【500行C代码,把Transformer的神秘感彻底杀死】
有人用纯C从零实现了一个GPT,没有PyTorch,没有autograd,连numpy都没有。前向传播、反向传播、Adam优化器、文本采样,全部手写。
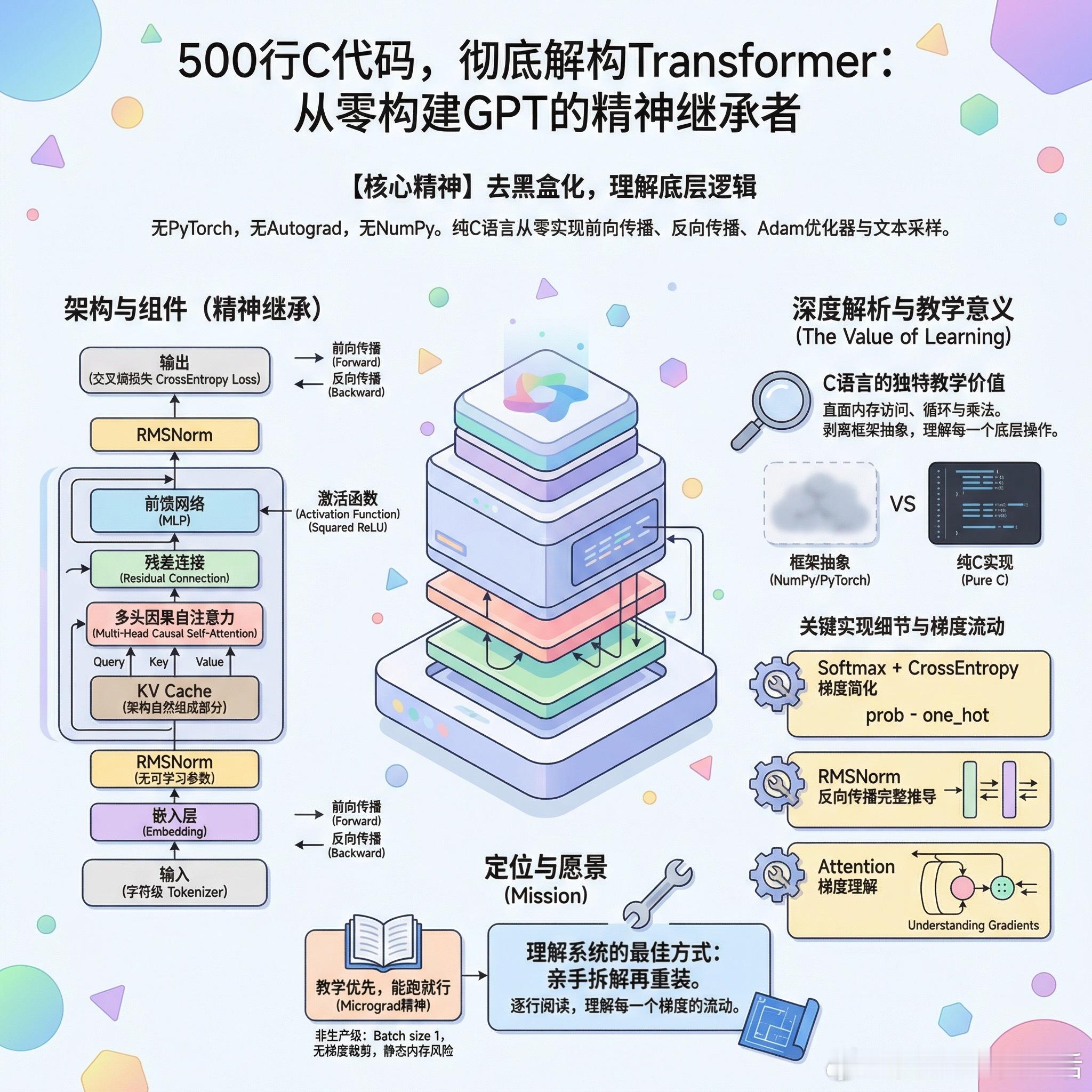
严格来说这不是GPT的架构复刻,而是精神继承。没有可学习参数的LayerNorm,用的是RMSNorm;激活函数是Squared ReLU而非GELU;tokenizer是字符级的,不是BPE。但核心机制一个不少:embedding、多头因果自注意力、残差连接、MLP、交叉熵损失。
这篇文章真正的价值在于:它把transformer从黑盒API调用变成了你能用for循环和指针算术理解的东西。
当你看到attention就是两层嵌套循环做点积再softmax再加权求和,当你看到backprop就是把这些操作反过来一步步算偏导,那种"这玩意儿到底在干嘛"的困惑就消失了。
用C而不是Python来做这件事有独特的教学意义。numpy的广播和PyTorch的autograd隐藏了太多细节,C强迫你面对每一次内存访问、每一次循环、每一次乘法。框架让你高效,但也让你无知。
几个值得注意的实现细节:softmax加交叉熵的梯度简化被清晰展示了,就是那个经典的prob减one_hot;RMSNorm的反向传播推导是很多人会卡住的地方,这里给出了完整实现;KV cache不是作为优化技巧引入,而是作为架构的自然组成部分。
当然这不是生产级代码。batch size是1,梯度噪声极大;静态内存分配在某些系统上可能直接栈溢出;没有梯度裁剪。但教学代码的目标从来不是能用,而是能懂。
Karpathy的llm.c是这个方向的标杆,工程质量完全不在一个量级。这篇更像是micrograd精神在C语言中的投射:教学优先,能跑就行。
如果你想真正理解attention的每一个梯度是怎么流动的,这篇值得逐行读一遍。理解一个系统最好的方式,永远是亲手把它拆开再装回去。
x.com/TheVixhal/status/2022734079167467711