【LLM 推理底层逻辑拆解:预填充和解码原来完全不一样】
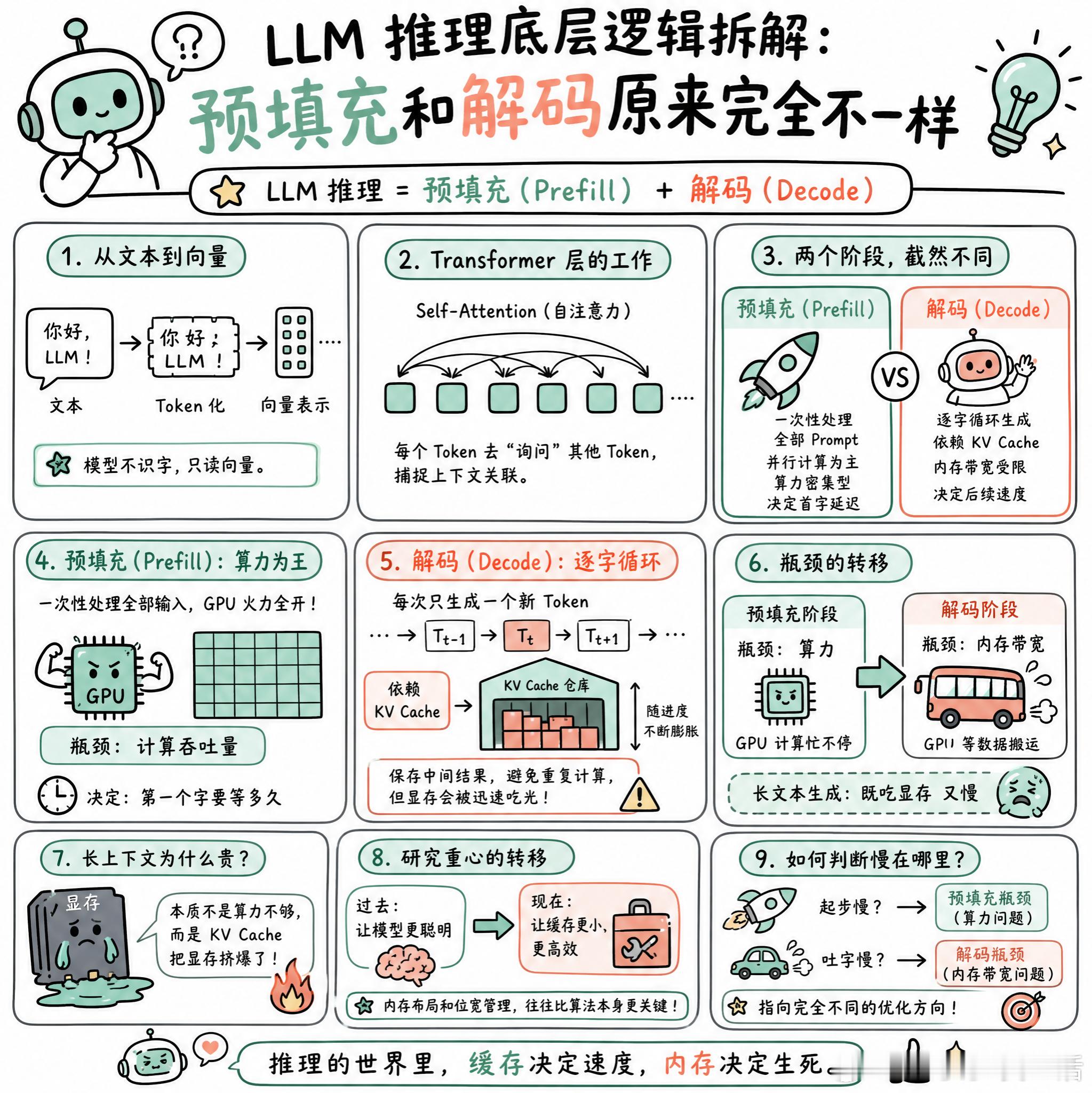
快速阅读:LLM 推理并非单一过程,而是分为“预填充”与“解码”两个截然不同的阶段。前者是算力密集型的矩阵运算,决定了首字延迟;后者是内存带宽受限的逐字循环,决定了后续输出的流畅度。
当你敲下回车,等待回复的过程其实是一场极其精密的流水线作业。
模型并不识字,它只读向量。文本先被拆解成 Token,再映射到高维空间的向量中。随后,这些向量进入 Transformer 层,通过 Self-Attention 机制,让每个 Token 去“询问”其他 Token,从而捕捉上下文的关联。
这里有个很有意思的现象:生成第一个 Token 的过程,和生成后续 Token 的过程,底层逻辑完全不同。
第一阶段叫 Prefill(预填充)。模型需要一次性处理你输入的全部 Prompt。这就像是在做大规模并行计算,GPU 的算力被填得满满当当,瓶颈在于计算吞吐量。这决定了你看到第一个字之前要等多久。
一旦第一个字蹦出来,模型就切换到了 Decode(解码)模式。它进入了一个逐字循环:每次只处理一个新 Token,但为了不重复计算之前的上下文,它必须依赖 KV Cache。
KV Cache 就像是一个随进度不断膨胀的临时内存仓库,它把之前计算过的中间结果存起来。有了它,生成速度才不会因为序列变长而呈指数级下降。但代价是显存会被迅速吃光。
这时候,瓶颈突然从“算力”变成了“内存带宽”。GPU 并不缺计算能力,它只是在疯狂等待内存把庞大的权重和缓存数据搬运过来。这就解释了为什么长文本生成时,模型会显得既吃显存又慢。
有网友提到,长上下文之所以贵,本质上不是因为算力不够,而是 KV Cache 把显存挤爆了。
现在的研究重心,正从如何让模型更聪明,转向如何让这个“缓存仓库”更小、更高效。毕竟,在推理的世界里,内存布局和位宽管理,往往比算法本身更决定生死。
当你下次觉得模型响应慢时,可以观察一下:是起步慢(预填充瓶颈),还是吐字慢(解码瓶颈)?这指向的是完全不同的优化方向。
akshay_pachaar/status/2050941458614751327