[CL]《Online Experiential Learning for Language Models》T Ye, L Dong, Q Dong, X Wu… [Microsoft Research] (2026)
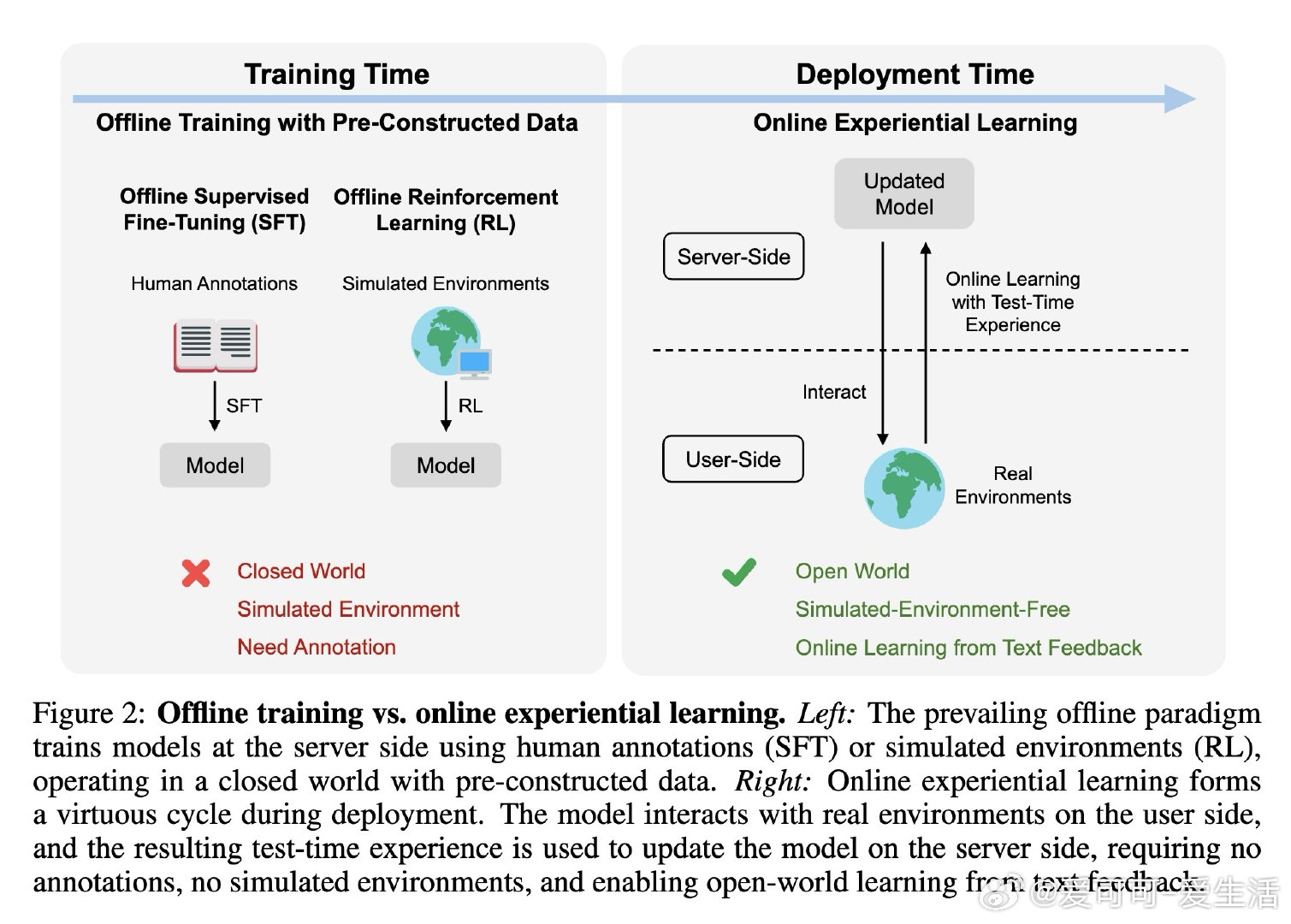
在文本游戏领域,大语言模型部署后积累的真实交互经验被完全丢弃——模型一旦上线即成静态,只能依赖上线前标注的数据或模拟环境,无法从持续涌入的用户反馈中学到任何东西。问题的本质在于:训练侧无法访问用户侧环境,且真实反馈是非结构化文本而非标量奖励,传统强化学习无从消化。
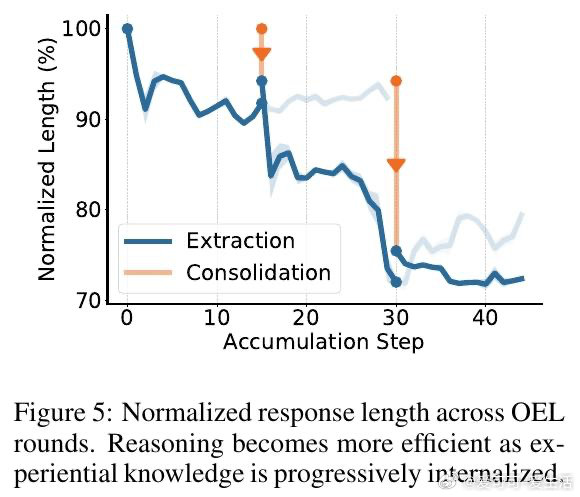
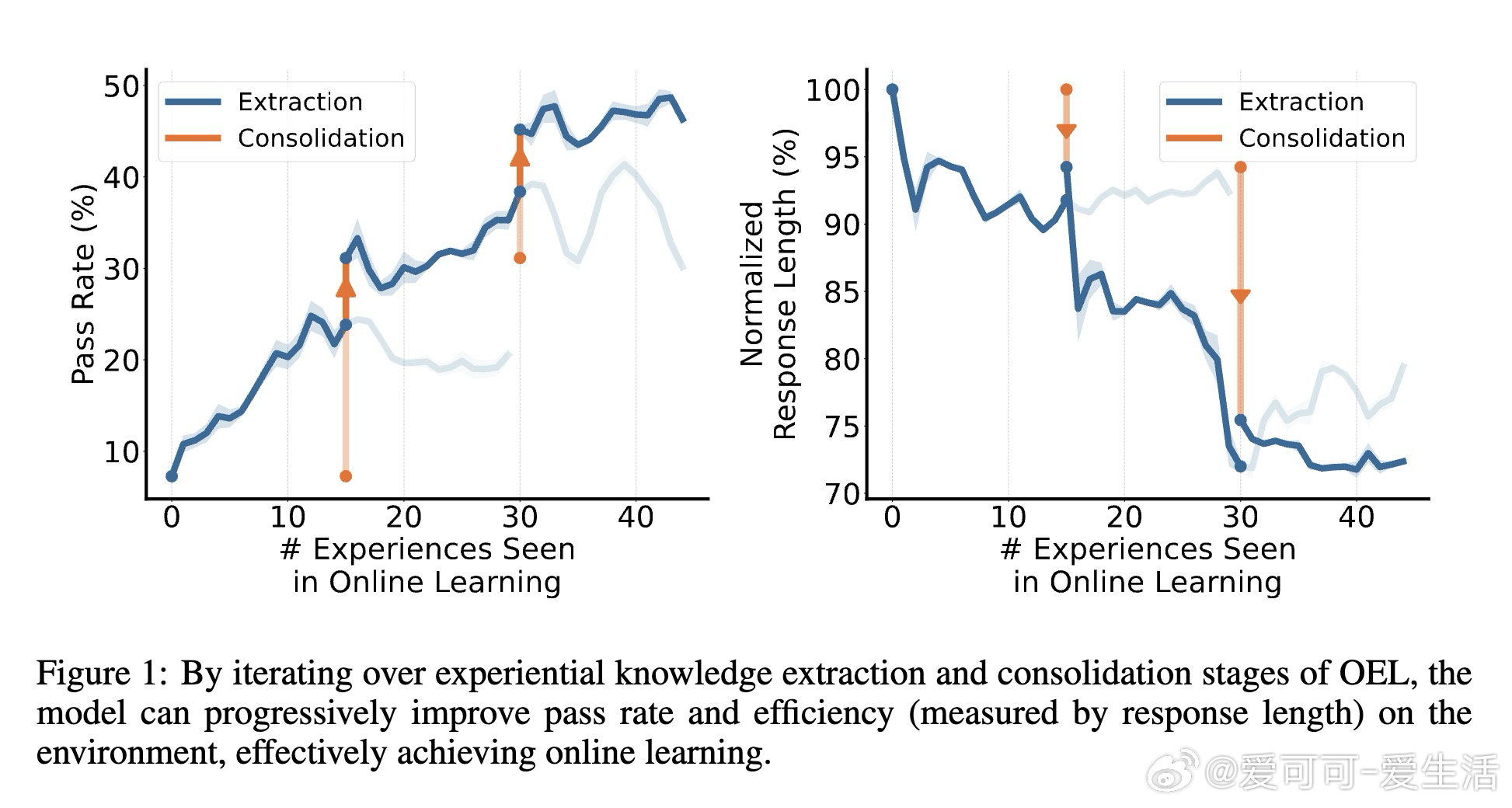
