[CL]《End-to-End Context Compression at Scale》A Li, S McLeish, H Chen, N Kalra… [New York University & University of Maryland & Princeton University] (2026)
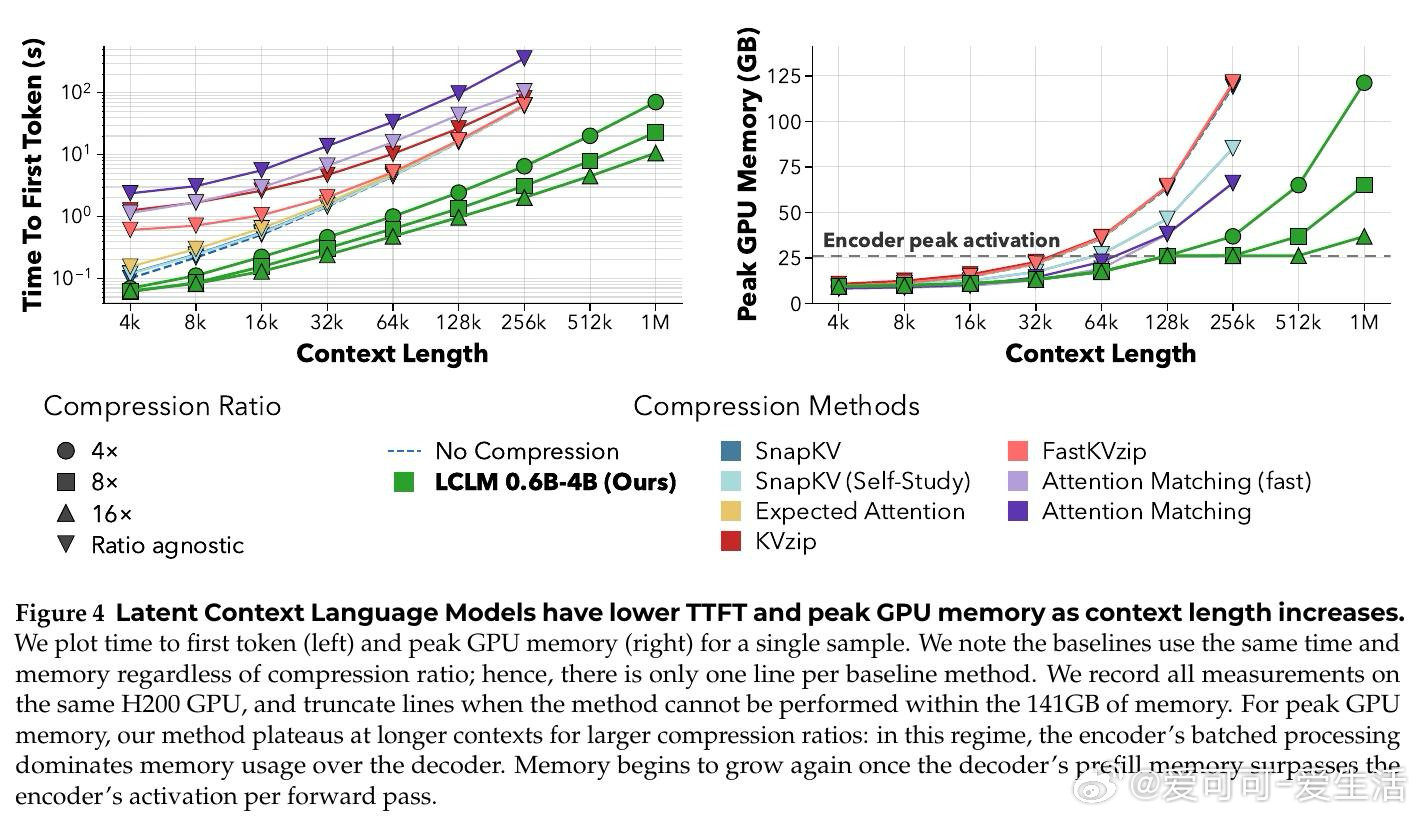
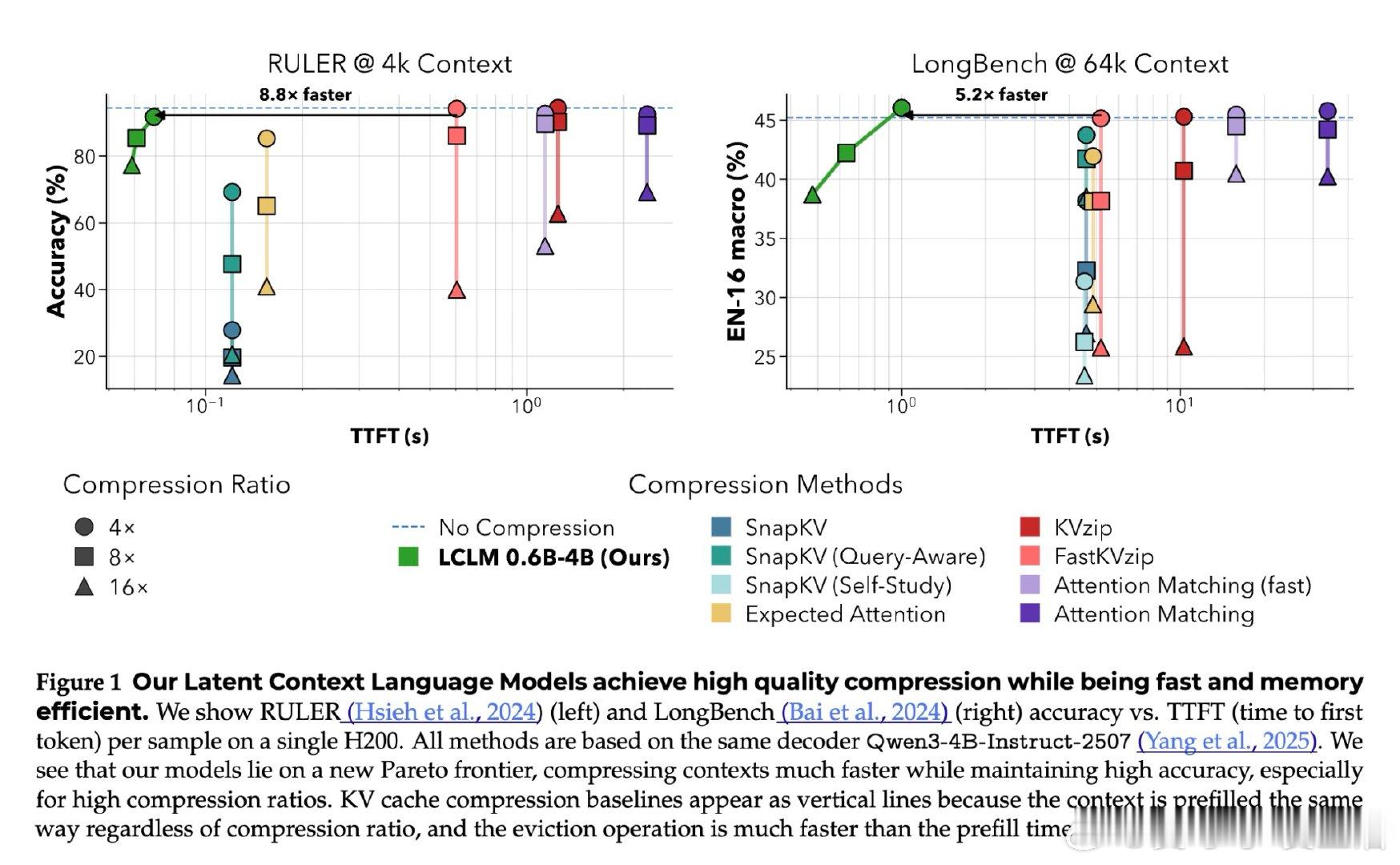
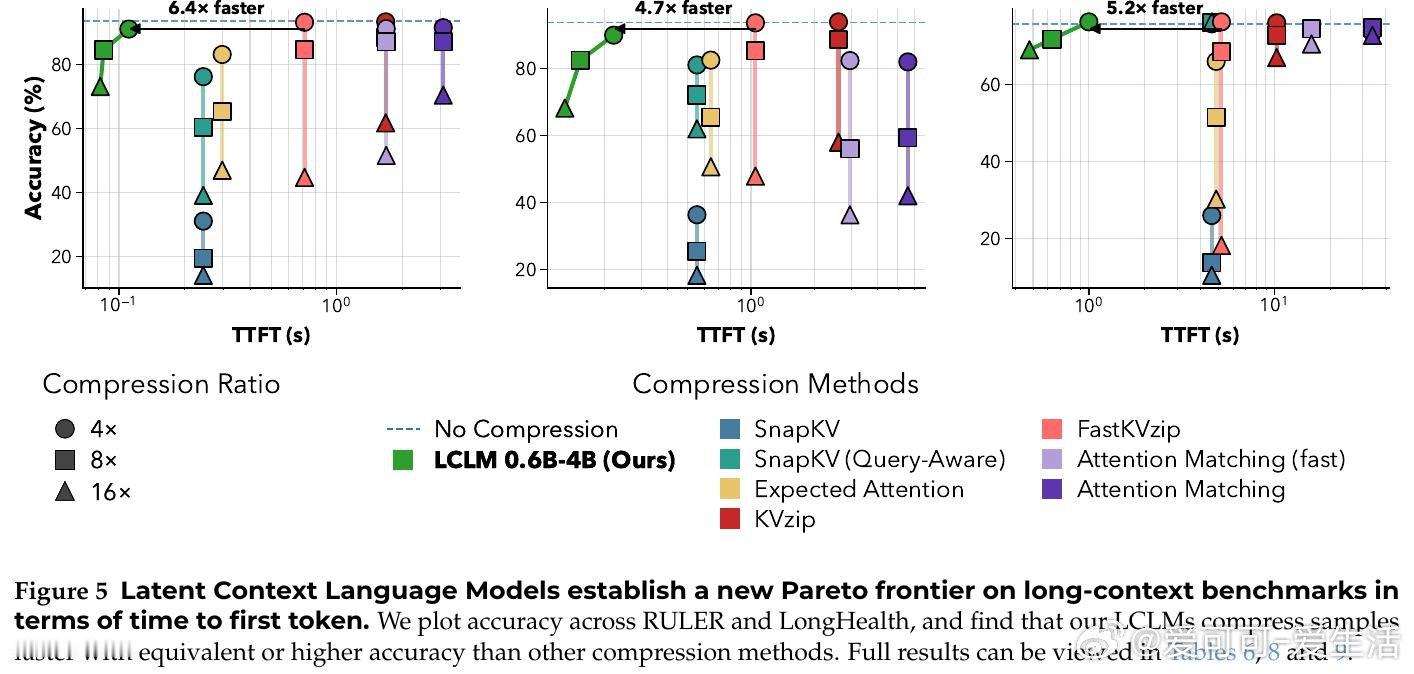
