前两天跟一个做数据中台的朋友聊,他吐槽最近产品一直在催埋点排期,但方案还没出。
做数据埋点整条链路,主要在于协同流程很长。
产品提需求,需求要翻译成事件定义,埋点方案定下来还要前后端排期写代码,代码写完要测试环境验证,每一步都涉及不同角色参与。
我说,如果整条链路这么长,为什么不直接把中间那些翻译、转换、比对的环节,全部交给 Agent 自动完成呢?
他说他也想,但还没找到合适的方案。
我最近看到,之前给大家分享过的ThinkingAI,他们的Agentic Engine 刚上线了一个数据采集 Agent,核心解决的就是产品埋点和数据接入这条工程链路的问题。
我去试了一下,跑了一遍完整流程,还蛮有意思的。所以今天很想跟大家聊一下,现在的Agent,在数据埋点上已经走到哪一步了?
1我以一个游戏场景为例,来实际测试一下。
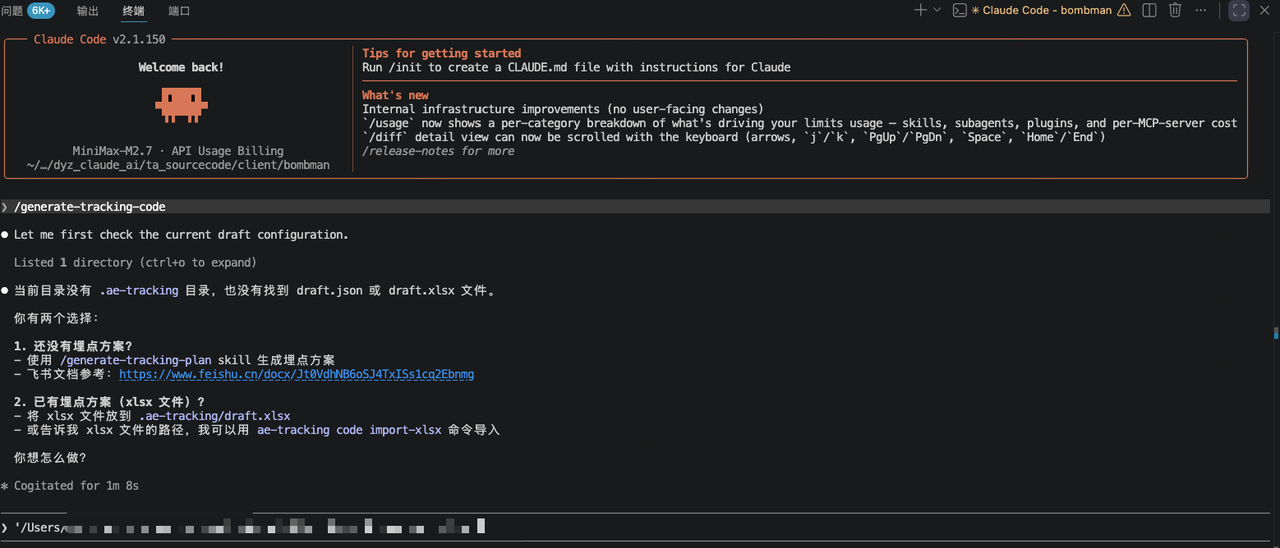
第一步,需求输入。我在对话框里用自然语言描述需求,大概就是一个抽卡功能的埋点需求,包括进入卡池页面、点击十连抽、展示抽卡结果这些行为。
Agent 大概5分钟就给我生成了一份完整的埋点方案:事件名、属性定义、触发时机、必填字段、数据类型,一次成型。每个属性的类型和含义都标注得很清楚,都是按照工程标准来的。
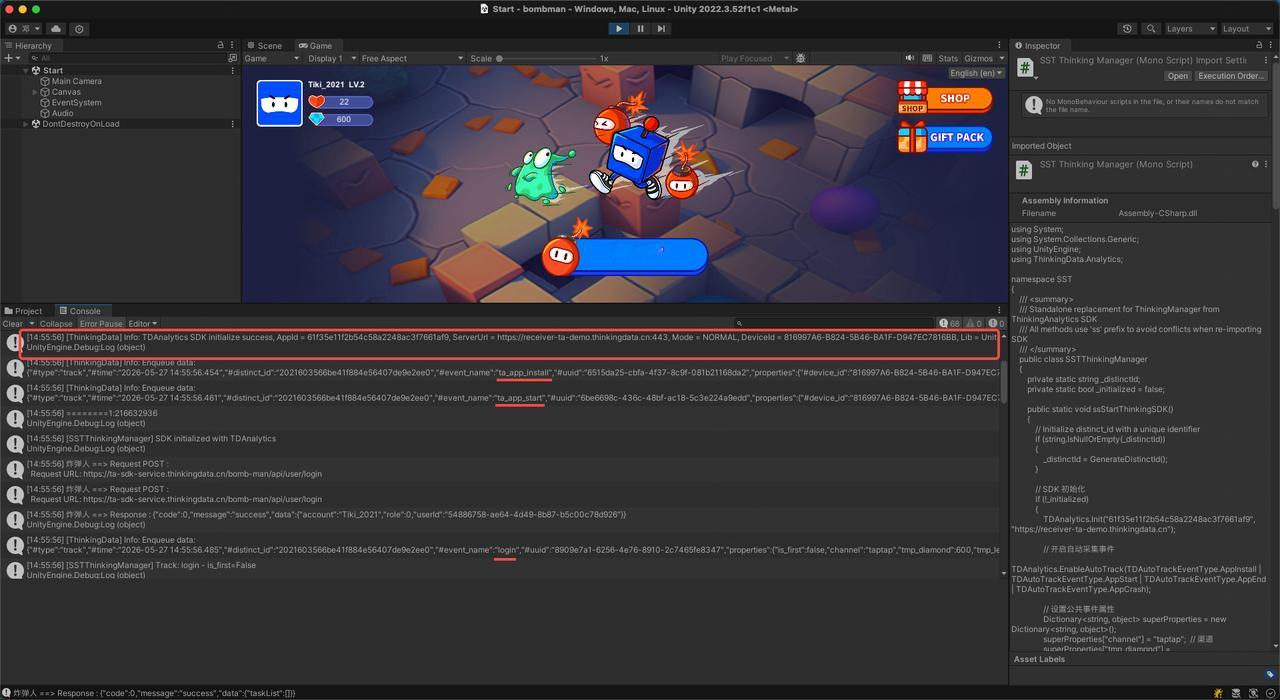
