【Qwen3.6-27B 发布:稠密模型实现对超大规模 MoE 模型的跨代超越】
快速阅读:Qwen3.6-27B 的发布标志着稠密模型在编程与推理任务上实现了对超大规模 MoE 模型的跨代超越。其在保持极高部署灵活性的同时,为开发者提供了一个接近旗舰级的本地化智能体方案。
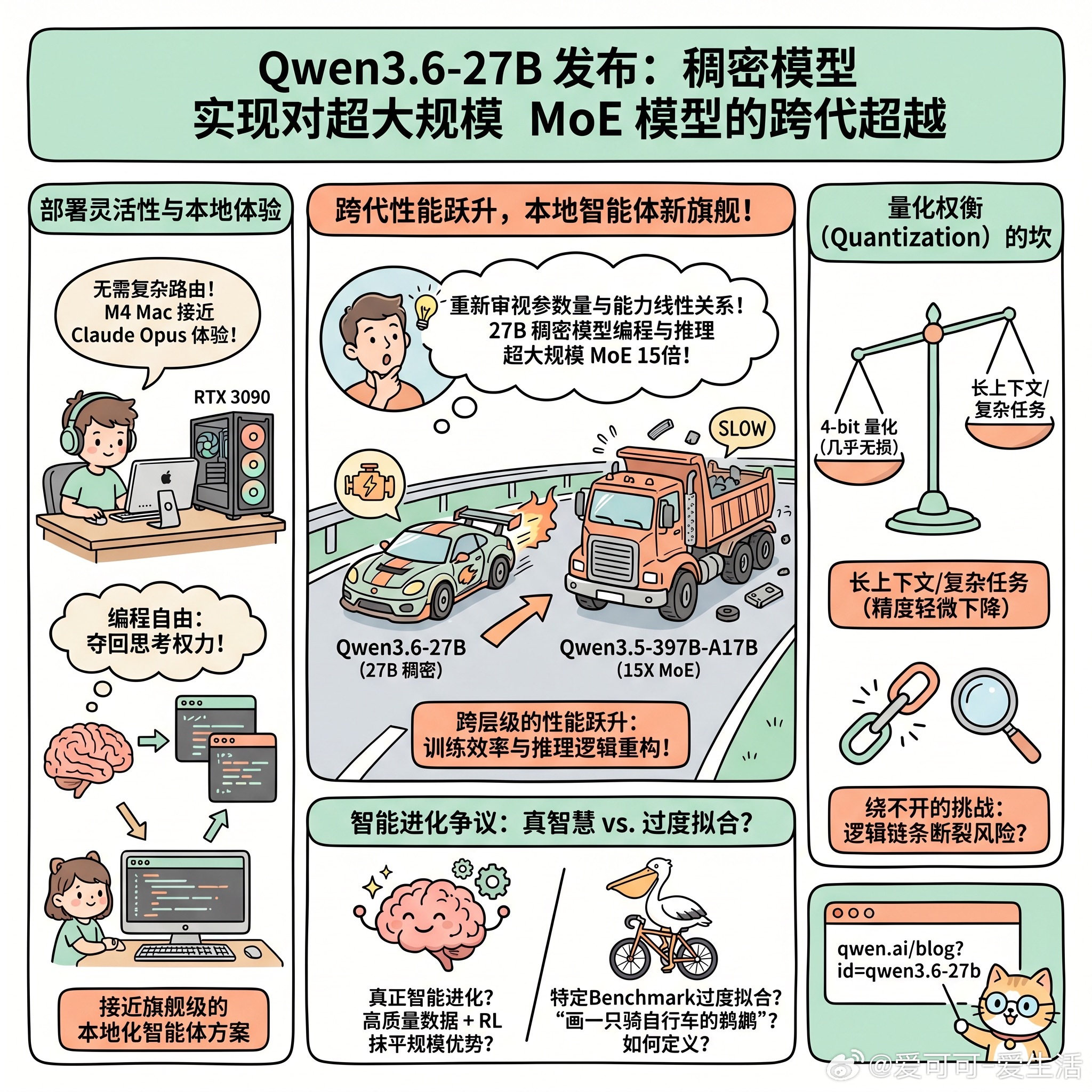
Qwen3.6-27B 的出现,让人们重新审视参数量与能力的线性关系。它是一个 27B 的稠密模型,却在智能体编程基准上,把参数量是它 15 倍的 Qwen3.5-397B-A17B 甩在了身后。这种感觉就像是用一台精密的涡轮增压小排量引擎,在赛道上超了一辆笨重的重型卡车。
这种跨层级的性能跃升,本质上是训练效率与推理逻辑的重构。
对于开发者来说,稠密架构意味着无需处理复杂的 MoE 路由,部署起来更直接。有网友提到,在 M4 芯片的 Mac 上,这种模型已经能提供接近 Claude Opus 的体验。对于那些追求“编程自由”的人来说,这意味着你可以把思考的权力从昂贵的 SaaS 订阅中夺回来,放进自己的 RTX 3090 或 Mac Studio 里。
当然,本地运行并非没有代价。量化权衡(Quantization)依然是绕不开的坎。虽然 4-bit 量化在很多场景下几乎无损,但在处理长上下文或复杂的智能体任务时,精度的轻微下降可能会导致逻辑链条的断裂。
有观点认为,模型规模的优势正在被高质量数据和强化学习(RL)抹平。如果 27B 真的能达到 Opus 的水平,那么智能体的门槛将彻底改变。
现在的争议点在于,这种性能提升究竟是真正的智能进化,还是针对特定 Benchmark 的“过度拟合”?如果连“画一只骑自行车的鹈鹕”都能成为一种测试,我们该如何定义真正的智慧?
qwen.ai/blog?id=qwen3.6-27b