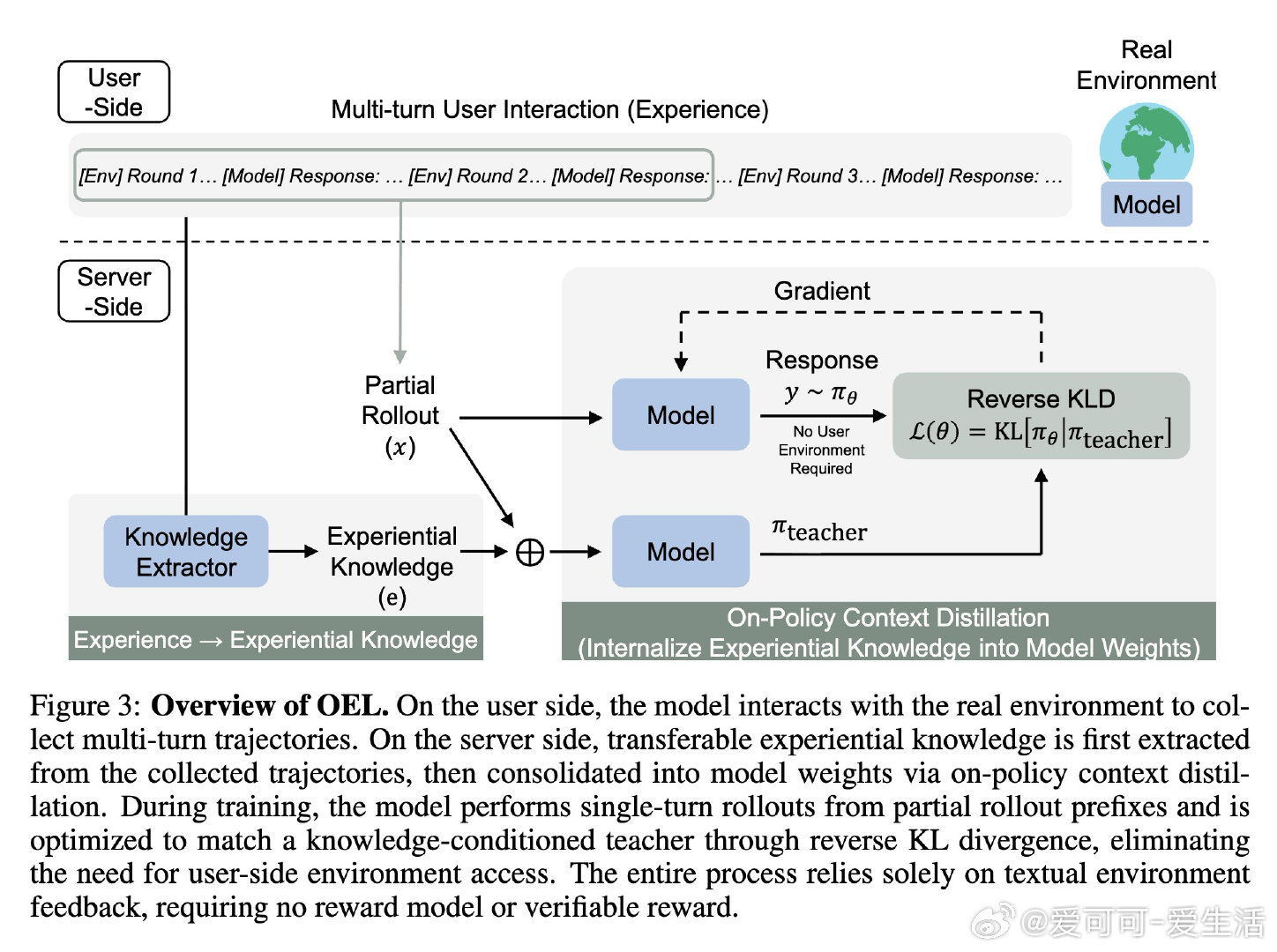
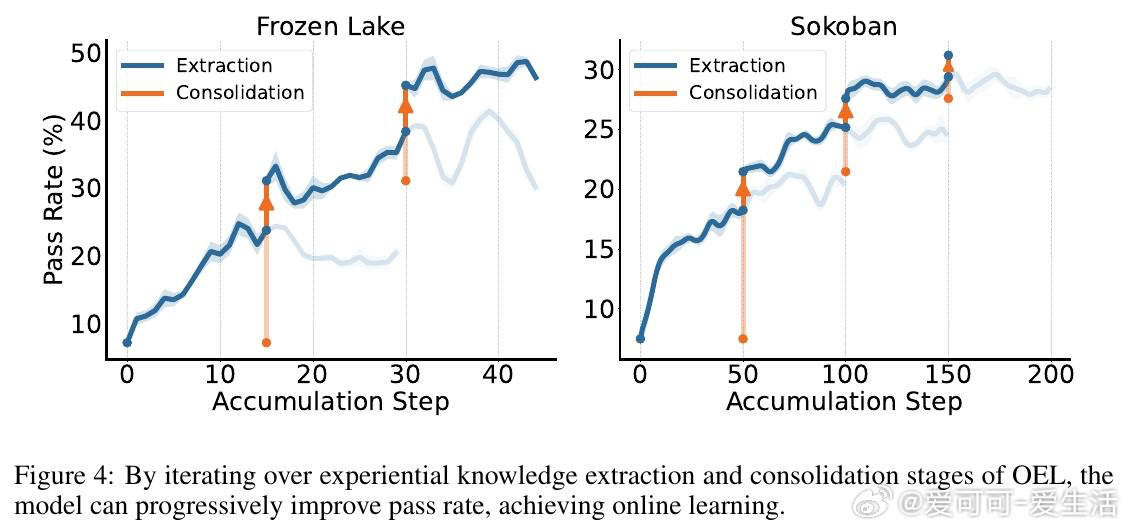
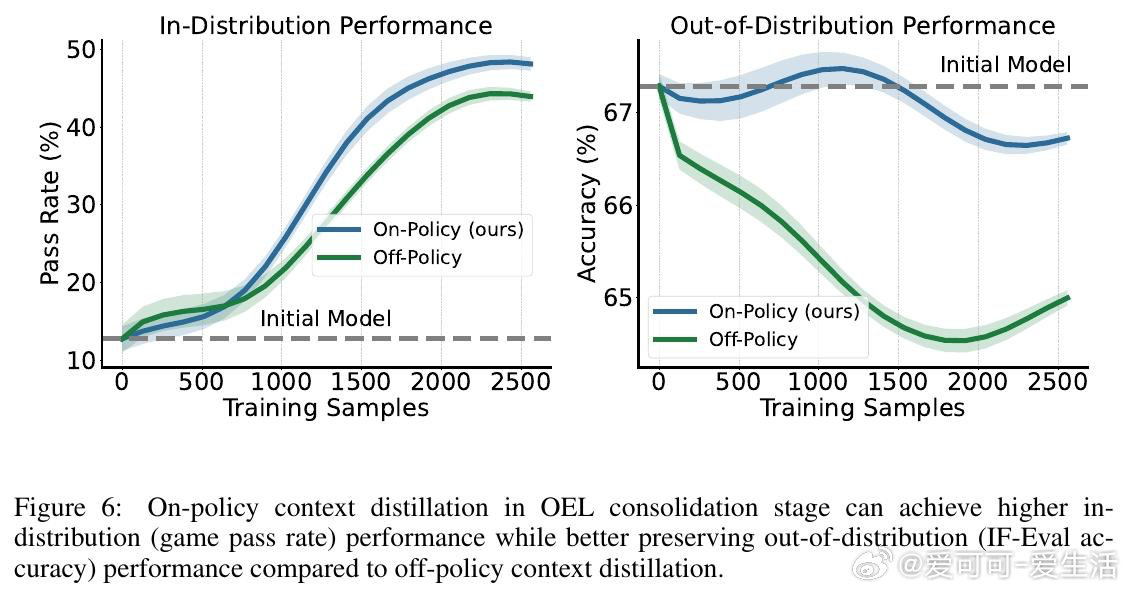
本文的核心洞见是:把"原始交互轨迹"重新看作"可提炼的经验知识"。