理想芯片拿下世界冠军级认证 理想汽车论文《M100: An Orchestrated Dataflow Architecture Powering General AI Computing》入选ISCA 2026(国际计算机体系结构年会)。
ISCA是计算机体系结构领域最具影响力的顶级会议之一,长期关注芯片、处理器以及AI算力等基础性技术问题,被视作该领域的风向标。
而理想汽车是汽车行业中首家获得该会议工业分区(Industry track)论文录取的企业。
我请理想同学帮我用通俗易懂的语言介绍了一下理想马赫100芯片上的“周密编排数据流架构”和传统芯片的区别。
以下是理想同学给我的回答,确实一看就明白了:
想象一下,你有一个大型工厂(代表芯片),里面有很多工人(代表计算单元),他们的任务是处理源源不断的原材料(代表数据)。
传统芯片(包括GPU)是怎么工作的?它像一个多级仓库的系统。
原材料(数据)先被送到一个大仓库(比如内存/显存)。
工人(计算单元)需要干活时,不能直接去大仓库拿,因为大仓库太远太慢。
于是,工厂在工人附近设置了很多小仓库(缓存):L1小仓库(离工人最近)、L2小仓库(稍远一点)、L3小仓库(更大一点)。
原材料需要先从大仓库运到L3小仓库,再运到L2小仓库,最后才运到工人旁边的L1小仓库。工人才能拿到材料开始干活。
干完活后的成品(计算结果),又需要反向搬运,从L1小仓库运回L2、L3,最后存回大仓库。
问题在哪? 这种“反复搬运”的过程很费时间(延迟),也很费力气(能耗)。
虽然工人(计算单元)本身干活能力很强(并行计算能力强),但大部分时间和精力都花在等材料和搬材料上了!
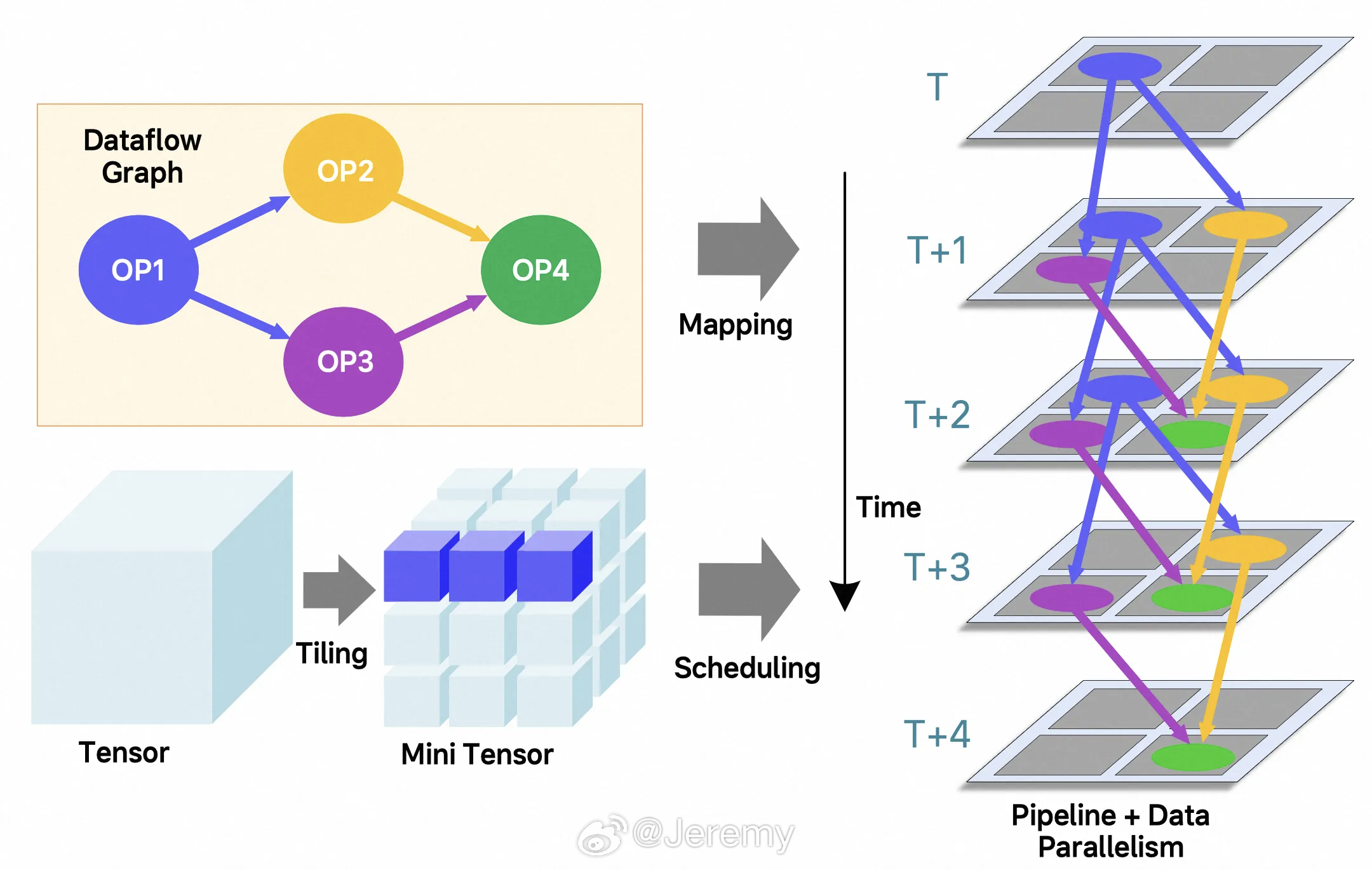
“周密编排数据流架构”(AI原生数据流架构)是怎么工作的?
它设计得像一个高度优化的、自动化流水线。
重点在于“周密编排”和“直接流动”。
工厂的设计师(架构师)提前精心规划好原材料(数据)应该从哪里来、经过哪些工人(计算单元)、怎么流动、最终到哪里去。
原材料(数据)被直接送到需要它的特定工人(计算单元) 面前,工人干完活后,产品(计算结果)立刻、直接地流向下一个需要它的工人。
整个过程尽量绕开或者减少使用那些小仓库(缓存)。数据像在一条高速、直达的传送带上流动,而不是在多个仓库之间来回搬运。
好处是什么? 大大减少了搬运的次数和时间(降低延迟),同时也省下了搬运所需的力气(降低能耗)。让工人(计算单元)能把更多精力真正用在干活(计算)上,效率自然就高了!
总结一下核心区别:
传统芯片: 数据需要“反复存取”在缓存里(像在多个仓库间搬运),导致延迟高、能耗大。
AI原生数据流架构: 数据在计算单元之间“直接流动”(像在流水线上直达),尽量减少缓存的搬运,从而降低延迟、节省能耗。
这种“周密编排数据流架构”是专门为AI计算的特点设计的(AI任务通常涉及大量连续的数据流和特定的计算模式),所以称为“AI原生”。
它让数据流动更智能、更高效,就像给数据修了直达高铁,而不是让它在普通公路上频繁换乘中转站。