第二步,方案确认之后,通过 CLI 工具一键生成多端 SDK 代码,iOS、Android、Web、小程序、Unity 都支持。
事件名、属性名跟方案完全一致,还带注释。
第三步,研发同学把代码接进去之后,最关键的一步是验证。
可以先在测试环境里手动触发一遍埋点流程,比如进卡池、点十连抽、看结果。Agent 会自动比对上报数据和埋点方案,字段类型不匹配、必填字段缺失、事件命名不一致,都会实时报出来。
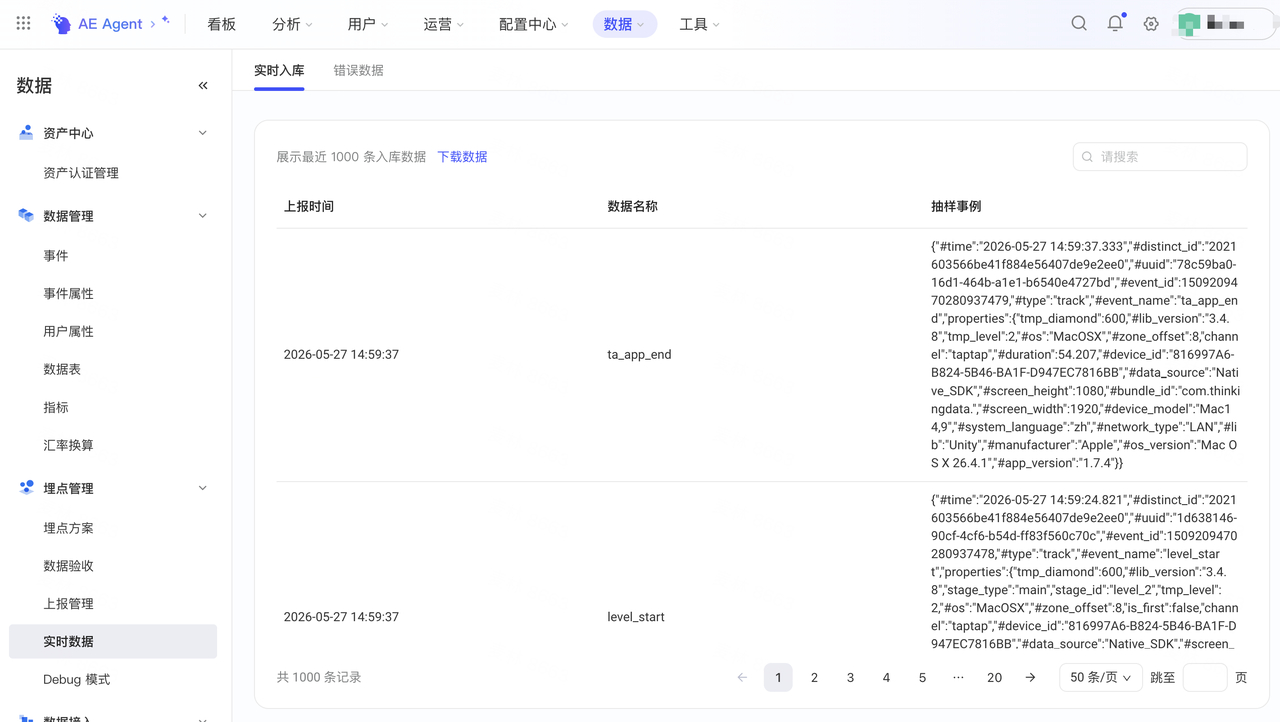
第四步,在后台看实时数据,每一次抽卡行为的完整属性都在,字段类型、命名规范、必填项全部符合方案。
确认没问题,直接上线。从需求输入到验证完成,2小时跑完,但传统方式至少2周,效率差距是很明显的。
2可能有人会问:这跟我直接用其他大模型写埋点方案有什么区别?
其实区别还是很大的。我之前也试过用通用大模型来写埋点方案,它确实能理解你的需求,也能输出一段看起来还可以的方案描述,但它不懂你的业务,不知道你们团队的埋点规范是什么。
但数据采集 Agent 不是帮你做某一步,而是把方案设计、代码生成、验证上线这三步串成了一个闭环。
而且,它输出的是标准化的埋点规范文件,可以被 Claude Code、Codex 这些本地 AI 编程工具直接消费,生成的代码符合 SDK 规范,上报之后还能自动校验字段一致性。
另外它提供 npm 安装和 CLI 工具的形态,上手成本很低,在终端里装好就能用,可以直接嵌入你现有的研发流程里。
