MiniMax实习生炼成屠榜模型屠榜开源榜MiniMaxM2技术解析
屠榜开源大模型的MiniMax M2是怎样炼成的?
为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了?
现在的大模型社区,可谓是被M2的横空出世搞得好不热闹。
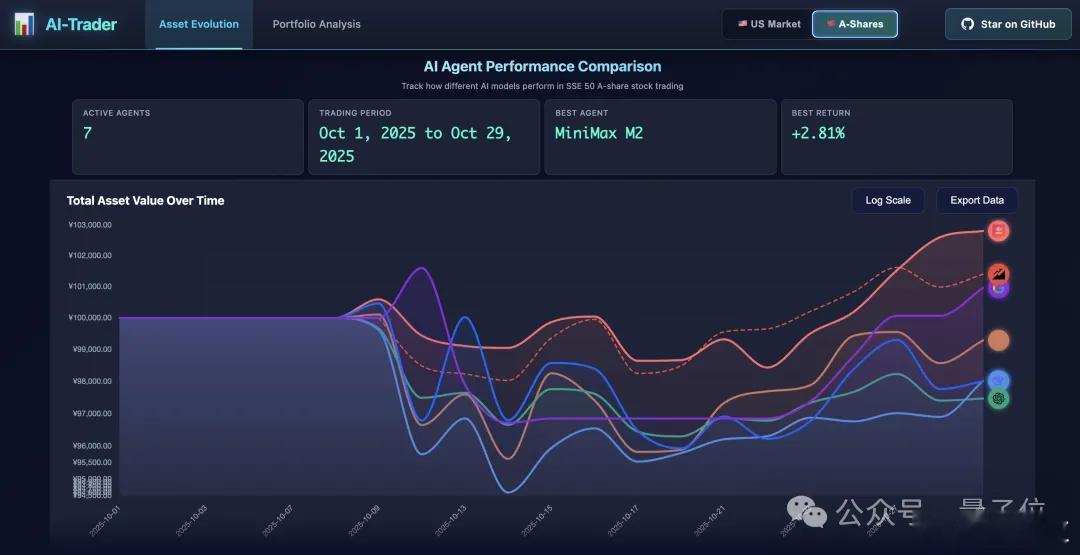
面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。【图1】
而之所以能够站在聚光灯下,还有一个原因是M2身上着实有不少奇招。
除了注意力机制“回归传统”,M2在数据处理、思考模式上也是另辟蹊径,给开源社区带来了不一样的技术路径。
而且MiniMax还公开了这些招数背后的“棋谱”,接连发布三篇技术博客,将M2的技术细节娓娓道来。
博客一发布,本已讨论得热火朝天的大模型社区变得更热闹了,不乏有大佬给出自己的分析。
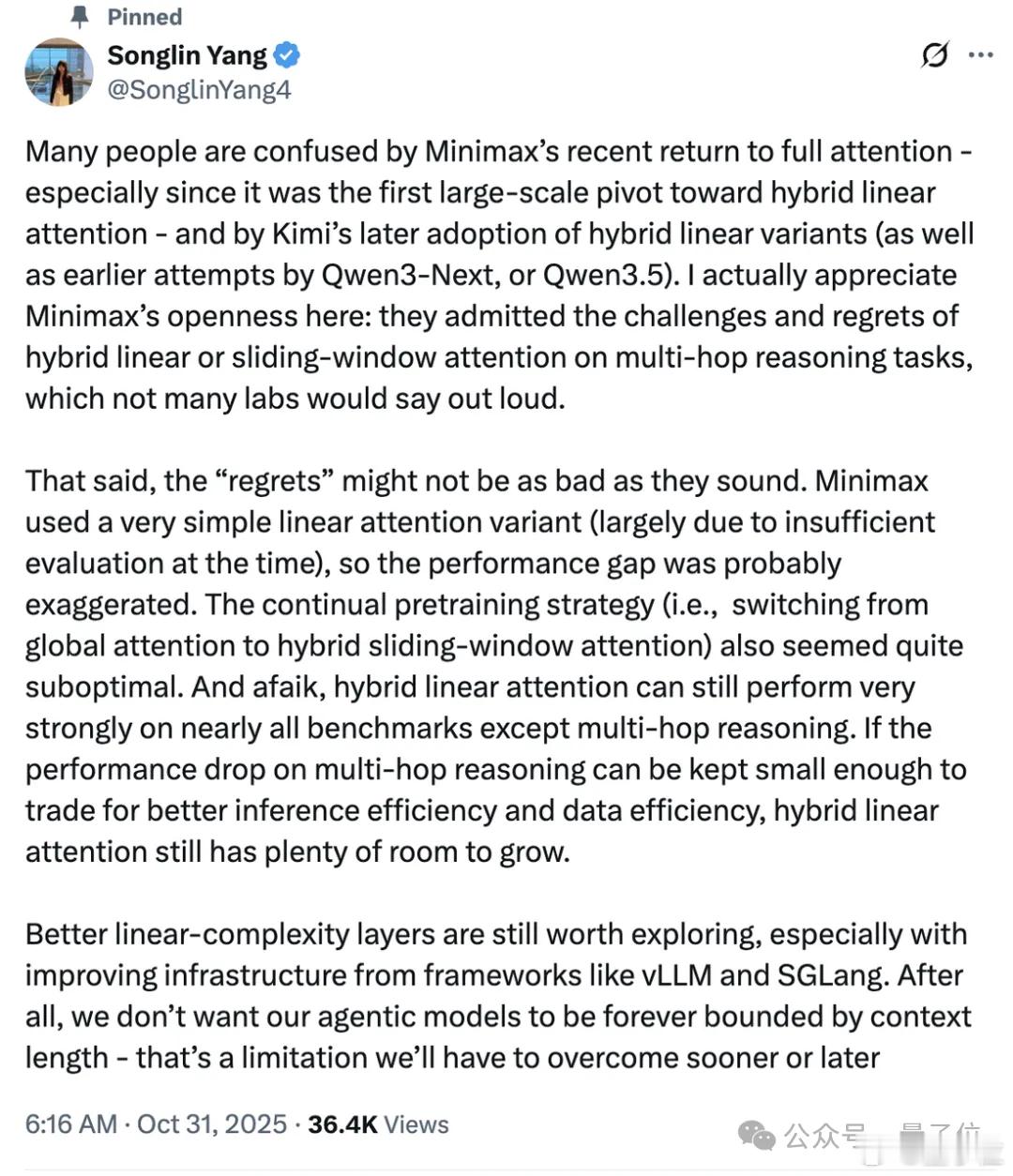
其中也包括质疑的声音,比如Thinking Machine Lab技术人员Songlin Yang就表示——
MiniMax团队敢于揭露Linear Attention的不足这点值得肯定,但他们的测试有问题,低估了Linear Attention的实力。【图2】
实际上,注意力机制的选择,也确实是M2相关问题当中最热门的一个。
M2团队选择的理由究竟是什么?三篇技术报告揭开了哪些秘密?
快搬起小板凳,我们一点点往下看: