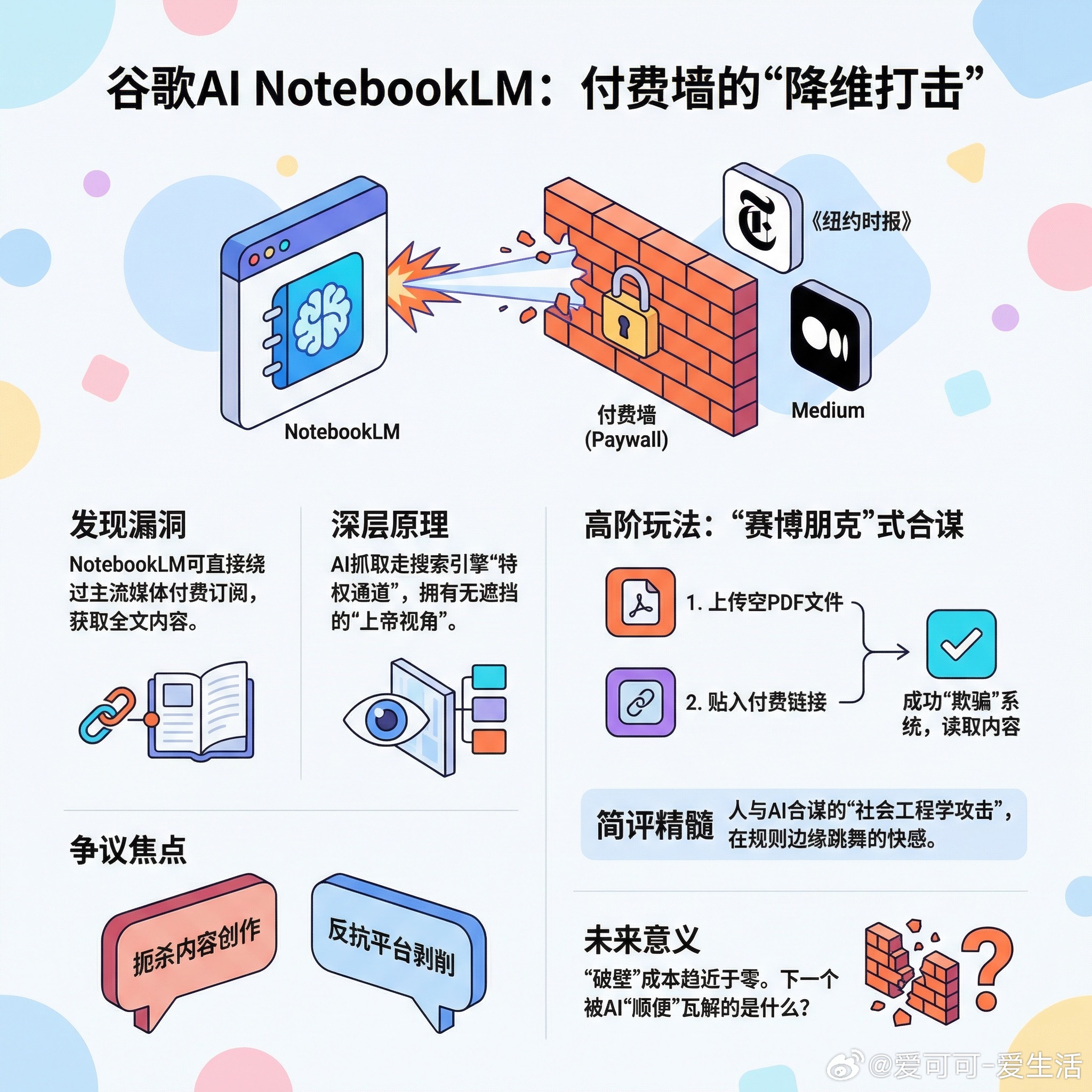
美团又发新模型啦。原生多模态模型LongCat-Next,一个模型同时支持文字、语音、图像输入与输出。
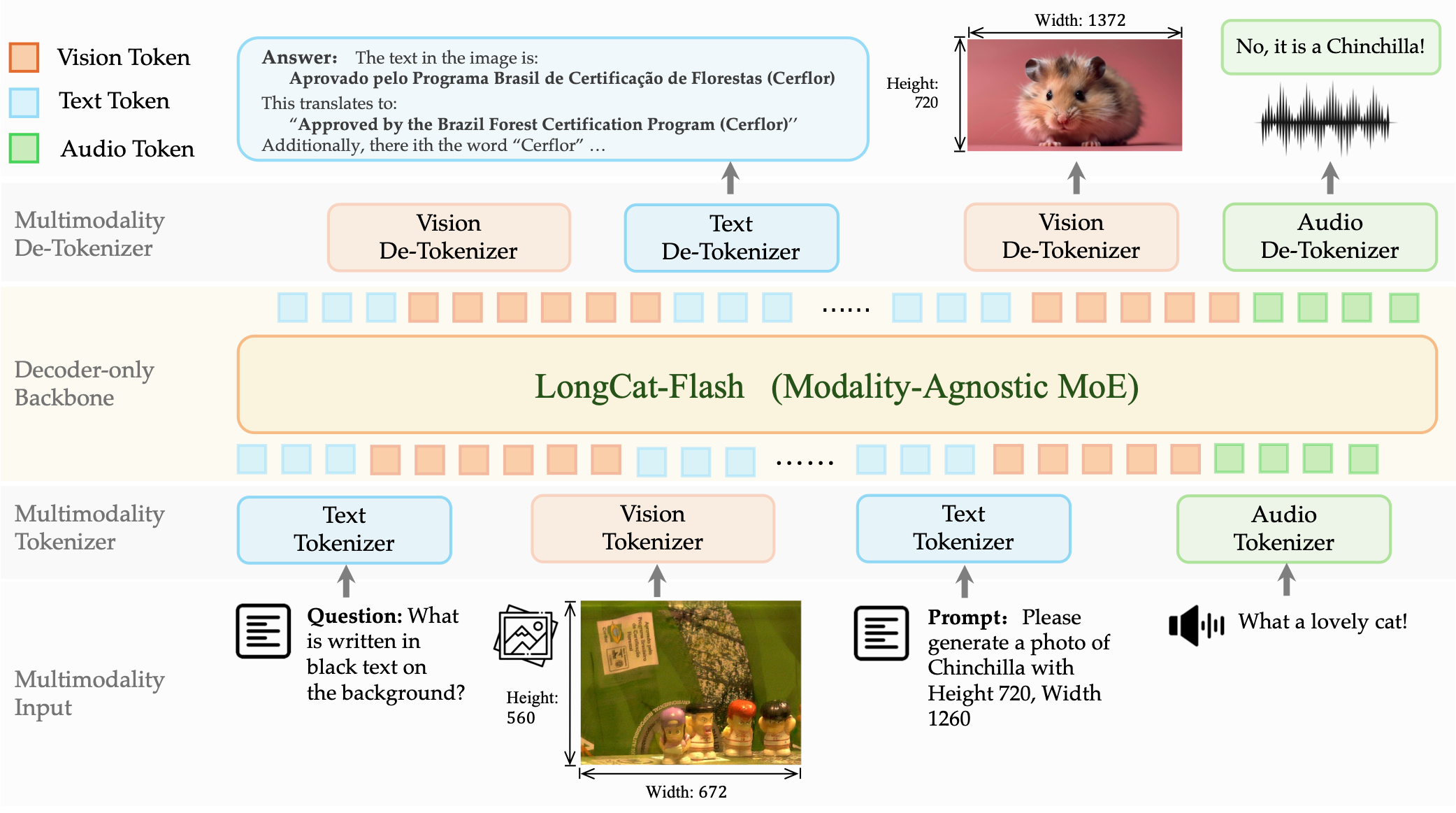
传统多模态模型通常是语言模型 + 外挂视觉/语音模块,也就是图像先经过视觉编码器,变成连续向量,再投影进 