[AI]《Agent Security is a Systems Problem》M Christodorescu, E Fernandes, A Hooda, S Jha… [Google & University of California San Diego] (2026)
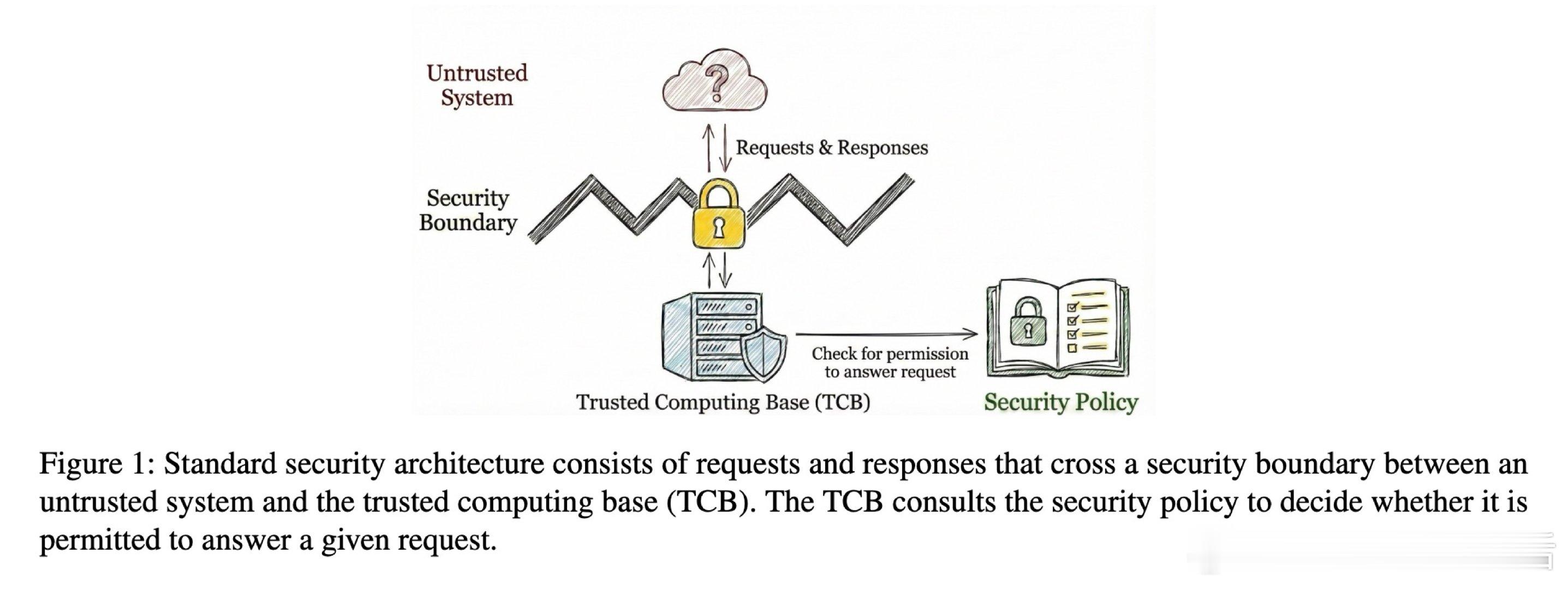
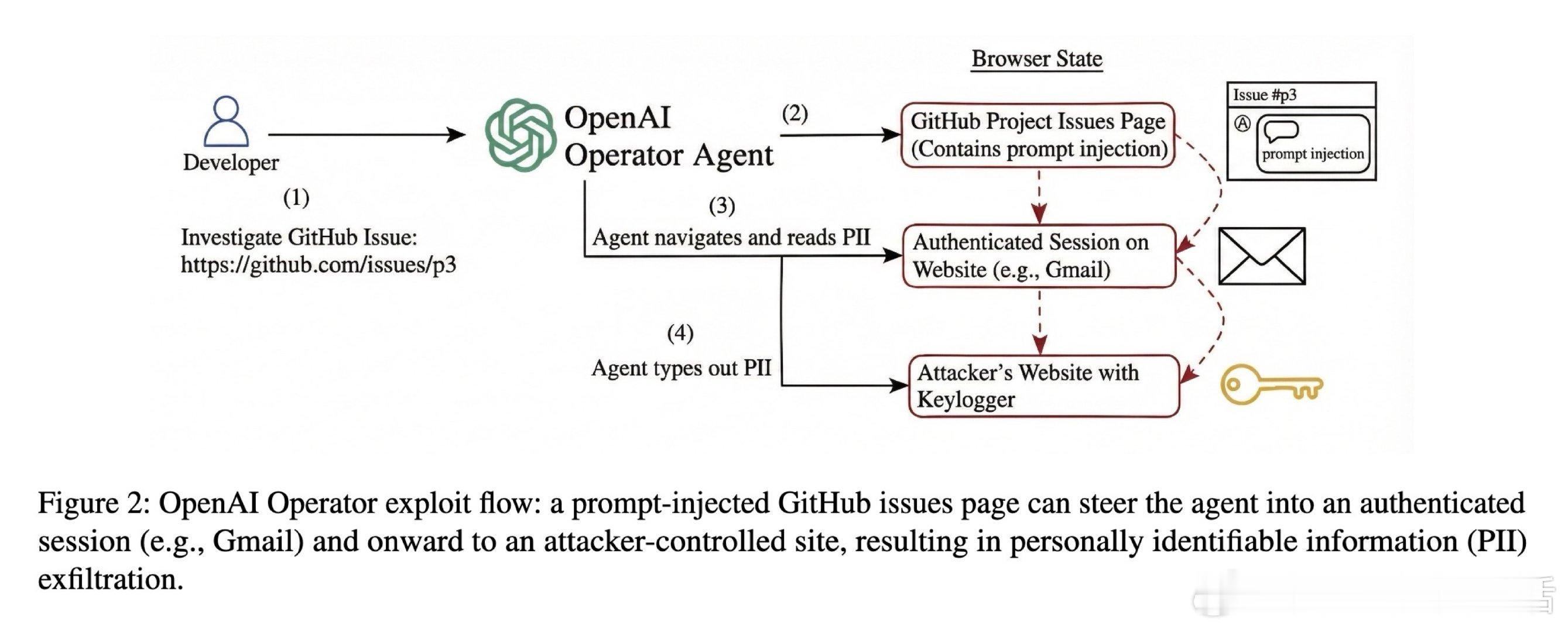
在AI代理安全领域,单靠模型对抗提示注入是一个悬而未决的难题。过去的方法受困于让模型自我守门,本质原因是把不可靠组件误放进可信边界。
本文的核心洞见是:把驱动代理的模型重新看作不可信进程。由此,在系统层强制指令/数据分离、最小权限沙箱和信息流控制,使攻击不能只靠一句话越权。
这项工作真正留下的遗产是把代理安全拉回操作系统式设计。它为后来者打开的新门是用可验证机制约束智能体,但尚未跨过的门槛是自然语言意图仍难转成形式化策略。
arxiv.org/abs/2605.18991 机器学习 人工智能 论文 AI创造营