Cohere 这个公司在国内没什么名气,但在业界 Cohere 是不容忽视的存在,很多做架构方面的非常关注他们。他们创始人还是《attention is all you need》的作者之一,这篇论文直接开启了大模型技术的大爆发。
这一次推出了迄今为止最强大的、最高效的 LLM —— Cohere command A+ ,并开源(Apache 2.0),让开发者从实验到生产都能轻松使用企业级 Agentic 能力。
🔆 核心亮点:
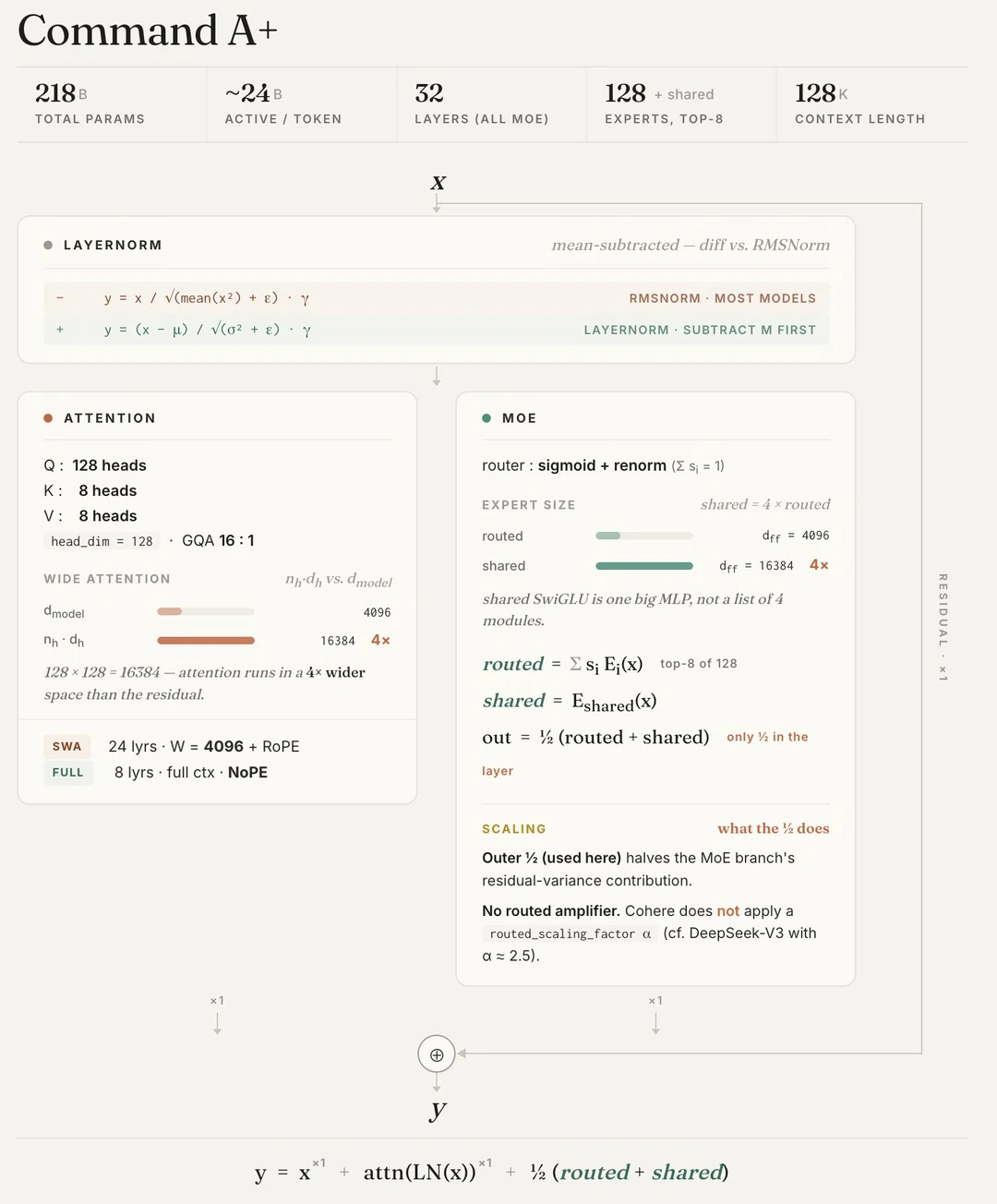
