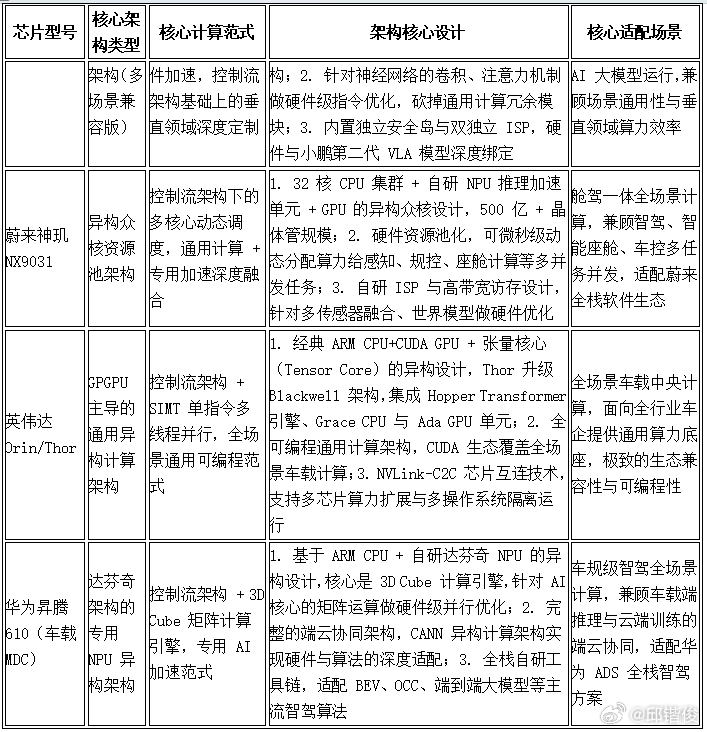
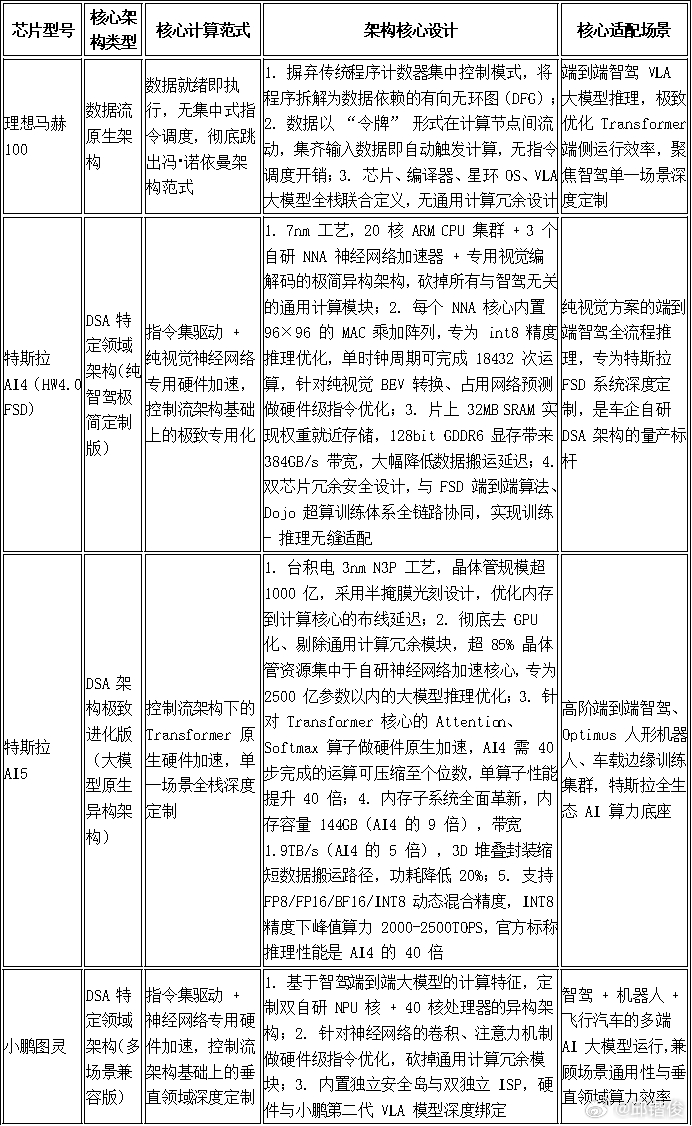
1颗 理想马赫100≈ 2.1颗 蔚来神玑≈ 2.8颗 小鹏图灵?蔚小理都自研芯片,理想的数据流架构芯片最厉害?上面的话是为了引起你们的注意,这个事我也不懂,还在学习。之前听理想的人提及马赫M100芯片,说到它因为采取独特的数据流架构,因此算力是英伟达Thor-U(700tops)的3倍。这个有点吓人了。因为蔚来的神矶芯片算力号称是Orin-X(254TOPS)的4倍,换算是Thor-U的1.4倍;而小鹏的图灵芯片,是Orin-X(254TOPS)的3倍,换算是Thor-U的1.07倍。那要这么算,就会得到开头那个结果:1颗 理想马赫100≈ 2.1颗 蔚来神玑≈ 2.8颗 小鹏图灵当然,算力的利用情况很复杂,而且跟精度等等相关。我好奇的是数据流架构,这块确实不懂,因此请豆包研究了蔚小理和英伟达、华为、特斯拉的芯片架构的区别。如果,豆包没有被“投毒”的话,理想的马赫芯片的数据流架构,确实非常具有革命性:一、七款芯片的核心架构本质差异智驾芯片的架构核心,是定义 “数据流动规则、计算调度逻辑” 的底层范式,七款芯片分属四大核心计算架构流派,核心差异如附图。
架构核心差异的底层逻辑1.理想马赫的数据流架构是唯一的范式级革新:彻底跳出冯・诺依曼架构的 “存储墙” 瓶颈,把计算主导权从 “指令” 交给 “数据”,完全为 AI 推理而生,是七款芯片中对智驾大模型适配最极致的架构,代价是完全放弃通用计算能力。2.特斯拉 AI4/AI5、小鹏图灵同属 DSA 架构,但走了完全不同的定制路径:(1)特斯拉 AI4 是单一场景极致极简定制,从芯片定义阶段就完全匹配纯视觉 FSD 算法,砍掉所有非必要模块,是 DSA 架构中 “专用性拉满” 的量产标杆;(2)特斯拉 AI5 是大模型原生 DSA 架构,在 AI4 的专用化基础上,针对端到端大模型做了全链路硬件原生优化,同时兼顾了机器人、边缘训练的算力需求,是专用架构向大模型时代的全面进化;(3)小鹏图灵是垂直领域多场景兼容,在智驾核心优化的基础上,保留了机器人、飞行汽车等多端 AI 场景的扩展性,在专用性与通用性之间做了平衡。3.蔚来神玑、英伟达、华为均属于异构计算架构,核心取舍完全不同:英伟达极致追求全场景通用与生态兼容,华为极致适配自研 AI 端云协同生态,蔚来则聚焦舱驾一体多任务并发的均衡性,三者均在 “通用算力 + 专用加速” 之间做不同权重的分配,核心是覆盖更广泛的场景与生态。二、芯片架构与实际算力的核心关系行业标称的峰值算力(TOPS) 只是理论最大值,架构是决定 “实际有效算力、算力利用率、延迟、能效比、持续算力输出能力” 的核心因素,二者的核心关联体现在 5 个关键维度:1. 计算范式与专用化程度,直接决定了算力利用率的天花板冯・诺依曼控制流架构的核心瓶颈,是 “计算单元速度远快于数据访问速度”,处理器大部分时间在等待数据搬运,而非执行计算;架构的专用化程度越高,算力利用率的天花板就越高。