我的单3090显卡在llama.cpp的256K上下文跑出51 token/s: 1.把上下文拉到Qwen3.6-27B的256K极限了,可惜到不了1M。跑出50多token/s,已经非常优秀了,对单卡3090来说越来越香了。 2.最新版本llama.cpp的b330分支,前前后后有多项提升和优化,尽快更新。 3.我的配置RTX3090显存24G+32G运存+llama.cpp(b330)+win11+cuda13.1 4.单卡本地中等模型非常适合和均衡了
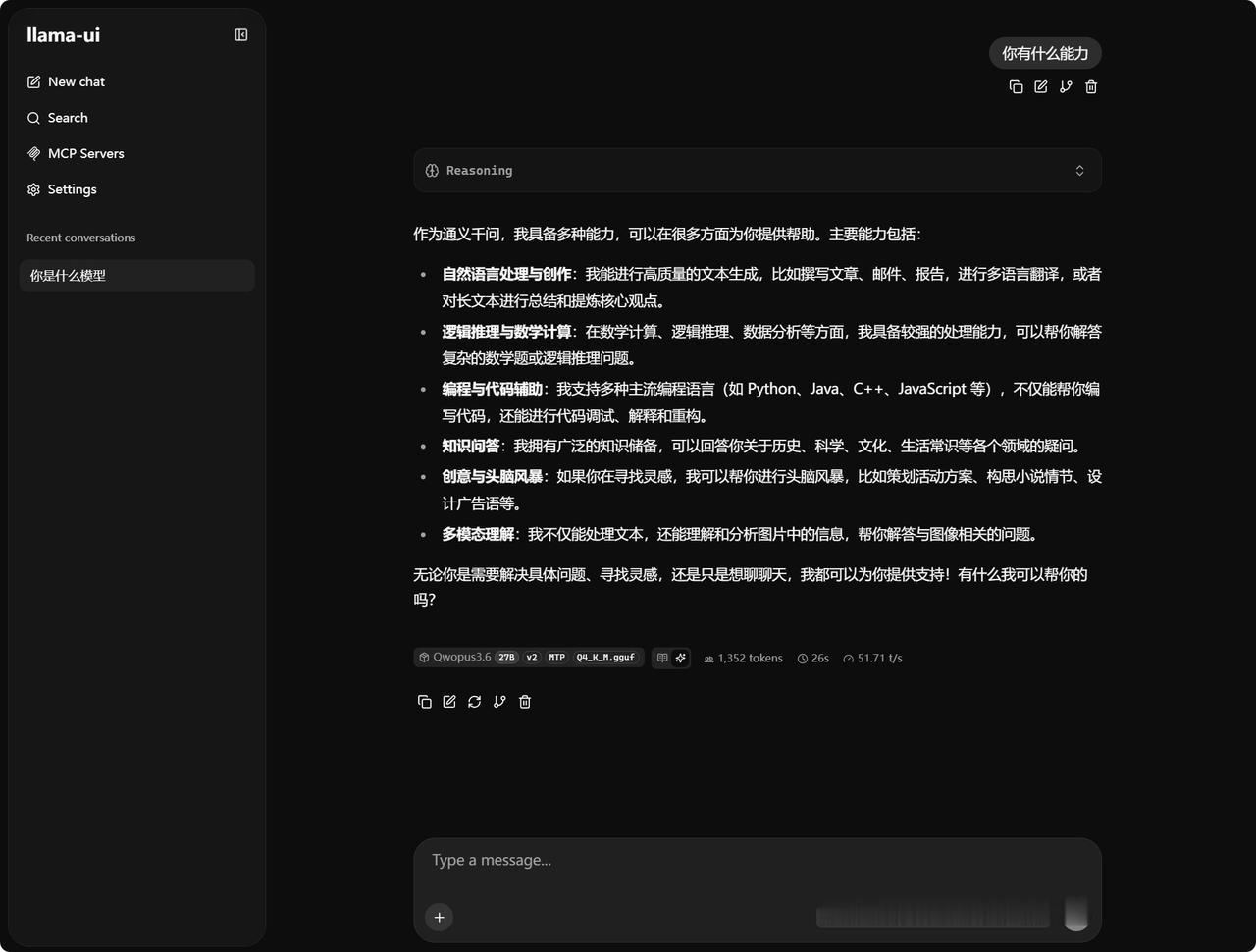
