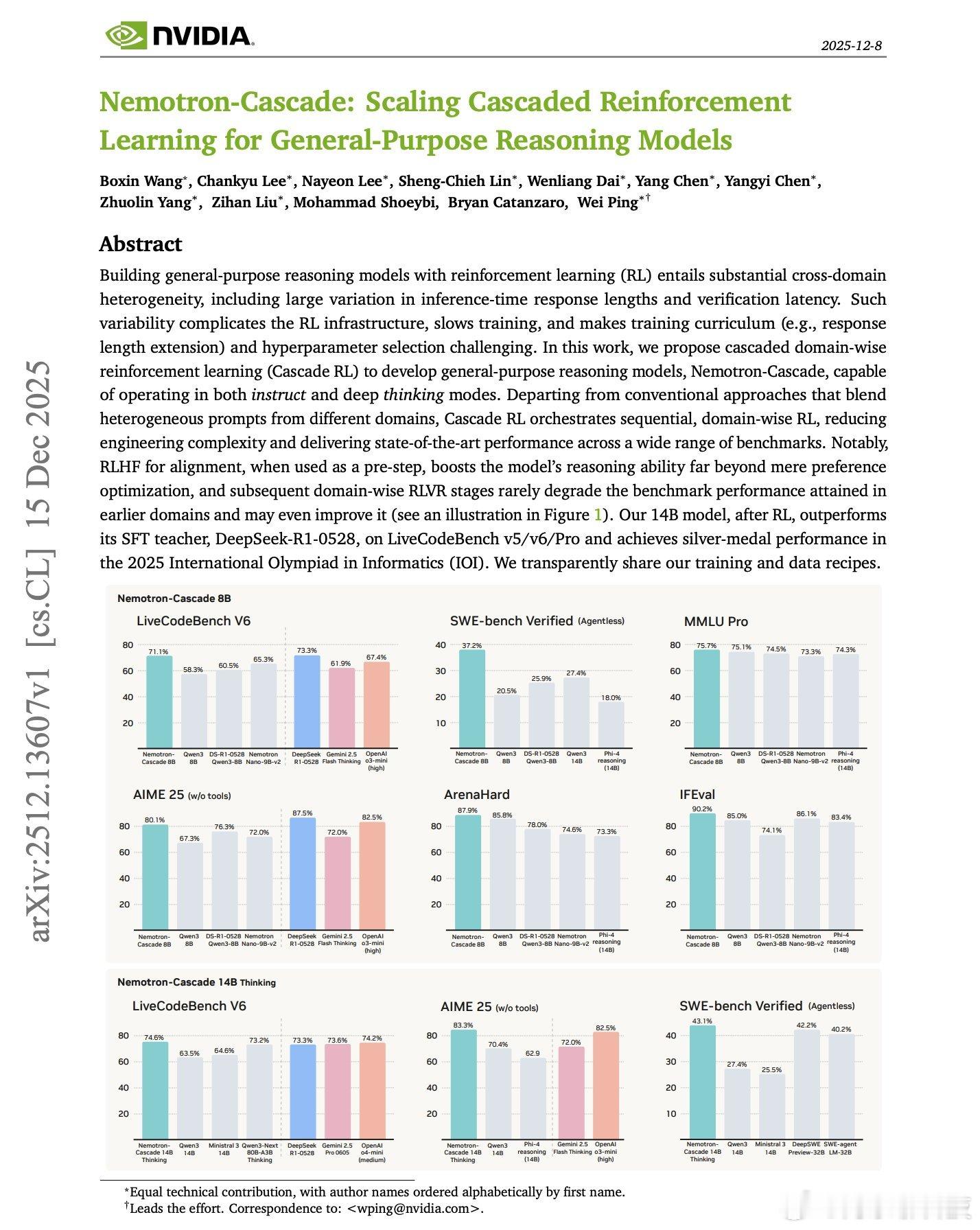
NVIDIA 的这篇论文太棒了。利用强化学习训练通用推理模型非常复杂。不同领域的响应长度和验证时间差异巨大。数学使用快速的符号验证,而代码则需要耗时的基于执行的验证,对齐需要奖励模型评分。将所有这些异构提示混合在一起,会使基础设施变得复杂,减慢训练速度,并使超参数调整变得困难。这项新研究引入了级联强化学习(Cascade RL)框架,该框架按顺序跨领域训练模型,而不是将所有模型混为一谈。首先是用于对齐的强化学习高斯过程(RLHF),然后是指令跟随强化学习,接着是数学强化学习,然后是代码强化学习,最后是软件工程强化学习。这种顺序方法能够有效避免灾难性遗忘。在强化学习中,模型会生成自身的经验,因此只要旧的行为仍然与奖励相关,它们就会被保留下来。与监督学习中先前的数据会消失不同,强化学习优化的是累积奖励,而不是精确地拟合目标值。作为预备步骤,RLHF 通过减少冗长和重复,显著提升了推理能力,远超单纯的偏好优化。后续的领域特定强化学习阶段很少会降低之前的性能,甚至可能有所提升。以下是结果:他们的 14B 模型在 LiveCodeBench v5/v6/Pro 测试中表现优于其自主研发的 SFT 教师模型 DeepSeek-R1-0528(671B)。Nemotron-Cascade-8B 在 LiveCodeBench v6 测试中取得了 71.1% 的成绩,与 DeepSeek-R1-0528 的 73.3% 成绩相当,尽管其体积仅为 DeepSeek-R1-0528 的 1/84。14B 模型在 2025 年 IOI 大赛中荣获银牌。它们还证明,统一推理模型可以在思考模式和非思考模式下有效运行,缩小与专用思考模型之间的差距,同时将所有内容保持在一个模型中。论文: arxiv.org/abs/2512.13607ai生活指南ai创造营