🔸极致高效:MoE 架构(218B 总参数,25B 激活),宣传说量化后只用 2 张 H100(或 1 张 Blackwell)即可跑,真正做到「最小硬件部署」。
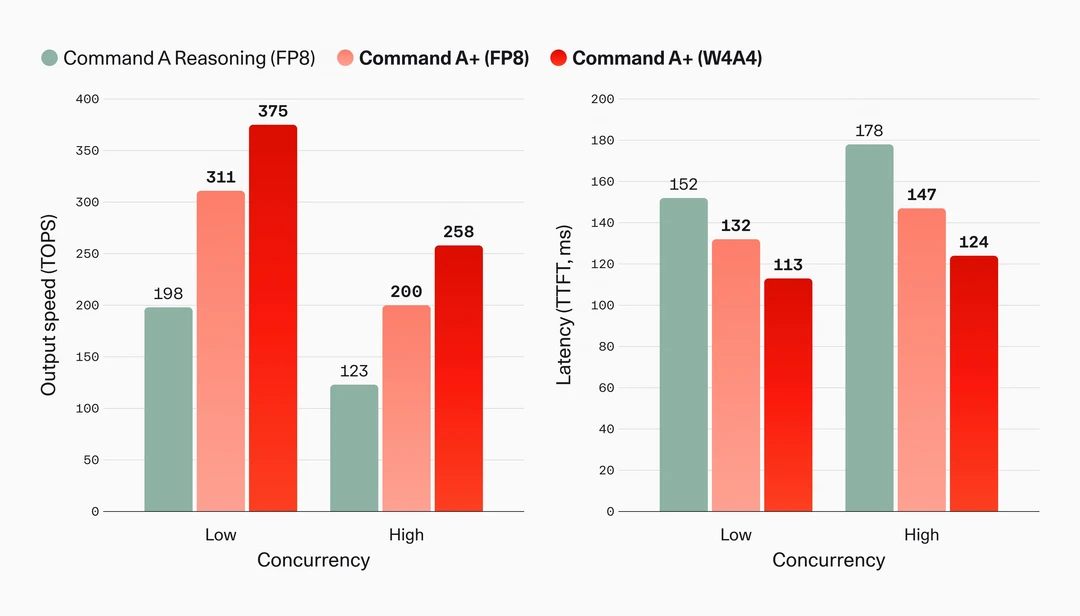
🔸更快:输出速度提升超 2 倍,延迟降低 30%,结合 speculative decoding 进一步加速。
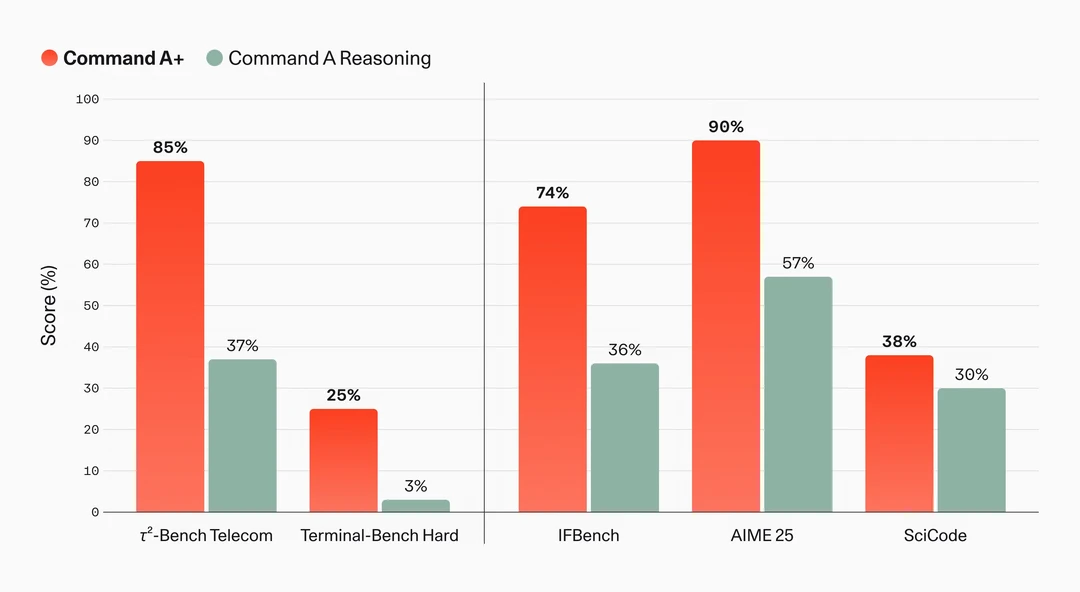
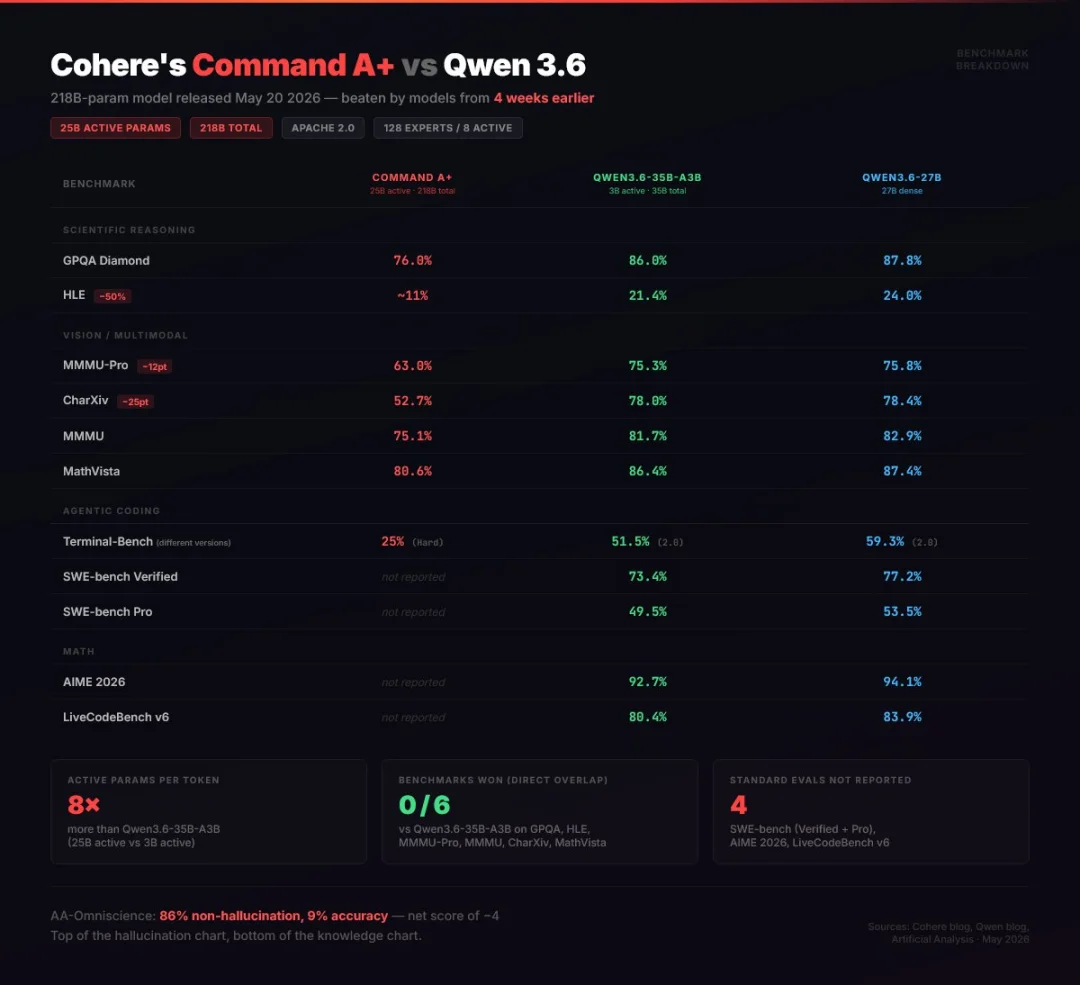
🔸更聪明:Agentic 工作流、复杂推理、多步任务全面提升(例如 Telecom 基准从 37% 飙升至 85%)。
