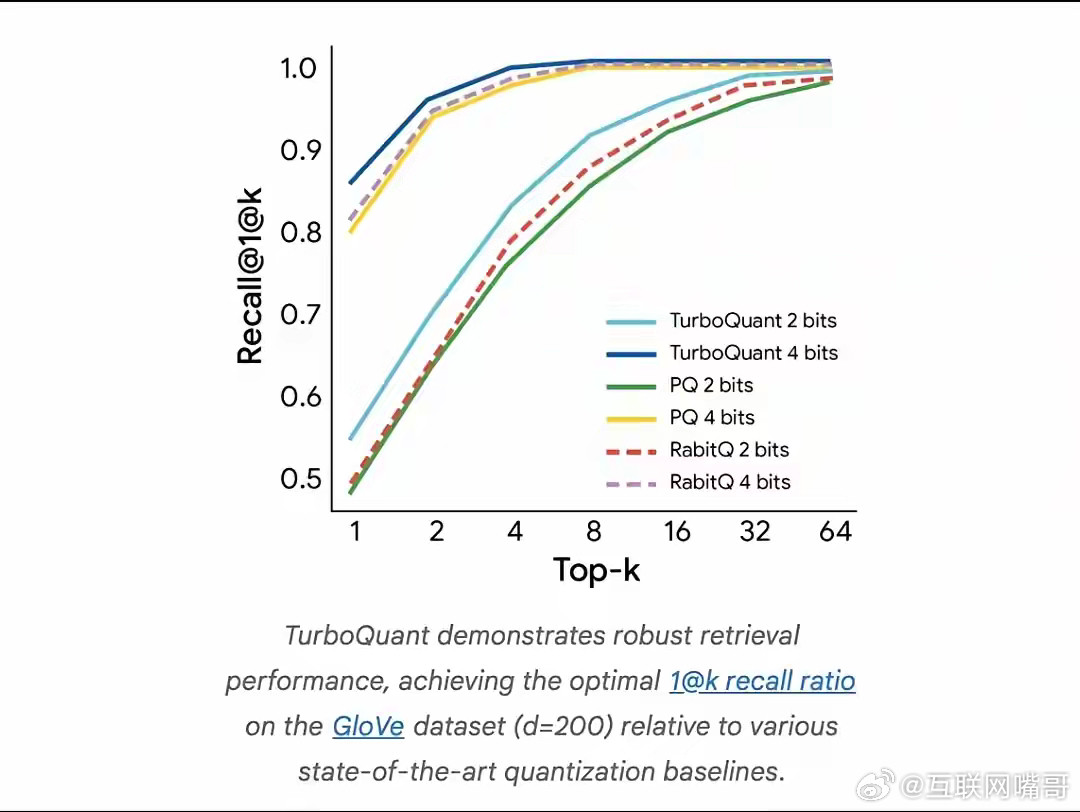
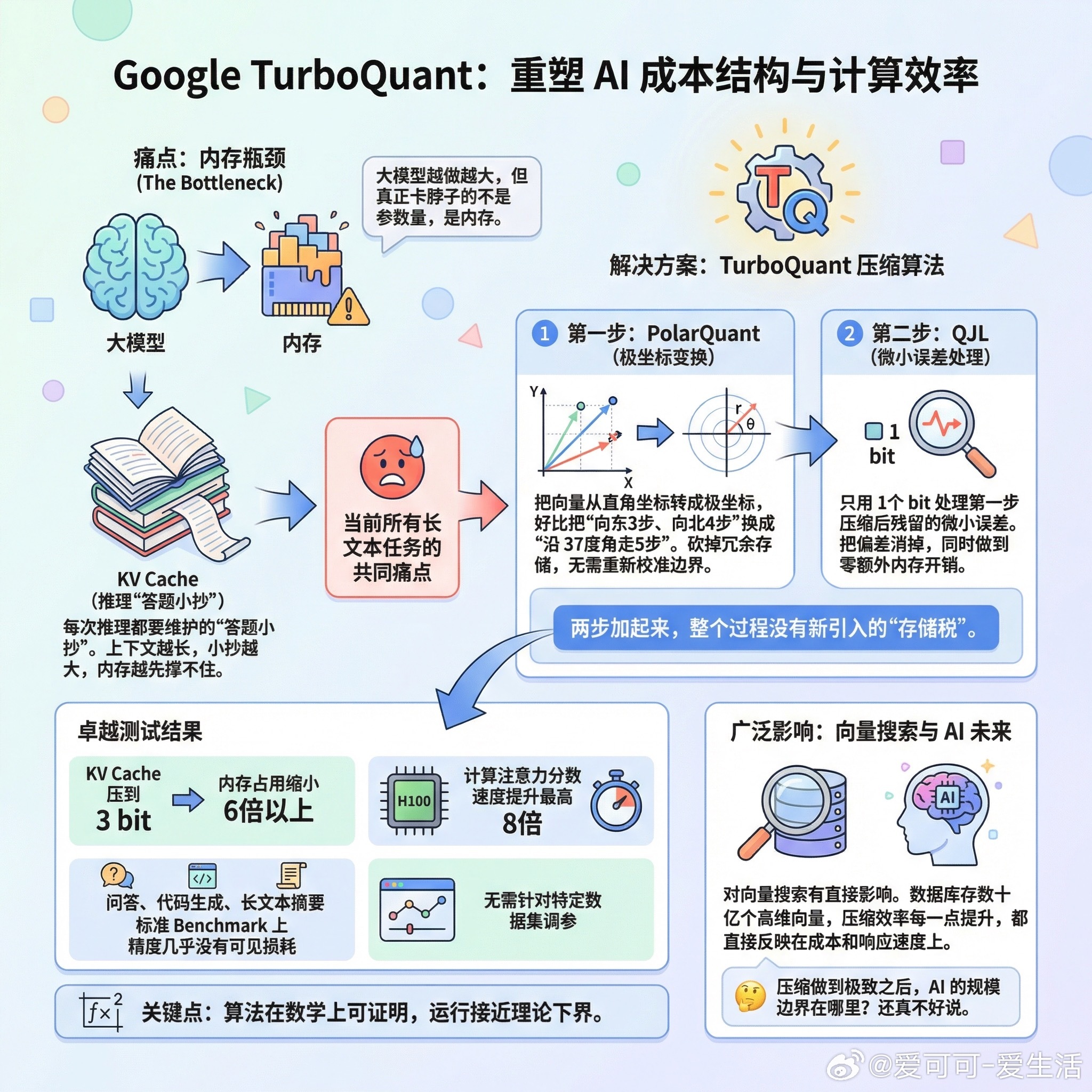
谷歌近日公布了一种名为TurboQuant的新型压缩算法,该技术有望显著降低人工智能系统的内存需求。TurboQuant主要针对大语言模型和向量搜索引擎中,因上下文窗口增大而成为内存瓶颈的“键值缓存”进行优化。该算法能在不重新训练模型的情况下,将键值缓存压缩至3bit精度,且基本保持模型精度不受损。测试显示,其对部分主流开源模型可实现约6倍的内存压缩效果,在特定硬件上性能提升最高可达约8倍。研究人员表示,该技术亦可应用于提升大规模搜索引擎的向量检索能力,计划在4月的ICLR 2026会议上进行展示。(财联社)