在长上下文推理中,KV Cache 会随文本长度线性膨胀。过去压缩方法受困于先读完整上下文、再删缓存,本质原因是压缩发生在模型已经付出内存代价之后。
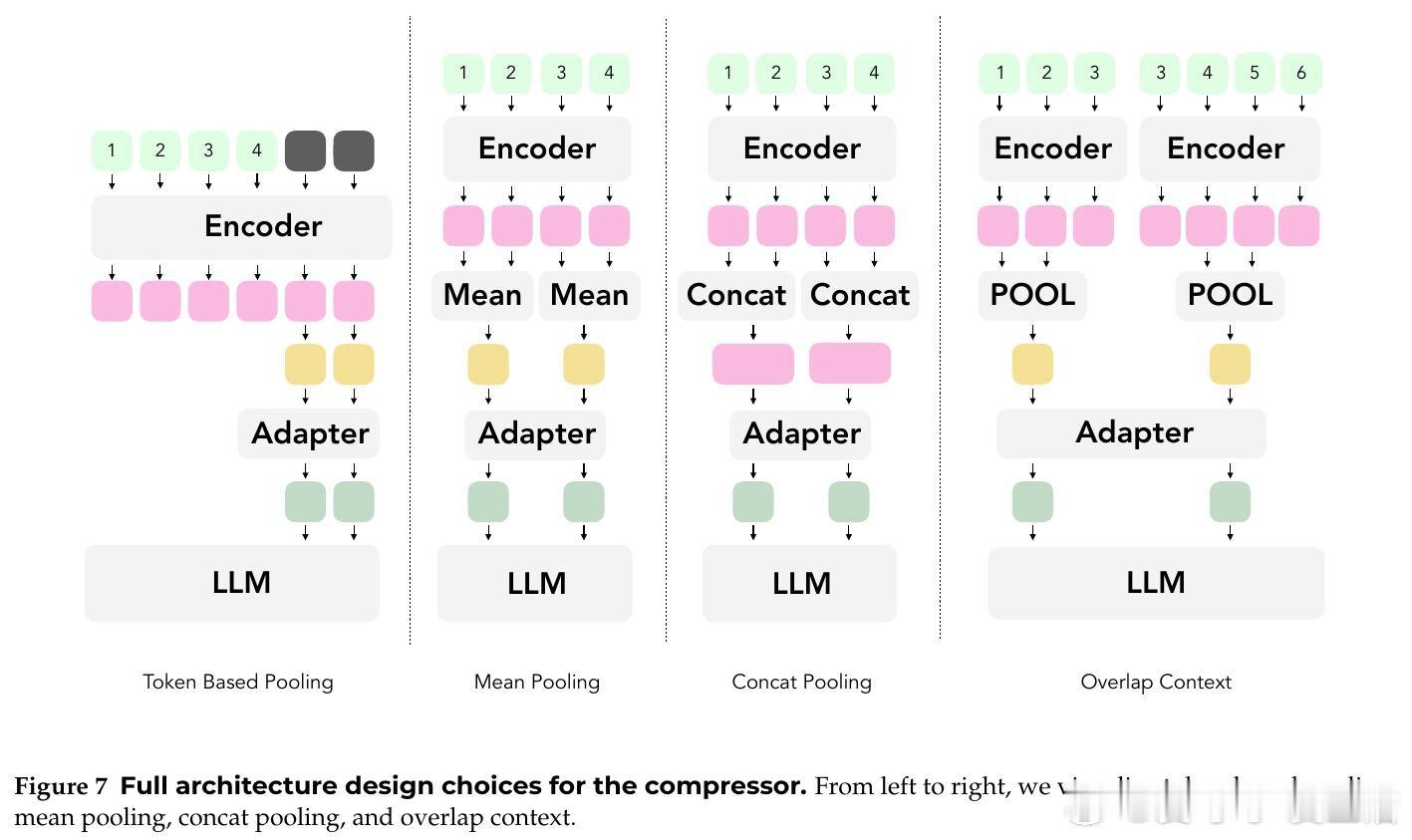
本文的核心洞见是:把长文本重新看作可学习的潜在记忆。由此,用编码器把多枚原始 token 压成少量软 token,再交给解码器读取,使压缩发生在推理前。
这项工作真正留下的遗产是把上下文压缩从缓存修补推向端到端建模。它打开的新门是百万级上下文代理可先粗读再展开细节,但门槛是压缩仍会损失精确信息。
arxiv.org/abs/2606.09659 机器学习 人工智能 论文 AI创造营