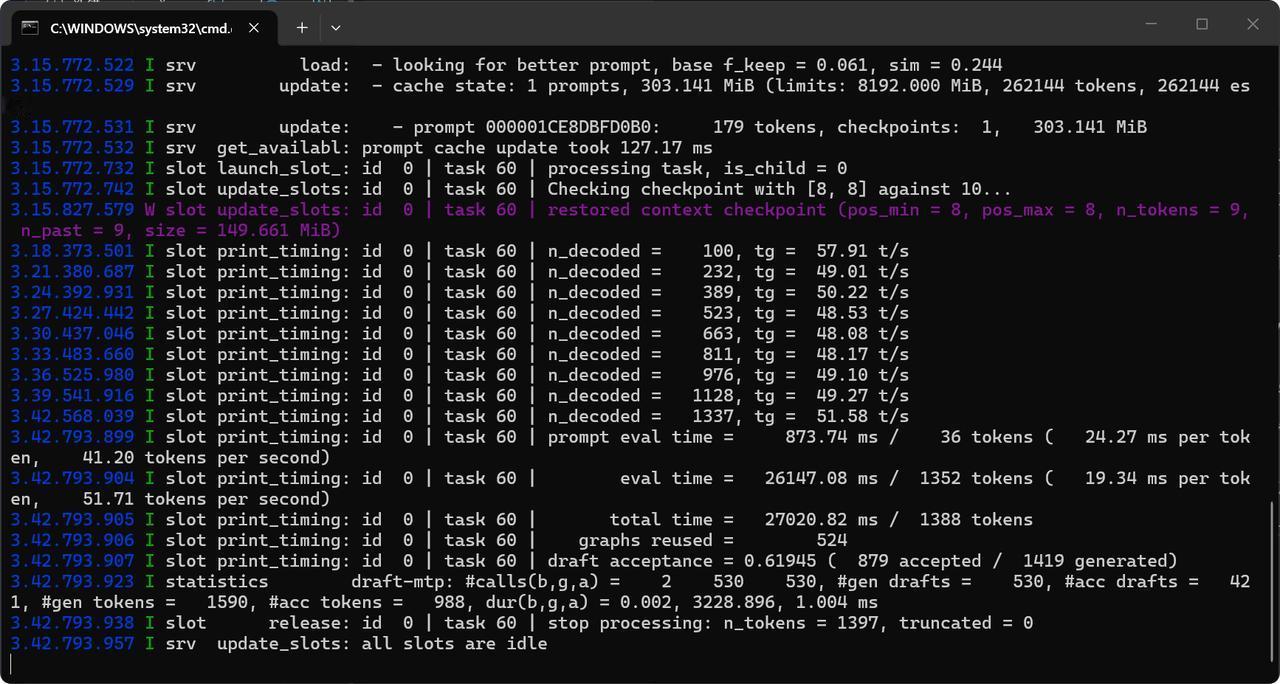
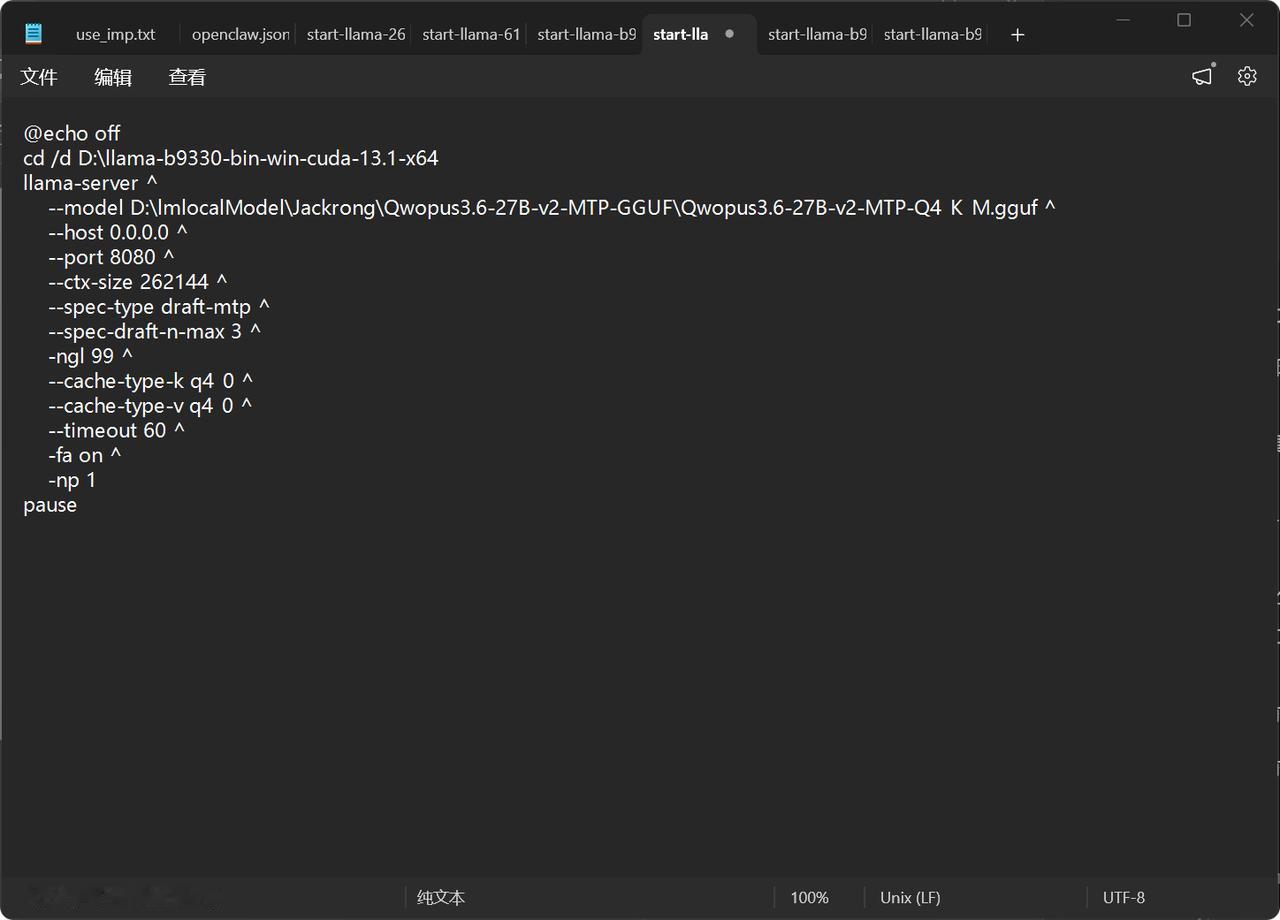
我的单3090显卡在llama.cpp的256K上下文跑出51 token/s: 1.