由此,一个两阶段循环得以成立——先让模型自己从轨迹中归纳出可迁移的策略条目,再通过同策略上下文蒸馏(反向KL散度)将这些知识压进权重,训练全程无需访问用户环境、无需奖励信号。更强的模型产出更高质量的轨迹,提炼出更精炼的经验,驱动下一轮蒸馏,形成自举闭环。
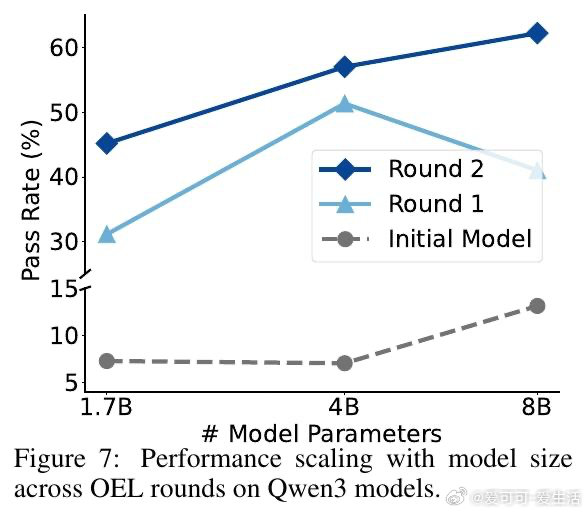
这项工作真正留下的遗产是:证明了"部署即学习"的闭环在无奖励、无环境访问条件下切实可行,且同策略一致性(用自己的轨迹提炼自己的经验)是知识能否内化的关键变量。它为后来者打开的新门是将在线经验学习推广至开放域对话等更复杂场景。但尚未跨过的门槛是:实验仅限于规则明确的文本游戏,经验提炼质量高度依赖模型自身能力,小模型从强模型轨迹中学习的路径尚未打通。
arxiv.org/abs/2603.16856
机器学习 人工智能 论文 AI创造营