[CV]《SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture》H Diao, P Wu, H Deng, J Wang… [sensenova] (2026)
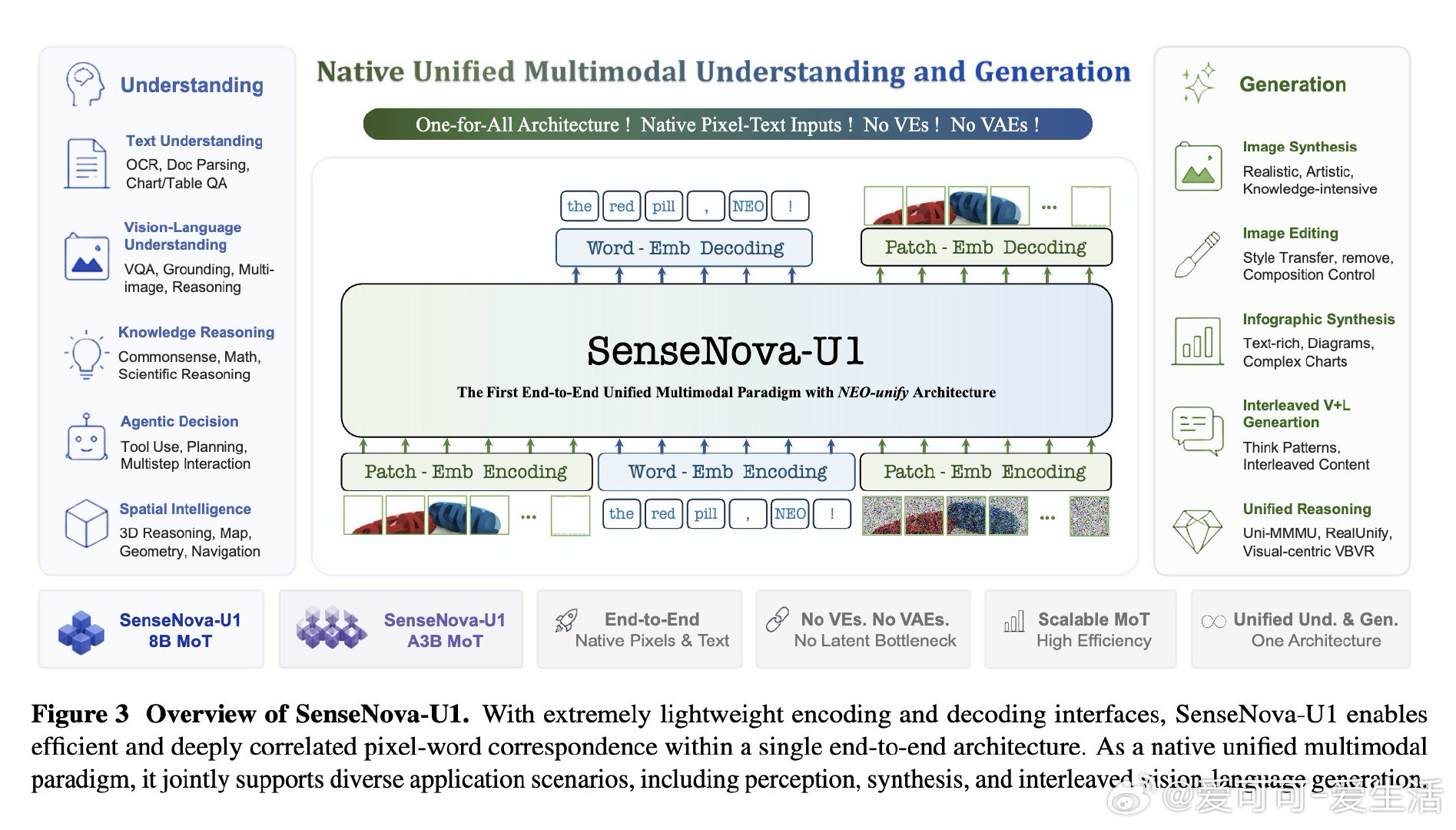
在多模态模型中,理解与生成长期被拆成两套系统。过去依赖视觉编码器和VAE,受困于语义表征与像素细节分裂,本质是中间表示把能力割裂。
本文的核心洞见是:把图像与文字重新看作同一原生序列。由此,近无损像素接口、MoT双流骨干与文本交叉熵/像素流匹配联合训练,使理解和生成在同一空间内互相塑形。
这项工作真正留下的遗产是:统一多模态不必靠模块拼接。它打开的新门是模型可在感知、生成、行动间内生迁移,但尚未跨过的门槛是像素级训练成本与高分辨率细节稳定性。
arxiv.org/abs/2605.12500 机器学习 人工智能 论文 AI创造营