看了Andrej Karpathy的长篇访谈,对AI大模型的理解深入了不少
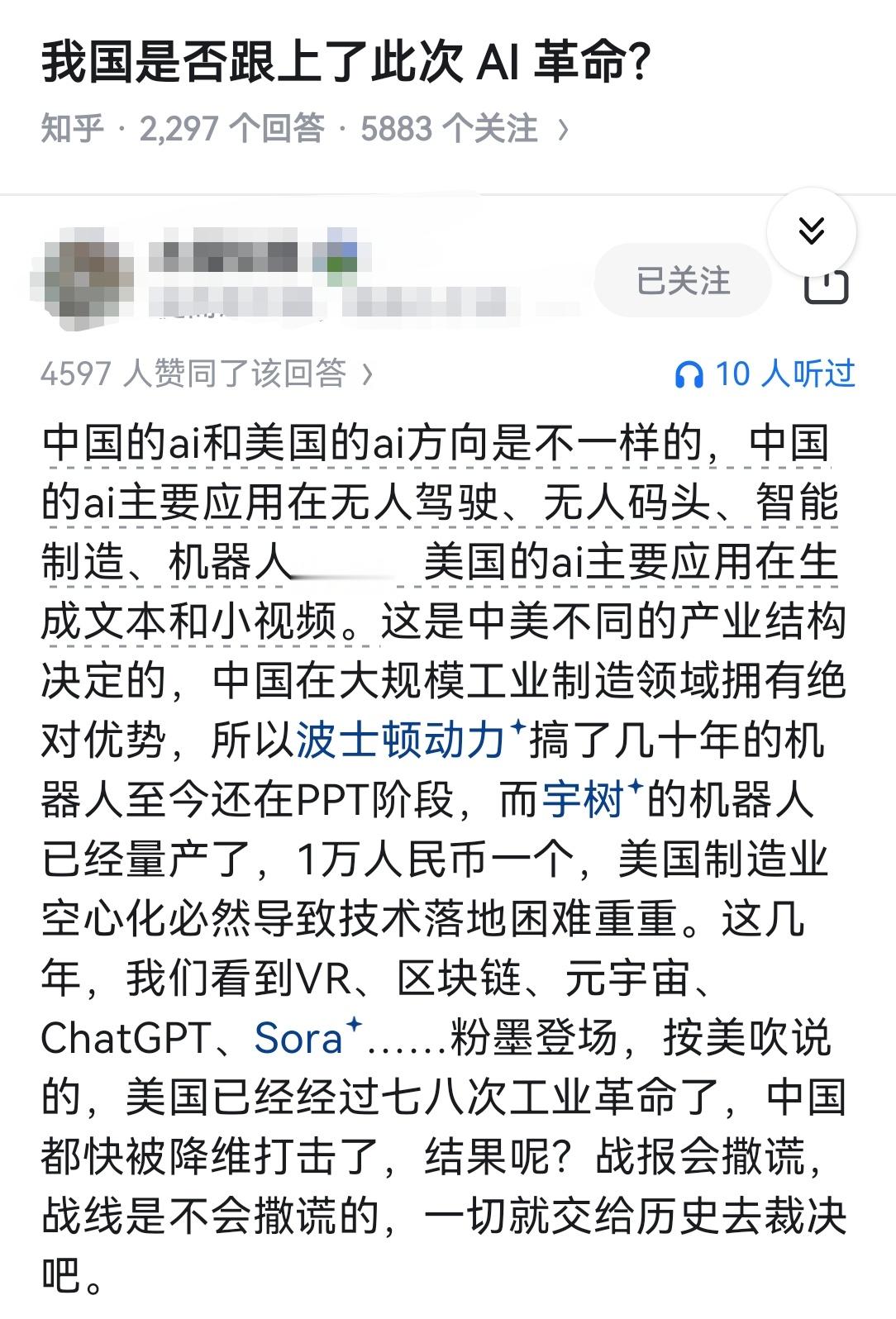
2022年末大模型刚出,大家都是懵逼的,国产大模型水平不足,第一年没怎么正经用。感觉到2024年初才成为我的生产力工具,搞学习查信息很有用。进入2025年中国大模型就更厉害了,日常使用,就能产生较深的理解。
Andrej Karpathy是OpenAI创始人之一,在特斯拉负责过AI研发,后来出来搞AI教育,经常发不错的评论。最近的长篇评论,聊得挺深了。主要感觉对于“学习”这个事,人类的理解加深了。
1. Agent还远不如实习生,没法干活
现在“智能体”Agent很流行,说是人让Agent干活,就不用招人了。但Agent和实习生比,缺点明显。我们招了人类实习生,一开始啥也不懂,手把手地教下,人就会了,就能帮我们干活了,牛逼的实习生还能主动学习。但是,Agent不是,最大的毛病是没有“记住”这个功能。因为Agent的基础是一堆固定的神经网络系数,你和它聊天,它能短期记在“内存”里,似乎学会了点啥,但过阵子内存状态更新就忘了,没有“持续学习能力”。
我们和实习生聊,会知道新人是真掌握的做事的技术,可以放心了。但对于AI Agent,即使DEMO很好,也没法放心。你让它生成一堆代码,比人快无数倍,但就是没法放心,不能让Agent“负责”一个模块、一个事。Karpathy认为要十年,Agent才能解决这个问题。“十年”意思就是“有希望,但非常困难”。
2. 强化学习的缺点
这不是说强化学习RL不好,其它办法还不如RL,所以RL是研究热点,不断有成果出来。只是人们用多了大模型以后,要求提高了,就对强化学习的缺点感觉“很糟糕”。这还是回到“学习”的本质上,强化学习,是一种好的学习方法么?