LLM;图像生成又常常另用 diffusion/DiT;语音也有自己一套 codec 和分支。结果就是架构割裂,理解和生成往往不是一套系统。
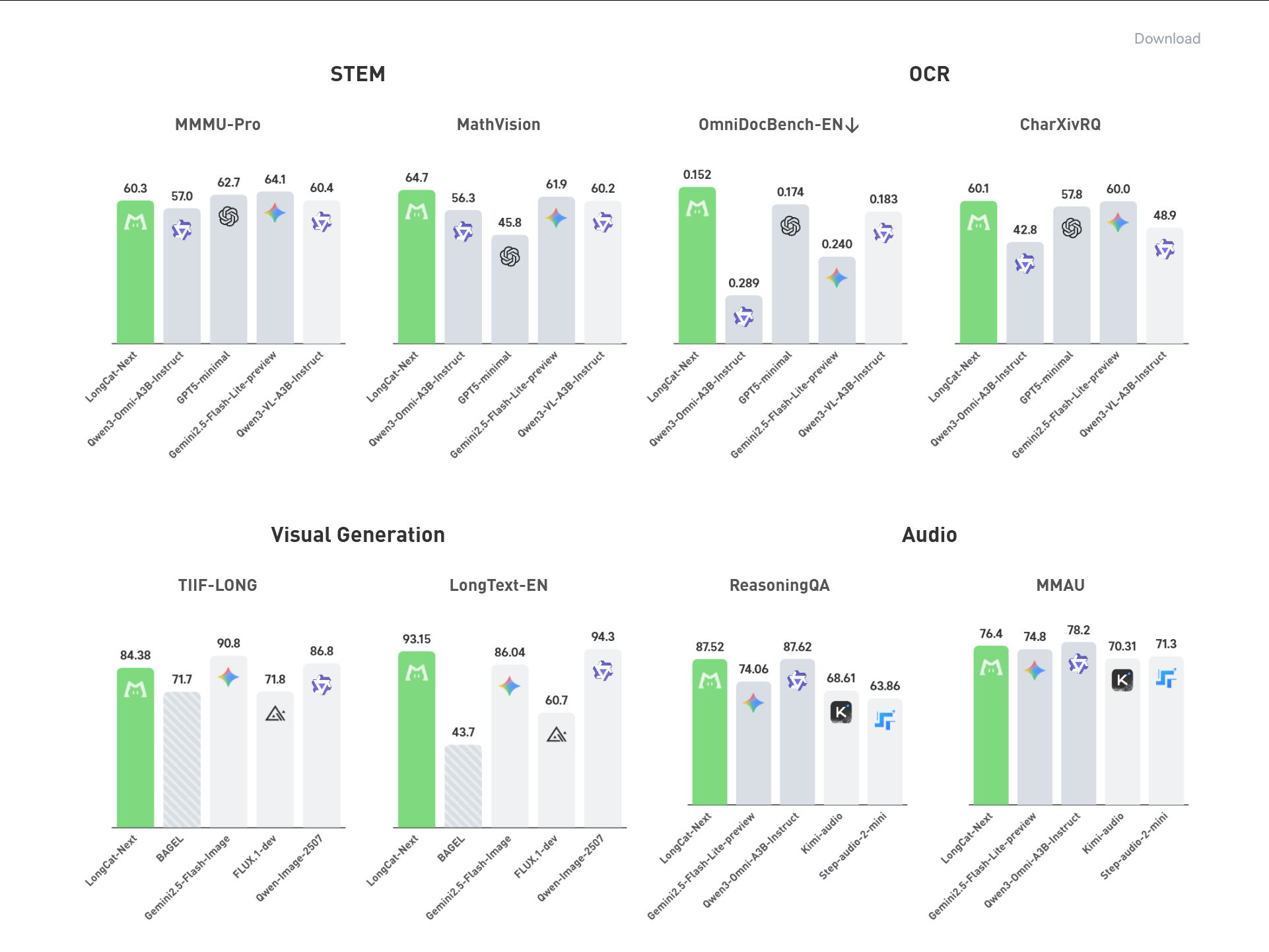
LongCat-Next 提出的 DiNA想把这件事统一掉,文本、图像、音频都先变成离散 token,进入同一个 decoder-only 主干模型。这样 OCR、图像理解、文生图、语音理解、语音生成,本质上都变成预测下一串 token。How I AI

![一觉醒来王兴交出一份离谱成绩单[笑着哭]2025年,美团净亏234亿王兴:我](http://image.uczzd.cn/9609914347866046492.jpg?id=0)