通用 GPGPU 架构(英伟达):在车载智驾场景中,即便经过车企深度优化,Orin-X 的算力利用率通常仅为 60%-80%,大量算力损耗在指令调度、数据搬运和通用计算冗余上。异构众核 / 专用 NPU 架构(蔚来神玑、华为昇腾):针对智驾场景做了硬件加速单元定制,算力利用率显著高于通用 GPU,优化后可达 80%-90%,但受限于通用计算的基础架构,仍存在不可避免的调度开销。DSA 定制架构(特斯拉 AI4/AI5、小鹏图灵):针对自家算法做了硬件级指令匹配,算力利用率实现质的飞跃。特斯拉 AI4 在运行 FSD 端到端算法时,算力利用率稳定在 92% 以上,是同级别通用架构芯片的 1.5 倍以上;这也是特斯拉 AI4 仅 300+TOPS 单芯片峰值算力,却能实现行业头部智驾表现的核心原因 ——1TOPS 有效算力可发挥出通用芯片 2-3TOPS 的实际效果。而特斯拉 AI5 通过算子级硬件原生加速,进一步消除了软件调度开销,算力利用率可逼近 98%,官方标称同等功耗下,有效推理性能是英伟达 H100 的 3 倍以上。数据流原生架构(理想马赫 100):彻底消除了指令调度开销,数据在流动中完成计算,内存访问次数大幅减少。官方实测数据显示,单颗马赫 100 运行 VLA 大模型时,有效算力是同制程英伟达 Thor-U 的 3 倍,同等芯片面积下,以更低功耗实现了远超传统架构的实际计算效能。2. 存储架构与带宽设计,决定了峰值算力的 “兑现能力”智驾大模型的计算过程,是海量传感器数据的反复读写与复用,“存储墙” 是峰值算力无法落地的核心障碍 —— 如果数据喂不饱计算单元,再高的峰值算力也只能 “空转”。架构对存储系统的设计,直接决定了计算单元能不能持续满负荷运行。数据流架构:天然实现数据就近计算、就近存储,数据在计算节点间一次流动就完成全链路计算,无需反复往返主存,从根源上缓解了存储墙问题,让峰值算力能持续转化为实际计算输出。特斯拉 DSA 架构:针对纯视觉方案的视频流处理做了存储架构的极致优化。AI4 将片上 SRAM 直接集成在 NNA 核心内,权重和激活值无需往返主存,数据读取延迟降低 90% 以上;AI5 更是通过 9 倍内存容量、5 倍带宽升级,配合 3D 堆叠封装,彻底解决了大模型推理时的内存带宽瓶颈,可稳定支撑 50 亿参数 Transformer 大模型的实时运行,不会出现算力波动。其他异构架构:通过片上缓存分层设计、高带宽内存接口、数据复用硬件优化减少数据搬运次数,但受限于冯・诺依曼架构的 “计算 - 存储分离” 底层逻辑,始终无法彻底解决存储墙问题,在多任务并发、大模型推理场景下,算力损耗会显著上升。3. 并行度设计,决定了不同场景下的算力效率不同架构的并行计算逻辑,适配不同的计算负载,直接决定了智驾场景的实际算力表现。英伟达 GPGPU 架构:SIMT 单指令多线程并行,擅长大规模、同质化的并行计算,在海量数据训练、图形渲染等通用场景优势显著,但在智驾端到端模型的不规则计算、低延迟推理场景中,并行效率会大幅下降。华为达芬奇架构:3D Cube 矩阵计算引擎,针对 AI 核心的矩阵乘法做了硬件级并行优化,Transformer 模型、卷积神经网络的计算效率远高于通用 GPU,是智驾感知模型的最优架构之一。