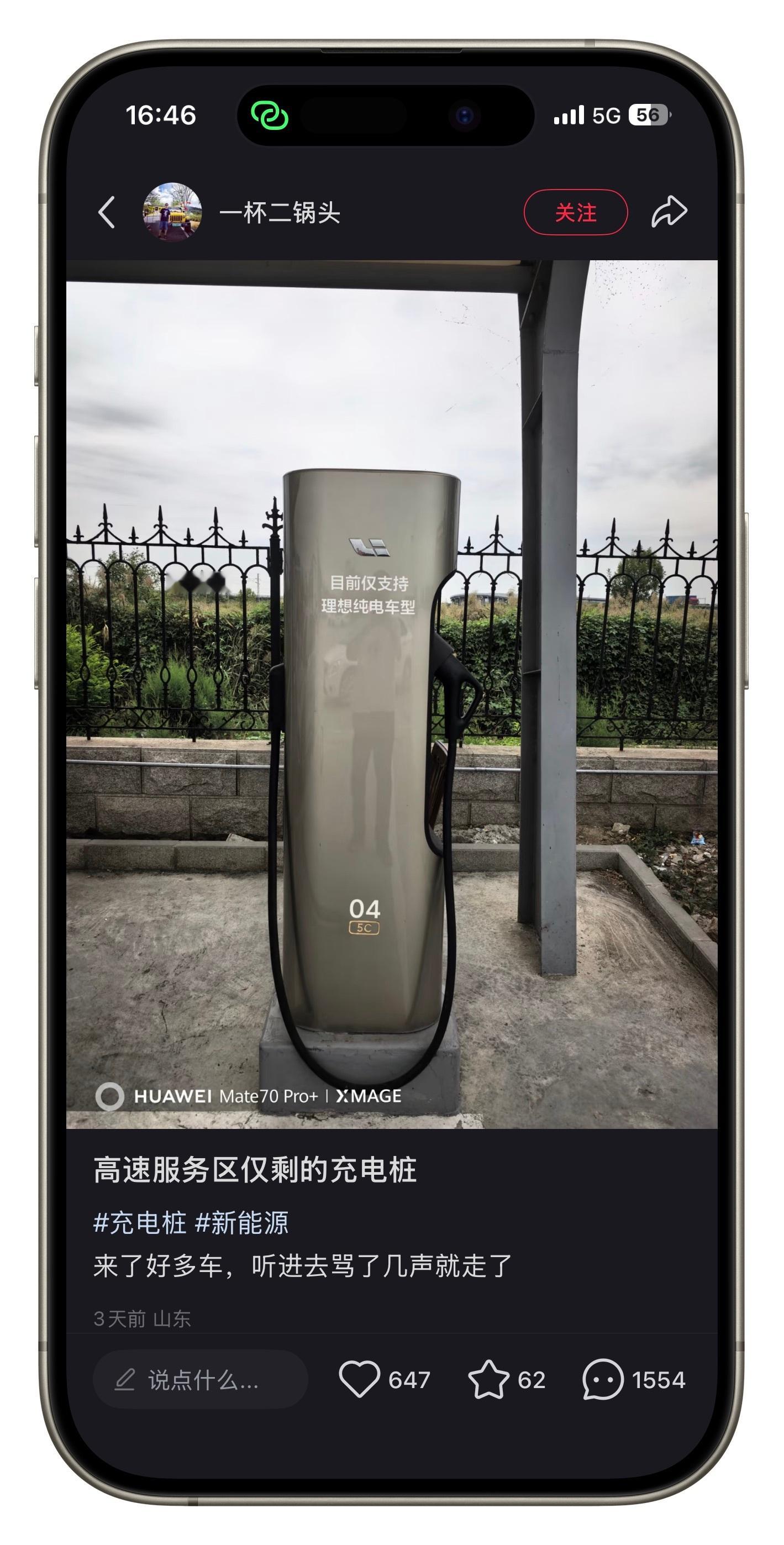
晚点写蔚来的文章这段有意思:
-晚点:理想的智驾负责人曾说,他们从 80 万车主中,筛选 3% 老司机的驾驶数据来训,从而让模型做到和老司机一样的驾驶体验。你们也是这样做的么?
任少卿:其实我们不是。这是个很有意思的话题,你先回答我,到底我们需不需要车撞了的数据?
-晚点:当然需要了。
任少卿:为什么呢?如果是专家数据就不会有这东西,因为专家开的都很标准。
-晚点:不一定,很多老司机开车就非常激进。所以如果用海量用户数据训练,和用专家数据训练,效果会有什么差别?
任少卿:那我们先要明确自己要什么,最基础的是两块:语言模型带来的是「概念认知」,世界模型带来的是「时空认知」。把这两块拼在一起,最后才会走向 AGI。
基于这个框架,数据的选择就分成两种:专家数据,干净,质量高,但量小、贵。比如找 300 个老司机开,采得很标准,但你没法找 3 万个。
量产数据,量大、成本低,分布广,什么情况都有——开得很标准的、有点冒失的,甚至有事故的。这样模型才能学会 「什么情况下会出错」。
但专家数据的弊端是缺少 corner case(极端/边界情况),不标准的情况都被过滤掉了。但真实世界恰恰充满这些边界情况。量产数据虽然「脏」,但通过强化学习去 「洗」,反而能让模型学到更多、更复杂的东西。
-晚点:当时很多厂商从规则往模型切的时候,用户会觉得,使用智驾的体验却变得更差了。我之前以为是模型「学老司机学坏了」。你怎么解释这个「倒退」现象?
任少卿:我们发现一个特别有意思的例子,在小路上的驾驶场景。智驾车在小路上很容易遇到边界情况:车距很近,你得减速,还得打方向。如果是用专家数据,或者专家数据加一堆规则训出来的,这个场景就不容易做到丝滑。经常会一出边界,就切到兜底规则,车就 「一顿一顿」 的,体验很差。
我们在今年 5 月份推的版本,几乎没这个问题。因为我们用了大量的真实数据,里面既有非常标准、安心的驾驶,也有离其他车很近的情况。加上强化学习训练之后,整个系统在边界场景下也能连贯,不容易掉到兜底逻辑里。
-晚点:所以这里有一个核心,就是「强化学习」。我记得当时训语言模型的时候大家也遇到过类似问题:干净数据 vs 大量脏数据。
任少卿:以前的小数据集,比如李飞飞老师 2010 年搞的 ImageNet,100 万张精标图片,花了很多时间去标,质量很高,所以可以用模仿学习——老师做什么,我照抄就行。
大语言模型不一样,它直接把整个互联网的数据灌进去。这些数据洗不干净,里面有很多乱七八糟的、不合适的内容。没办法,量太大了。怎么办?在 GPT-3.5 之前大家是「加规则」——不许输出这些词。
但后来就有了强化学习,它能把「好的分布往前排,坏的往后放」,某种程度上相当于后端洗数据。智驾也一样:专家数据干净但量少,量产数据量大但脏,需要强化学习去洗。
这就是蔚来智驾宣传「小路之王」的原因?



![这背景太假了[doge]在这个停车点刚好停着2台理想,2台蔚来(集团)。这台乐道](http://image.uczzd.cn/14466879432728478182.jpg?id=0)