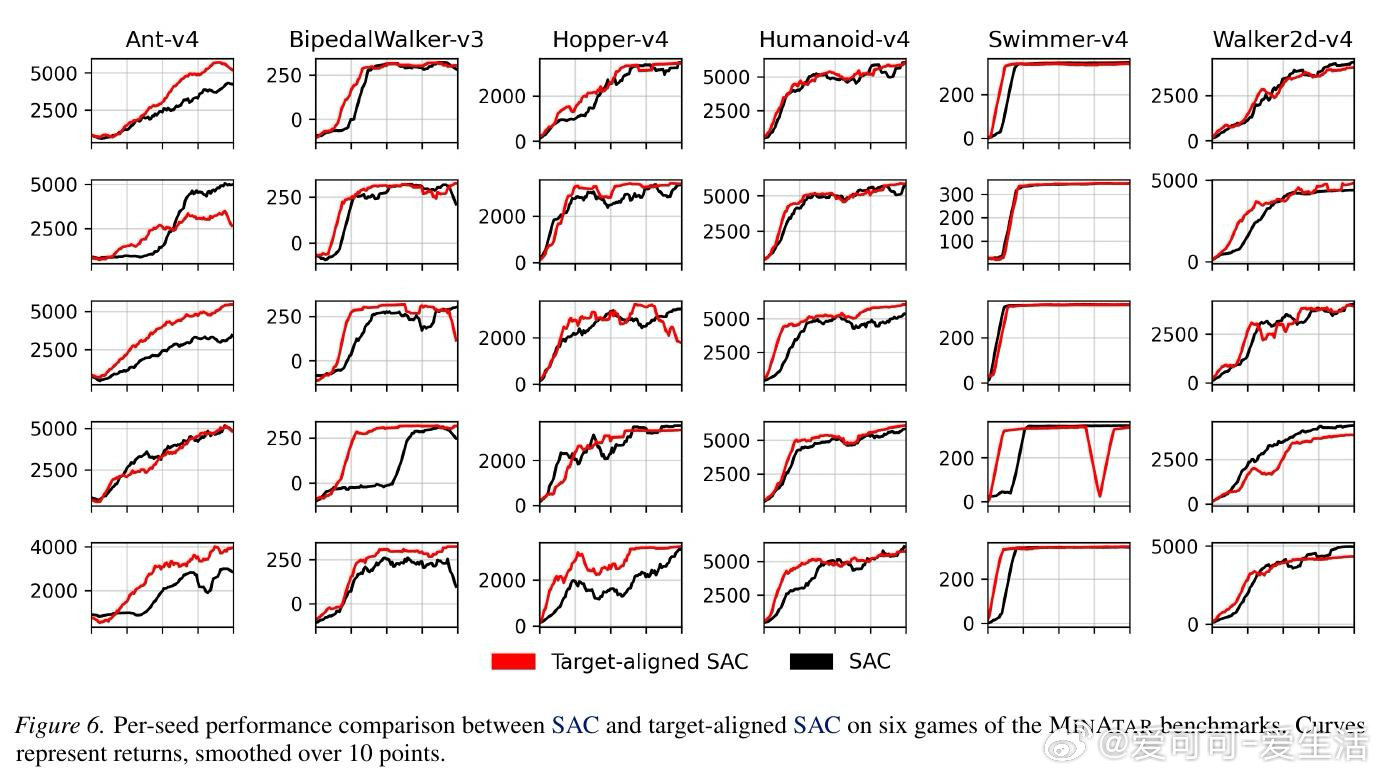
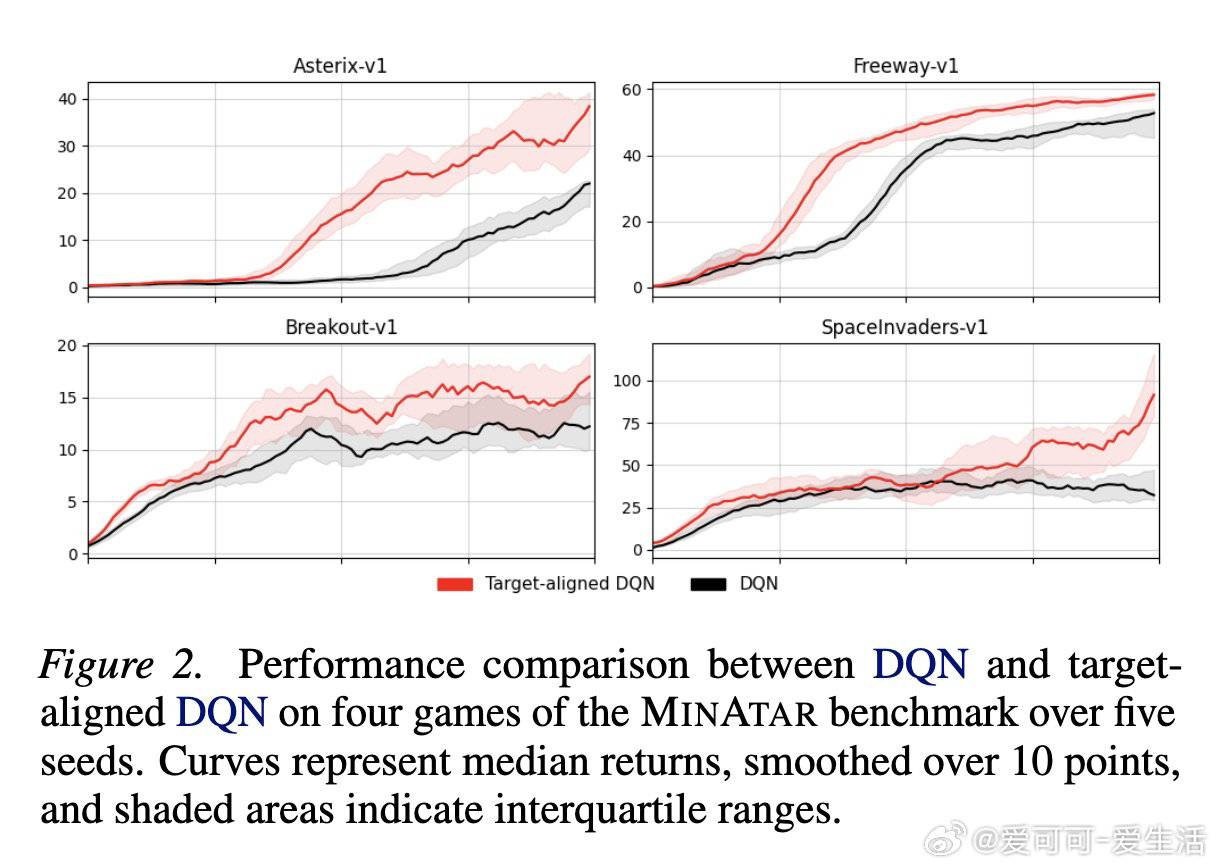
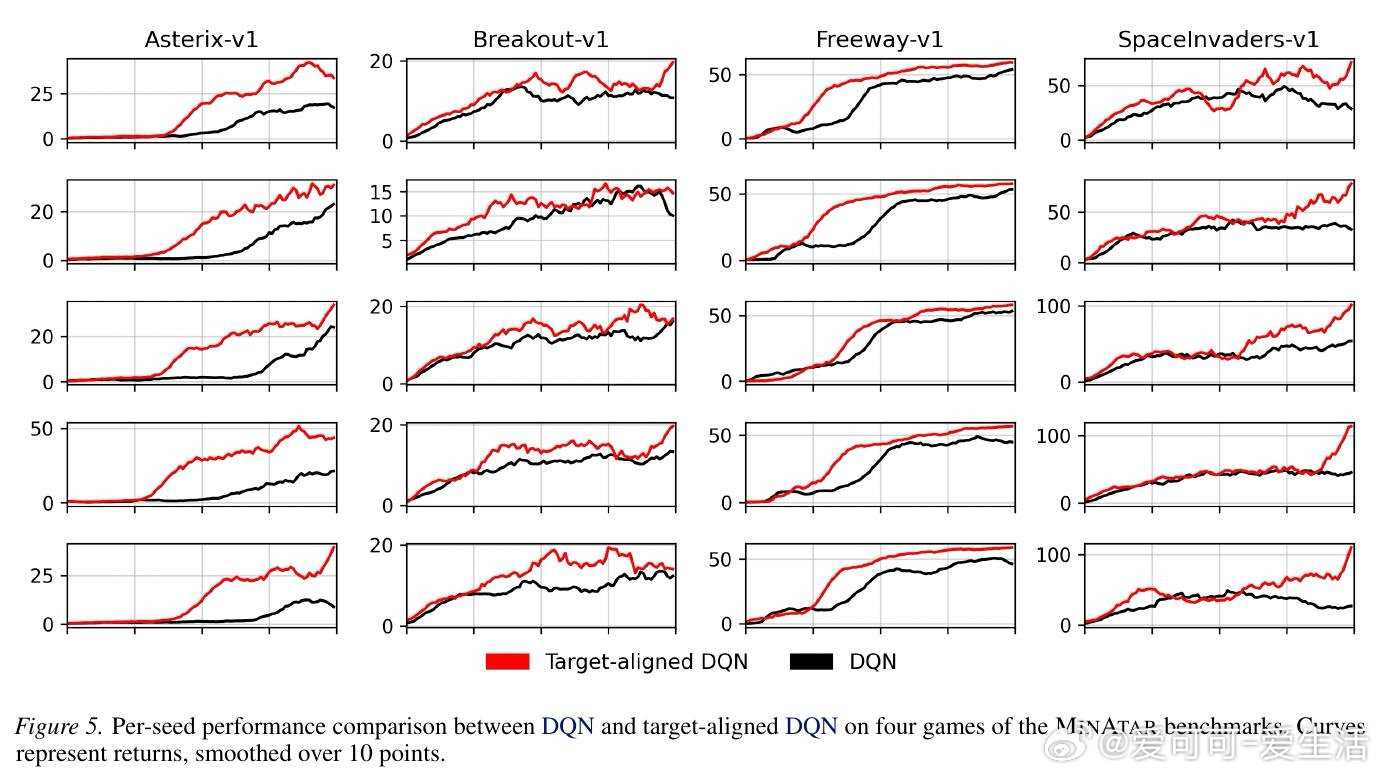
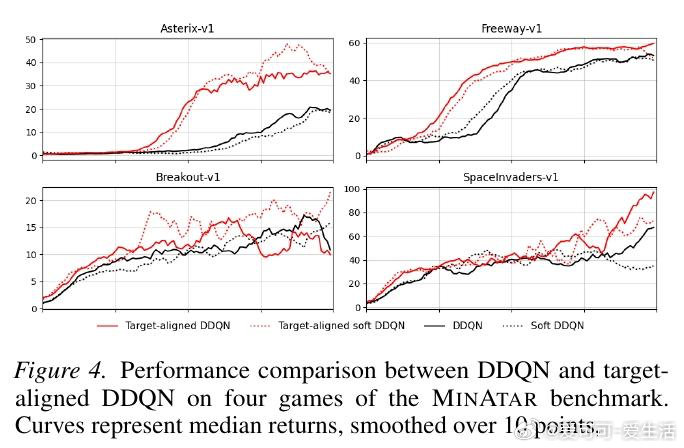
[LG]《Target-Aligned Reinforcement