从人类的标准来看,对于高层次的学习者来说,学习是一个“透彻学通”的过程。干活成功的原理是什么,过程中哪些是关键的,那些其实是无效的,为什么最后对了。也就是说,人类学习的不是答案,而是“方法论”。有个词叫“元学习”,人类高手学习的是,“怎么学习”。高手确实很多技术领域都能融汇贯通地学会,低手就啥都不理解,只会死板地模仿。低手不知道高手在琢磨些什么,而这正是AI大模型的状态。
人类高手的学习思维包括反思、评审、记忆、合成数据、元学习,这些AI大模型都不太会。那AI大模型的学习是怎么回事?它就是蒙,蒙它几百上千次。有一次蒙对了,就觉得这是对的“路子”,接受改进。最后不停地蒙,在海量算力加持下凑巧弄出了一些系数结构,似乎学会了。但这种暴力学习方法,有很大缺陷,它只是表面上让输出对了,内部其实根本没有懂。大模型对十几万种token建立了“关联”,但这种结构是有问题的,能干对不少事,但也会干错不少事。是蒙出来的理解,没有透彻的理解。
3. 记忆与认知
AI系数极多,能记得非常多的token和关联,远比人类多。但从学习与思考的角度看,智力水平远不如人,认知远不如人。它显得很厉害,只不过是因为记下的东西多,人记不住。
人的优点是,记不住这么多细节,但反而注意力集中地关注“可泛化”的模式,抽象理解知识结构。高级学者在自己擅长的知识体系里,不一定记得住很多数据、定义,但有透彻的理解,搜索或者问AI这些细节就行了,结合自己的“认知核心”就能输出很好的知识。人类忘了细节,记住了精华、规律,看见了森林而不是树木。就像张三丰教张无忌太极拳,忘光了反而是学会了。
AI大模型相反,记住了无数细节,完美记忆。就像记了无数笔记的学生,但知识整理能力不佳。大模型不会丢弃噪声、提炼概念、真正抽象。有时它显得很懂概念、抽象,只不过是记忆人类的说法。
因此,Karpathy提出了颠覆性的设想,未来最强大的AI只要10亿个系数。现在大模型上万亿个系数,绝大多数都是在处理作用不大的“脏数据”,是人类在互联网上胡乱输出的结果。而10亿个精华系数,就可以承载人类关于“思考”的才能,代表人类的“认知”能力,而非记忆。这样,这10亿个系数,就会成为“有方法论的哲学家”,可以和优秀人类学者一样去学习理解各领域的数据与细节。
4. AGI不会一夜出现改变世界,AI的作用是缓慢的
美国那边炒作的是AGI(或者ASI等名称)出来以后,会一夜之间改变世界,“奇点爆炸”。这种突变式想法,实际并不自然。人类伟大的发明创造都不是如此,而是慢慢扩散、普及、被理解接受,对GDP增长的作用是缓慢的,但持续让GDP曲线向上。
因此,美国这边冲击AGI很可能是幻想,不符合人类技术发展规律(其实已经不怎么吹了,2026就出来、两三年就成功等说法没了)。AI大模型提供了一些能力,虽然远不如AGI理想,但能够真实地应用,改变世界。这需要很多行业与公司在本领域积极使用引入AI,而不是等待万能牛逼AI出来。