足以提升模型决策质量,打破了推理速度与准确率的传统权衡。
2. 对齐的推理文本是模型学习有效推理的关键,非对齐或缺失推理信号会导致性能大幅下降,强调了监督数据质量的重要性。
3. 双头结构在实现推理与分类两者兼顾的同时,保持模型结构简洁,便于大规模部署和快速推理,适合工业界应用。
了解更多🔗 arxiv.org/abs/2509.21487
自然语言处理 大规模语言模型 知识蒸馏 推理优化 机器学习 SuperGLUE