特斯拉 DSA 架构、小鹏图灵:并行度设计完全匹配智驾算法的计算特征,只保留神经网络推理所需的乘加并行计算,针对 Transformer 注意力机制、卷积运算做了固定流水线并行优化,在智驾场景的推理并行效率远超通用 GPU。特斯拉 AI5 更是针对大模型的动态计算特征,实现了算子级的并行调度优化,在不规则计算场景下,并行效率较 AI4 再提升 5 倍。数据流架构:实现指令级、线程级、任务级的全维度并行,所有就绪的计算节点可同步执行,完美适配 Transformer 注意力机制的动态计算特征,在端到端智驾大模型的推理中,并行效率远超传统控制流架构。4. 软硬件协同深度,决定了算力的最终落地效果自研架构的核心优势,是实现 “芯片 - 编译器 - 算法 - 操作系统” 的全栈联合设计,让硬件算力完全匹配算法需求,彻底消除软硬件适配的算力损耗。特斯拉、理想、小鹏、蔚来的全栈自研架构:均与自家的智驾大模型、车规操作系统做了联合定义,从芯片设计初期就匹配算法的计算特征,无需适配第三方通用生态。其中特斯拉是行业内首个实现 “训练 - 推理全链路闭环” 的车企,Dojo 超算的训练体系直接与车载 FSD 芯片协同,模型训练阶段就针对芯片硬件做量化、裁剪和优化,上车后无需二次适配,直接实现算力的最大化利用。英伟达、华为的通用生态架构:依赖 CUDA/CANN 通用软件生态,车企需要基于通用平台做算法适配,适配的深度直接决定了最终的算力利用率。即便峰值算力极高,若软硬件适配不足,实际智驾表现也会远低于理论值。5. 架构的专用化程度,决定了能效比与算力的可持续性车规场景对功耗有严格的车载散热限制,架构决定了 “单位功耗能输出多少有效算力”,直接决定了芯片能否在车载狭小空间内持续输出满负荷算力,而不会出现降频、算力缩水。数据流架构、DSA 架构:无通用计算冗余,单位功耗的有效算力(能效比)远高于通用架构。特斯拉 AI4 整芯片功耗仅 36W,却能输出 300+TOPS 峰值算力,能效比远超同期同制程的通用智驾芯片;特斯拉 AI5 在 2000-2500TOPS 峰值算力下,功耗仅 200-250W,仅为英伟达同算力产品的 1/3;理想马赫 100 在同等算力输出下,功耗仅为通用架构芯片的几分之一,可在车规散热限制下持续输出满负荷算力。通用 GPGPU 架构:峰值算力越高,功耗呈指数级上升,在车载狭小空间内,很难持续维持峰值算力输出,高负载下极易出现降频、算力缩水的问题。总结架构是智驾芯片的 “底层基因”,它不直接决定峰值算力的数值,但决定了峰值算力有多少能真正转化为智驾场景的实际效能。理想马赫的数据流架构,是 AI 推理场景的极致优化,用范式革新实现了当前行业最高的有效算力与能效比,但完全牺牲了通用计算能力;特斯拉 AI4/AI5 的 DSA 架构,是专用化架构的量产标杆与进化方向,用全栈软硬件协同实现了极致的算力利用率与能效比,用最低的峰值算力实现了行业顶尖的智驾表现;小鹏图灵、蔚来神玑、华为昇腾、英伟达 DRIVE 系列,分别在多场景兼容、舱驾一体均衡、端云协同、通用生态四个方向做到了行业顶尖,是更均衡的全场景解决方案,代价是在单一智驾场景下,无法做到极致的算力效率。理想马赫100芯片