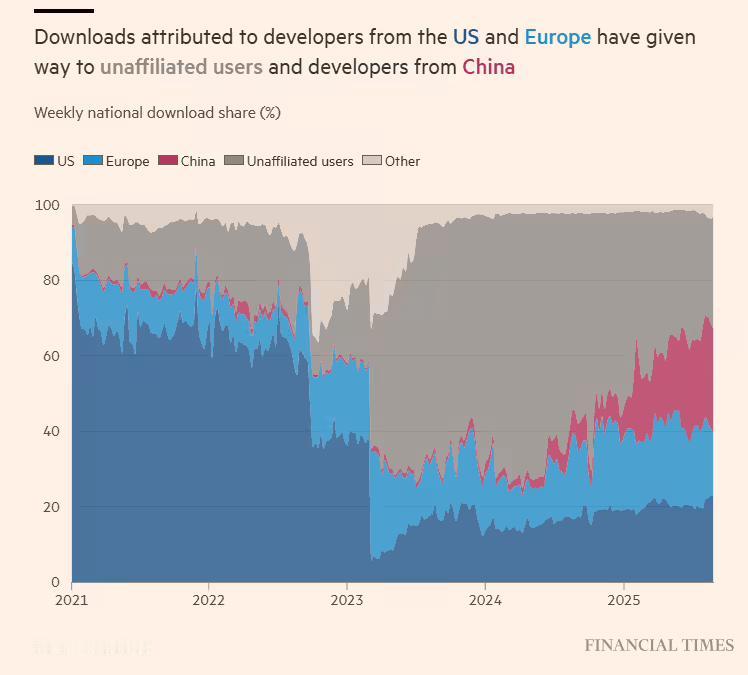
谷歌的前CEO施密特和中国人聊天时,一直认为中国的大模型落后美国2~3年,突然他发现,中国已经有两个强大的模型,水平超过美国,而且是开源的。 这话他不是第一次说,此前公开演讲中,他多次强调美国在闭源大模型领域的领先优势,觉得中国还在追赶阶段。 这种认知差距,并不是偶然,而是两种截然不同的认知与价值观碰撞的结果。施密特和美国的决策者们坚持认为中国在大模型和人工智能领域还在追赶阶段,始终低估了中国在技术迭代、创新以及开源模式上的爆发力。 可当现场有人打开电脑,给他展示两款中国开源大模型的实测数据和应用案例时,施密特脸上的自信慢慢变成了惊讶,盯着屏幕反复确认:“这些都是真的?你们竟然把这么强的模型开源了?” 施密特最先看到的是阿里的 Qwen 系列开源模型,这款被称为 “全球首个混合推理模型” 的产品,光是核心参数就让他意外,采用 MoE 架构设计,总参数量达到 2350 亿,可实际运行时激活的参数仅需 220 亿,这种 “按需调用” 的设计让效率大幅提升。 现场演示中,工作人员用 4 张普通的 H20 GPU 就启动了满血版模型,要知道,美国同类级别的闭源模型至少需要 8 张英伟达 H100 高端芯片才能流畅运行。 更让施密特吃惊的是性能测试,在 AIME25 数学推理评测中,Qwen 拿到 81.5 分,超过了美国主流闭源模型的成绩,尤其是几何证明题和复杂应用题,准确率比 OpenAI 的 o1 还高出 2.8 个百分点。 更关键的是 Qwen 的开源生态规模,工作人员展示的数据显示,这款模型在 HuggingFace 平台的下载量占比已经达到 30%,超越了美国的 Llama 系列,成为全球下载量第一的开源模型生态。衍生出来的各类定制模型超过 10 万个,覆盖了从手机端到企业级的全场景需求。 紧接着展示的智谱 AI GLM-4.5,同样颠覆了施密特对中国大模型的认知。这款模型最突出的亮点是首创的 GUI Agent 跨平台操作能力,现场工作人员让它自主打开浏览器,搜索特定话题,然后整合信息生成一份详细的旅游攻略,整个过程完全自动化,不需要人工干预。 在数学推理和代码生成领域,GLM-4.5 的表现也不逊色于美国顶尖闭源模型,尤其是 “边想边干” 的任务拆解模式,处理采购规划、财务报账这类复杂流程时,能把时间缩短 50%。 施密特特别关注到 GLM-4.5 的纯前端视觉感知技术,它不需要依赖额外的 API 接口,就能直接理解图像界面的内容,比如识别 PDF 里的表格数据、解读网页上的图表信息,这种能力在之前美国的开源模型中是很少见的。 更让他意外的是模型的合规性适配,在金融、政务这些高要求场景中,GLM-4.5 能精准把控风险,生成的法律文书、审批文件准确率极高,已经被不少政企单位采用。 交流中,施密特还了解到,这两款开源模型的训练成本远低于美国闭源模型。Qwen 的大规模训练成本仅相当于谷歌 Gemini 的 13.8%,而 GLM-4.5 通过优化算法,把复杂任务的执行成本压低到了美国同类模型的三分之一。 更重要的是,它们都能适配中国的昇腾等国产芯片,摆脱了对英伟达高端芯片的依赖,这一点让一直关注算力瓶颈的施密特十分赞赏。 斯坦福大学 2025 年发布的 AI 指数报告显示,中美顶级模型的综合性能差距已经从 2023 年的 20% 缩小到 0.3%,而在数学推理、中文适配这些细分领域,中国开源模型已经实现了反超。 现场有人告诉施密特,中国的开源大模型生态正在快速壮大,2025 年中国在全球大模型开源贡献度中占比达到 18.7%,如果包含工具类 AI,贡献度接近 30%。 像 Qwen 和 GLM-4.5 这样的模型,不仅向全球开发者开放代码,还提供详细的技术文档和部署教程,吸引了大量海外开发者参与共建。不少国外企业都在基于这些中国开源模型做二次开发,应用到本地的教育、医疗、商务等场景中。 原本以为中国大模型还在追赶的施密特,在看完所有演示后坦言:“我之前的判断太片面了,没想到中国在开源大模型领域已经走到了前面。” 他拿起手机拍下了模型的测试数据,忍不住和身边的助手讨论:“这种开源策略太聪明了,既能快速迭代技术,又能构建全球生态,美国的闭源模式可能要面临挑战了。” 这场交流打破了施密特对中国大模型的固有认知,也让在场的人感受到,中美 AI 竞争已经进入了新的阶段,不再是单一维度的领先,而是各有优势的差异化发展。 所以现在的局面,其实不是“中美差两三年”,而是“美国人心理上落后两三年”,现实已经摆在眼前,中国远远落后美国的时代被终结了。 信源:观察者网





大神父王喇嘛
放心,这两个再强,也还用的是transformer 架构,你们openai,google这些闭源的说不定早就下一代了