Learning》L S. Pleiss, J Harrison, M Schiffer [Technical University of Munich & Google Research] (2026)
深度强化学习中,目标网络是稳定训练的基石,却内嵌一个无法回避的裂缝:更新越慢,目标越陈旧;越追求稳定,学习信号越滞后。调参者只能在"稳定"与"新鲜"之间拨动同一根滑块,本质是在两害之间取其轻。
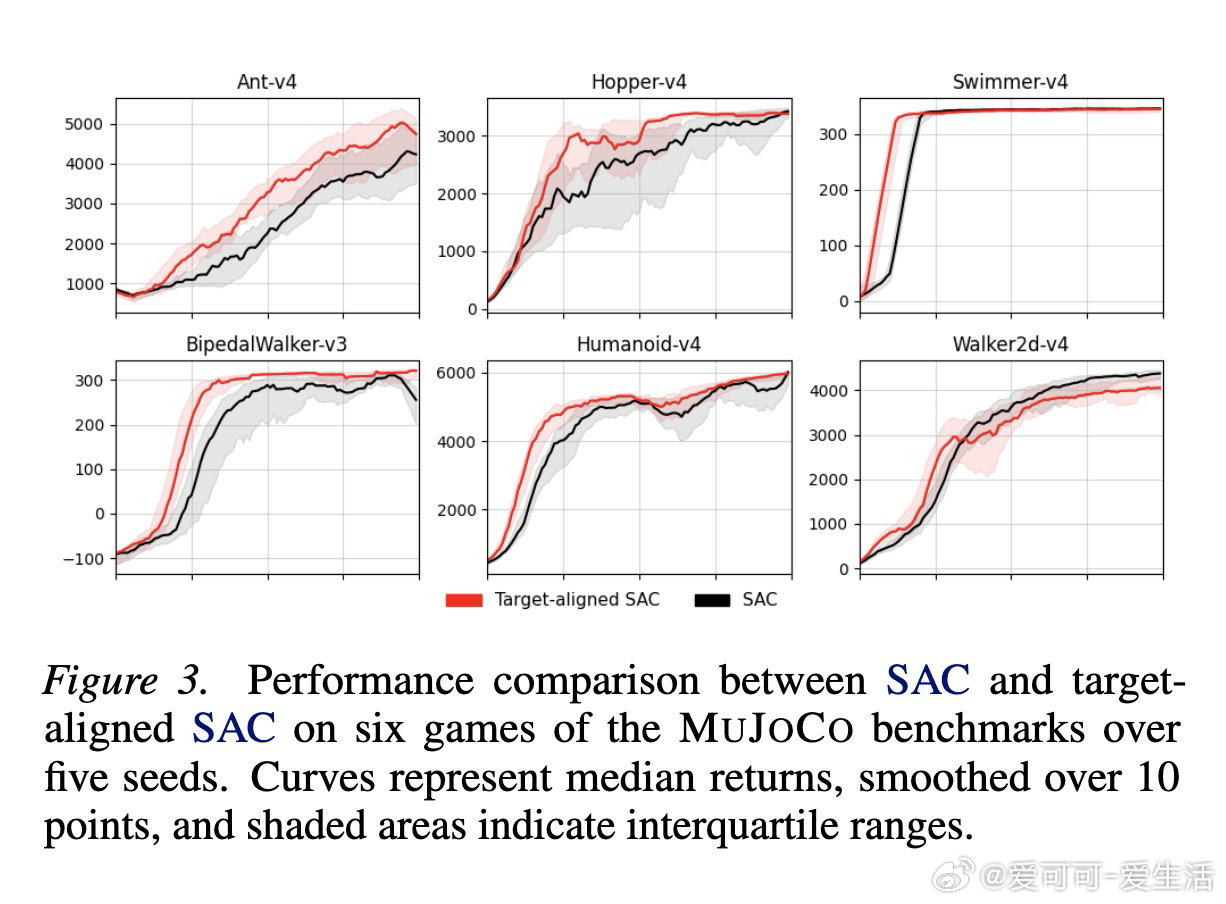
TARL的核心洞见是:把"过时的目标值"重新看作"待验证的方向提案"。它不加快目标网络的更新,而是借用在线网络充当裁判——计算每条转移样本上离线目标与在线估计的方向一致性,在每批次中优先选取"两者共识"的样本进行梯度更新,将分歧样本暂时搁置,等目标网络刷新后再行处理。这一操作无需修改网络结构,仅在采样环节插入一个筛选步骤。
这项工作真正留下的遗产是:稳定性与时效性不必是零和博弈,在线网络的"方向信息"即便不足以充当学习目标,也足以成为可靠的方向验证器。它为后来者打开的新门是:对样本"质量"的主动判别——超越TD误差大小,转向多重估计一致性。但尚未跨过的门槛是:对齐信号本身依赖在线网络的局部稳定性,在高噪声或极端探索阶段,其可靠性边界尚未得到充分检验。
arxiv.org/abs/2603.29501
机器学习 人工智能 论文 AI创造营