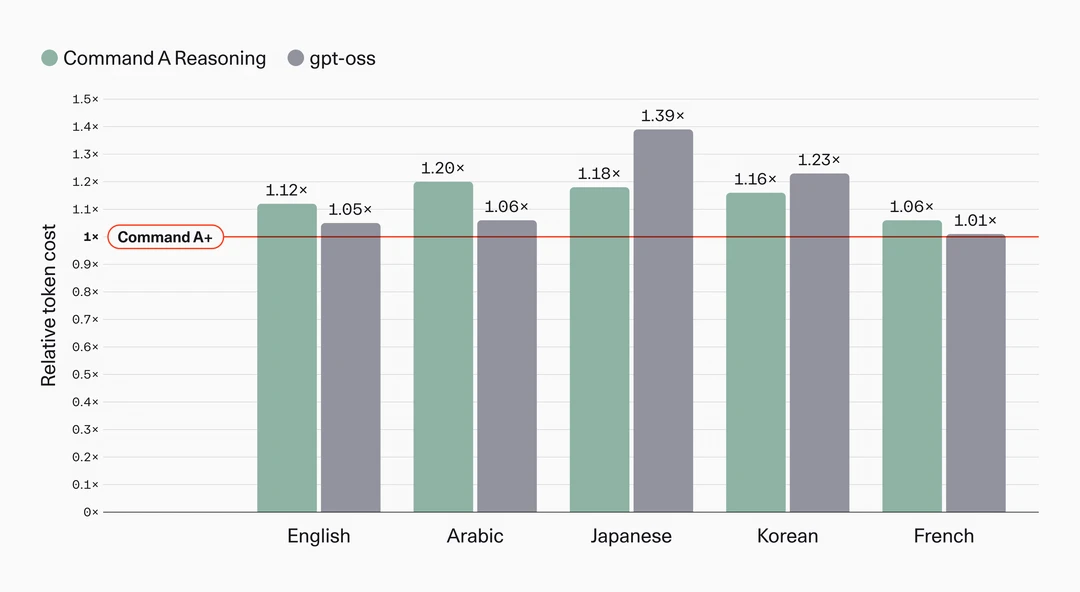
🔸更国际化:原生支持 48 种语言,非欧洲语言效率显著优化,适合全球应用。
🔸多模态:支持文本 + 图像 + 工具调用,擅长 RAG、文档处理、视觉推理等企业场景。
🔸上下文:128K 输入 / 64K 生成。
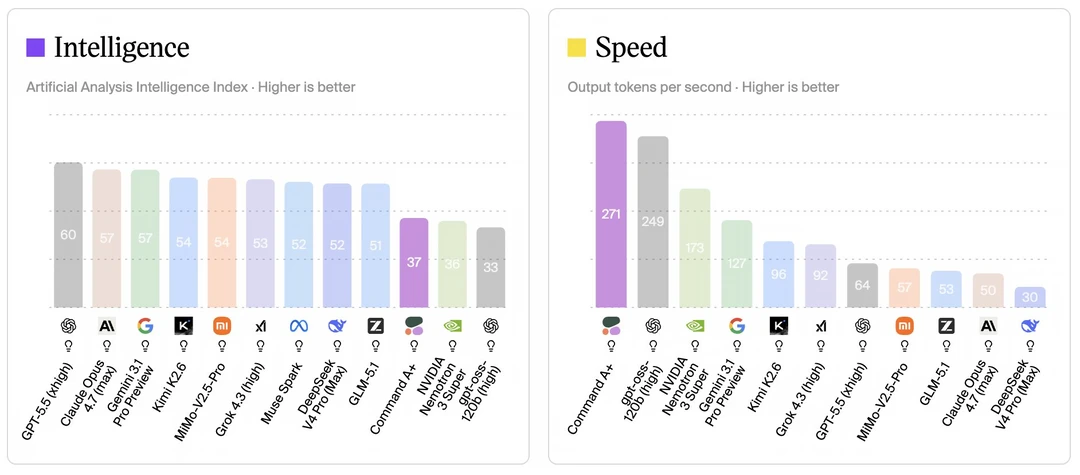
速度方面,Command A+表现亮眼,输出速度达到 271 tokens/s,超越了 gpt-oss-120b(249 t/s)、NVIDIA Nemotron(173 t/s)等竞品,成为当前速度最快的模型之一,非常适合实时 Agent、高吞吐量等场景。
智能表现上则相对一般,综合 Intelligence Index 仅 37 分,在顶级模型中处于中下游(GPT-5.5 为 60、Claude 57、Grok 53)。
效率与部署上,Command A+ 激活参数虽然是 Qwen 3.6-35B 的 8 倍多,但硬件门槛更低,量化后仅需 2 张 H100 就能跑,特别适合本地部署和私有化场景。
但因为 Cohere command A+ 开源、可控、高效的优势,非常适合企业 RAG、多语言应用和自建 Agent 路线。感兴趣的同学可以戳项目页了解 ~
如果你觉得对你有用的话 ~ 欢迎点赞收藏并分享给你的朋友们~