除了这个使用技巧网页链接 ,claude 还分享了 在 Claude Code 中使用 Claude Opus 4.7 的最佳实践。(markdown排版,建议web阅读)
在 Claude Code 中使用 Claude Opus 4.7 的最佳实践
了解如何利用重新校准的 effort 等级、自适应思考和新的默认设置,优化你在 Claude Code 中对 Opus 4.7 的使用体验。
Opus 4.7 是我们目前正式可用的最强通用模型,尤其适合编程、企业工作流以及长时运行的智能体任务。与 Opus 4.6 相比,它更擅长处理模糊任务,更善于发现 bug 和进行代码审查,在跨会话保持上下文方面更稳定,也能在较少指导下更好地推进含糊任务。
我们在发布公告中提到,两项变化会影响 token 用量:更新后的 tokenizer,以及模型在更高 effort 等级下、尤其是在长会话后续轮次中更倾向于进行更多思考。因此,从 Opus 4.6 切换到 Opus 4.7 时,通常需要做一些调优才能获得最佳效果。对提示词和运行框架做少量调整,往往就能带来明显提升。
本文将介绍发生了哪些变化,以及如何在 Claude Code 中更有效地使用 Opus 4.7。
如何组织交互式编程会话
Opus 4.7 的 token 消耗和行为,会因你使用的是单轮用户输入、更加自主的异步编程智能体,还是多轮用户交互、同步推进的编程智能体而有所不同。在交互式场景中,它会在用户发言后进行更多推理。这会提升长会话中的一致性、指令遵循能力和代码质量,同时也会带来更高的 token 消耗。
为了在 Claude Code 中更好发挥 Opus 4.7 的能力,我们发现,把 Claude 当作一位你在委派任务的高能力工程师,比把它当作一个需要你逐行引导的结对程序员,更容易得到理想结果:
- 在第一轮就把任务说清楚。高质量的任务描述应包含目标、约束条件、验收标准以及相关文件位置,这些信息能帮助 Opus 4.7 产出更强的结果。把信息分散在多轮对话里逐步补充,通常会降低 token 效率,有时也会影响整体质量。- 减少必须发生的用户交互次数。每一轮用户输入都会带来额外推理开销。把问题打包提出,并一次性提供足够上下文,让模型可以持续推进。- 在合适场景下使用 auto mode。对于你信任模型能够安全执行、且不需要频繁确认的任务,auto mode 可以缩短循环时间。它尤其适合你已经在首轮提供完整上下文的长时任务。Claude Code Max 用户现可在研究预览中使用 auto mode,通过 `Shift+Tab` 开启。- 为任务完成设置通知。你可以让 Claude 在任务完成时播放提示音,它也可以通过基于 hook 的方式为自己创建通知。
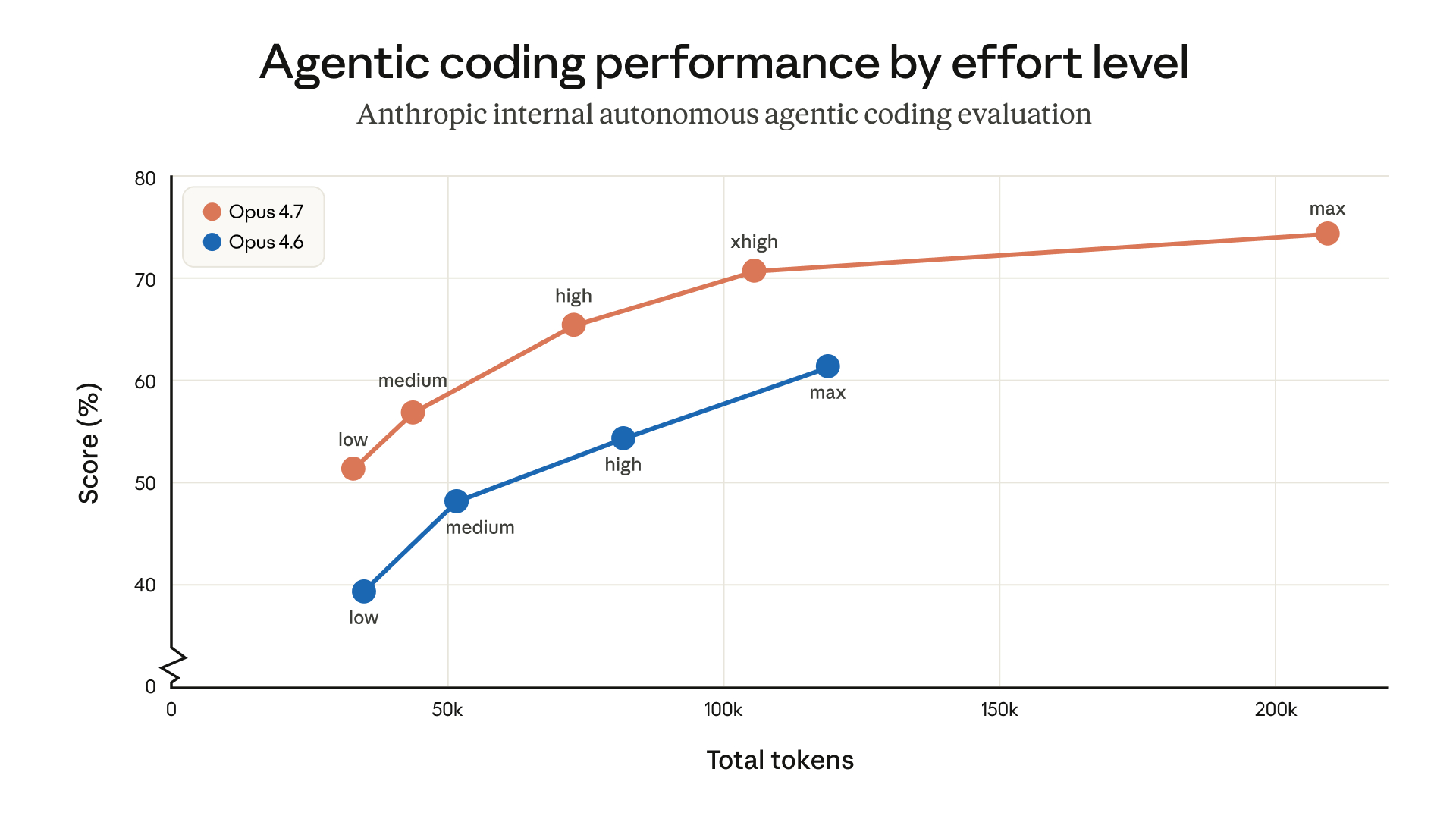
Opus 4.7 推荐的 effort 设置
Claude Code 中 Opus 4.7 的默认 effort 等级现在是 **xhigh**。这是介于 high 和 max 之间的新等级,能让用户在高难度问题上更精细地权衡推理强度与延迟。我们推荐在大多数智能体式编程任务中使用 xhigh,尤其是设计 API 和 schema、迁移遗留代码、审查大型代码库等对智能水平更敏感的任务。
以下是各个 effort 等级的补充建议:
- **medium 和 low**:适合成本敏感、延迟敏感或范围明确的小任务。面对更难的问题时,能力会弱于更高 effort 等级,但即便如此,它在相同 effort 下依然优于 Opus 4.6,有时还会消耗更少 token。- **high**:在智能水平和成本之间取得平衡。如果你在并行运行多个会话,或希望在不显著牺牲质量的前提下降低成本,可以选择 high。- **xhigh(默认、推荐)**:最适合大多数编程和智能体任务。它兼顾较强的自主性和智能水平,同时避免 max 在长时智能体运行中可能带来的 token 失控。- **max**:能在真正困难的问题上进一步压榨性能上限,但收益会逐渐减小,也更容易出现过度思考。适合有意识地用于评测模型上限,以及极度依赖智能表现且成本不敏感的场景。
如果你正在升级到新模型,我们建议优先尝试不同 effort 等级,而不是直接沿用旧设置。你也可以在同一任务过程中切换 effort,以更灵活地管理 token 消耗和推理强度。
我们将 Opus 4.7 的默认 effort 设为 xhigh,因为我们认为它最适合大多数编程任务。对于现有 Claude Code 用户,只要你之前没有手动设置 effort,系统就会自动升级到 xhigh。你依然可以手动调整。
如何使用自适应思考
Opus 4.7 不支持带固定 thinking budget 的 Extended Thinking。作为替代,Opus 4.7 提供了 **adaptive thinking(自适应思考)**。这意味着模型在每一步都可以自主决定是否思考,并根据上下文判断是否需要投入更多思考资源。面对简单查询时,它可以快速作答;当某一步不需要深度思考时,它可以直接跳过;当某些环节更值得投入时,它会把 thinking tokens 集中用在那些地方。对于整段智能体运行来说,这通常会带来更快的响应和更好的使用体验。
这一版本中的自适应思考有了明显提升,尤其是 Opus 4.7 更不容易陷入过度思考。
如果你希望更精细地控制思考强度,可以直接在提示词中说明:
- 如果你希望更多思考,可以写:`回答前请认真、分步骤地思考;这个问题比看起来更难。`- 如果你希望减少思考,可以写:`优先快速响应,而不是深入思考。遇到不确定时,直接回答。`
这样能节省 token,但在较难步骤上可能会牺牲一些准确性。
值得了解的行为变化
从 Opus 4.6 到 4.7,有几个默认行为发生了变化。如果你之前针对旧模型精细调过提示词或运行框架,这些变化值得特别关注。
回答长度会根据任务复杂度自动校准
Opus 4.7 不像 Opus 4.6 那样默认偏冗长。简单查询会得到更短的回答,开放式分析则会得到更长的回答。如果你的使用场景依赖特定长度或风格,最好在提示词中明确说明。我们的经验是,给出你期望语气和风格的正向示例,通常比使用“不要这样做”的负向指令效果更好。
模型更少调用工具,更多进行推理
这在很多场景下会带来更好的结果。如果你希望模型更频繁地使用工具,例如在智能体任务中更积极地搜索或读取文件,就需要明确说明工具应在什么情况下使用,以及为什么要使用。
默认情况下生成的子智能体更少
Opus 4.7 在决定是否把任务委派给子智能体时更加谨慎。如果你的使用场景适合并行使用多个子智能体,例如同时处理多个项目或读取多个文件,我们建议在提示词中明确写出来。示例如下:
> 对于你可以在单次响应中直接完成的工作(例如重构一个你已经看得到的函数),直接完成即可。对于需要在多个项目间并行展开,或需要读取多个文件的情况,在同一轮中生成多个子智能体。
接下来可以尝试什么
Opus 4.7 在长时运行任务上的表现优于之前的模型。因此,它很适合那些过去主要受限于人工监督成本的任务,例如复杂的多文件修改、模糊问题调试、跨服务代码审查,以及多步骤智能体任务。
建议先保持 effort 为 xhigh,看看在第一轮输入后它能推进到什么程度。
AI创造营How I AI