所以说,Agent 要真正变成生产力,至少要做到三件事:工具链形态可装可跑、产物结构可被工程消费、能跟现有研发流程连通。
3那它比较适合什么样的团队呢?首先肯定是那种新功能上线频繁、埋点需求多、但数据团队人手不够的团队。
比如,产品一个月迭代三四个版本,每个版本都有新的埋点需求,但数据团队就那么几个人,根本排不过来,这种团队提效肯定是最明显的。
其次是那种经常出现埋点失误的团队,比如字段名写错了、类型传反了。但Agent 把这些环节自动化了,出错的概率自然就低了。
另外我还注意到,ThinkingAI 的 Agentic Engine 下面不只有数据采集 Agent,还有数据分析 Agent、智能运营 Agent、A/B 实验 Agent。
每个 Agent 输出的都是标准化产物,上游 Agent 的输出可以被下游 Agent 直接接入。如果整个链路跑通,从数据采集到数据分析到运营决策,理论上可以形成一条自动化的工作流。
4当然,理论归理论,实际跑起来效果怎么样,还需要更多场景验证。从我这次的体感来看,这条链路确实是能跑通的。
我比较期待的是ThinkingAI 6月5日他们的直播实战演示,说是会用真实产品跑一遍真实流程。如果你也对这个方向感兴趣,到时候可以去看看,搜索 Agentic Engine 就能找到。
我自己是打算持续关注的,因为在我看来,谁能先把数据链路的效率提上去,谁就能在产品迭代的速度上拉开差距。
埋点这件事,可能真的到了该被重新想一想的时候了。