把上下文拉到Qwen3.6-27B的256K极限了,可惜到不了1M。跑出50多token/s,已经非常优秀了,对单卡3090来说越来越香了。 2.最新版本llama.cpp的b330分支,前前后后有多项提升和优化,尽快更新。 3.我的配置RTX3090显存24G+32G运存+llama.cpp(b330)+win11+cuda13.1 4.单卡本地中等模型非常适合和均衡了
猜你喜欢
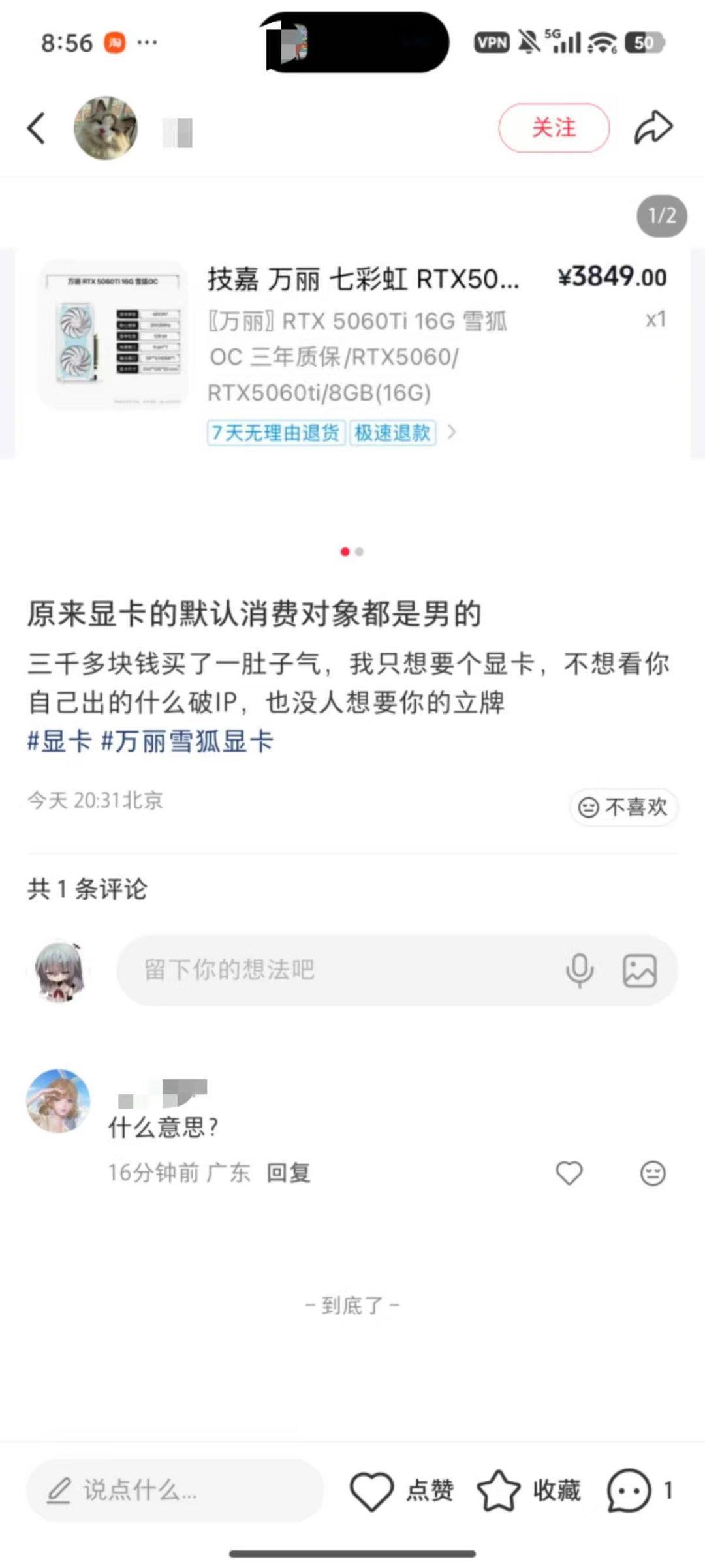
【5评论】【2点赞】

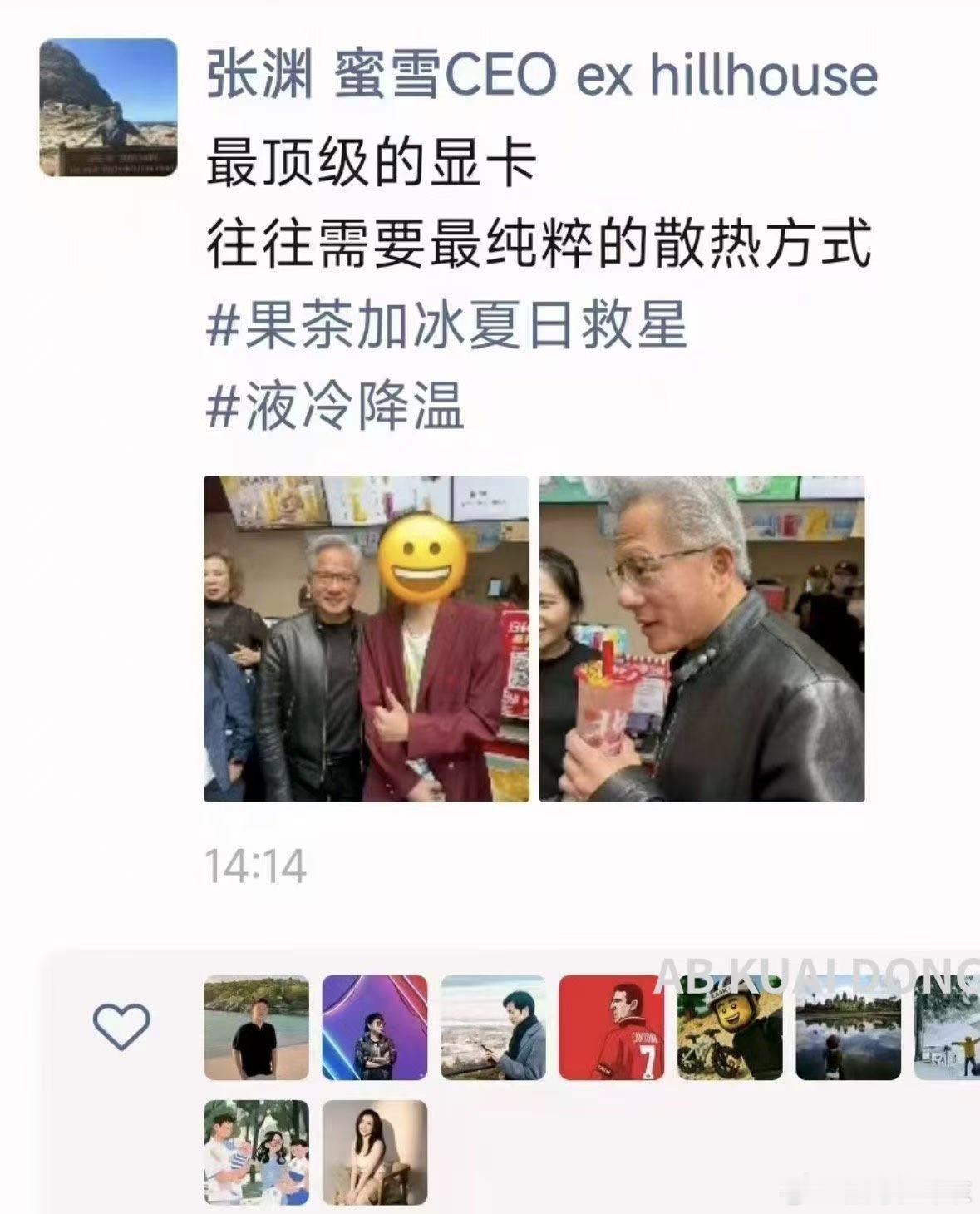
【1评论】【1点赞】
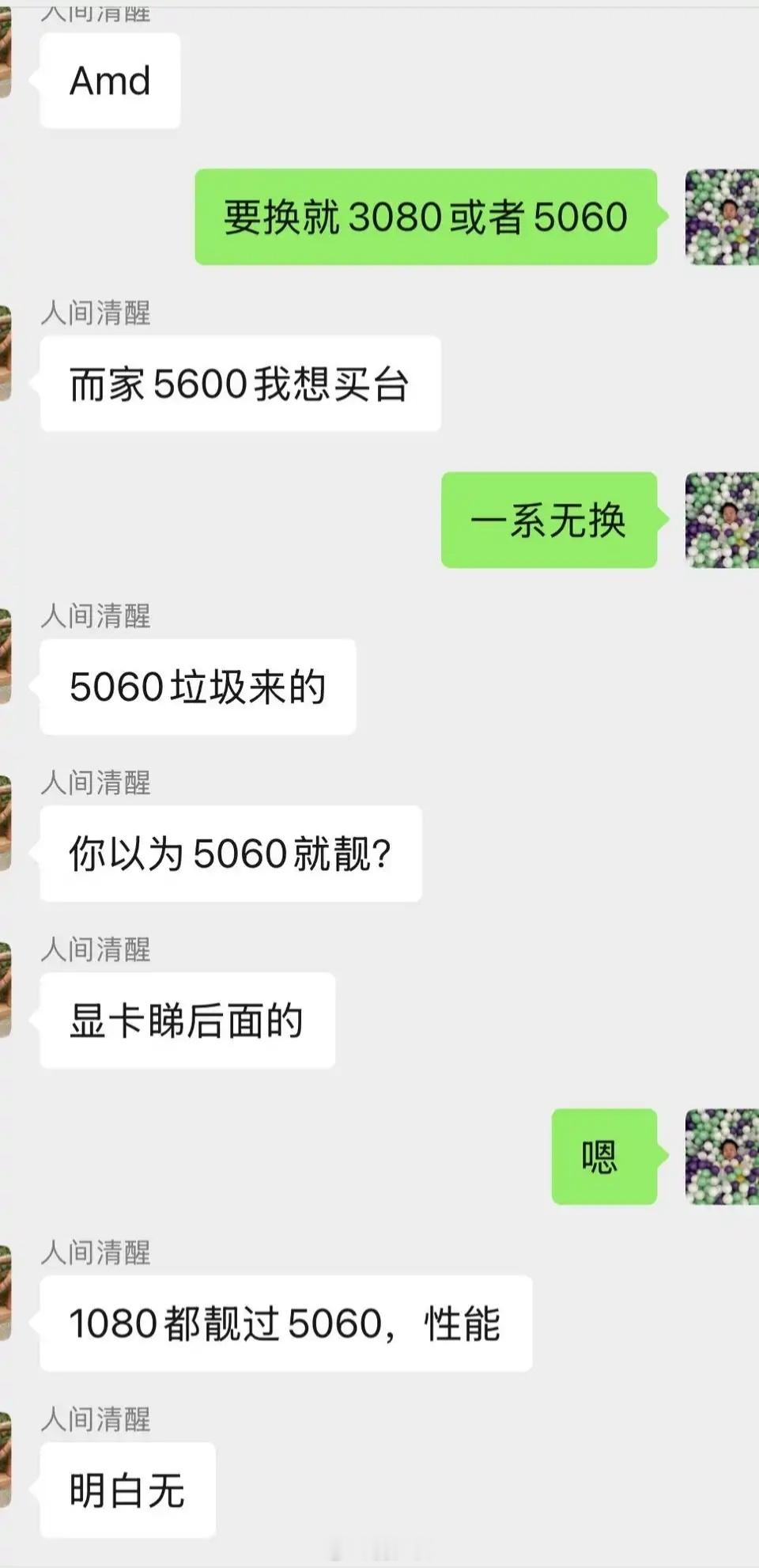
【15评论】【1点赞】

【3评论】【22点赞】

【3评论】【1点赞】

作者最新文章
热门分类
科技TOP
科技最新文章