北京智源人工智能研究所大模型,Deepseek之后再上《Nature》正刊
北京智源2018年成立,首任理事长是著名学者黄铁军,也是文章通讯作者。前段时间我正好调研了,没想到2026年1月28日发了大文章。
这个文章的突出特点就是简单,推出的Emu3大模型,文本、视频、图像全用统一架构处理了。证明了一句话:
Next-Token Prediction is All You Need.
说实在的,挺出人意料的,真的是越简单越强大。其实Attention架构特点就是简单,比以前的encoder-decoder架构简单。而简单的效果是有利于并行,规模可以做到很大,量变最后就质变了。
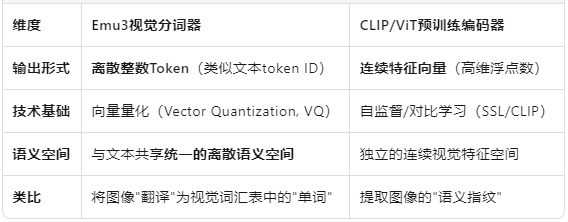
文本大模型架构简单,图像和视频可不简单。人们直觉会是,图像比文字复杂,更不要说视频。以前是需要CLIP/ViT预训练编码器,把图像视频输入转换印射,有一个独立的连续视觉特征空间,架构复杂。
Emu3反直觉的是,用32768种label,就能把所有图像和视频用tokenizer,变成和文本完全一样处理了!文本需要15万种,视觉token反而只要3万多种。词汇表合并了,架构就简单多了。再证明效果是SOTA,就能上《Nature》了。
最关键的区别,以前的“多模态大模型”,依赖预训练好的视觉模型(冻结权重),然后再参与大模型训练,这显得不太自然。Emu3把文本、图像、视频不区分变成token以后统一训练了,为什么能成功,就挺神奇的。
这个发现有哲学意味。说明人类理解图像视频,其实不是用复杂的像素组合,而是类似词汇那样,用几万种特征来理解的。例如有意义的色彩类别仅数千种,而不是RGB组合的上百万种。人类用几何特征,如边缘、角点、纹理来组合识别物体,而不是用无数种像素组合。32768种视觉符号其实够用了,这就是对人类视觉系统的震憾发现。