阿里开源全模态大模型AI音视图文打通了
阿里Qwen开源全模态大模型Qwen3-Omni,图、文、音、视频,我全都要。
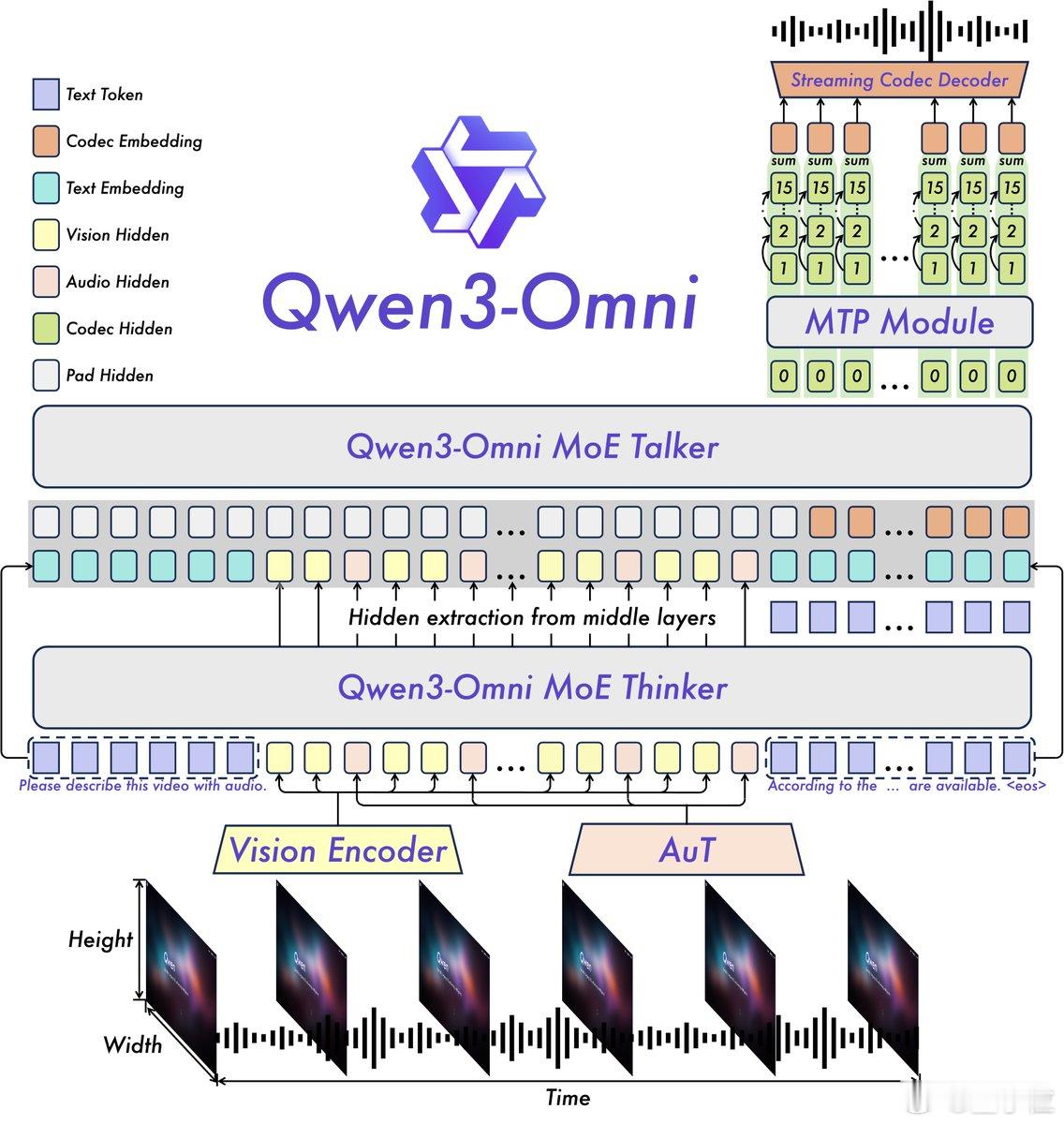
这个事有多恐怖呢?你可以输入音频、图像、文字、视频,甚至是它们的混合!
比如,有时你想输入一张图片和一段视频,让大模型帮你分析出图片变视频的Prompt;
再比如,你想输入一段音频和一段视频,然后找出音频中的台词在视频中的具体位置。
总之,它是目前唯一原生端到端支持多模态输入输出的大模型架构,尚未被发现的玩法有很多。
此次开放的模型包括:
- Qwen3-Omni-30B-A3B-Instruct(指令跟随)
- Qwen3-Omni-30B-A3B-Thinking(中间层输出)
- Qwen3-Omni-30B-A3B-Captioner(音视频理解)
其他亮点总结如下:
- 超低延迟:211ms响应速度,能连续理解长达30分钟的音频
- 自带工具调用功能,可按需接入外部系统能力
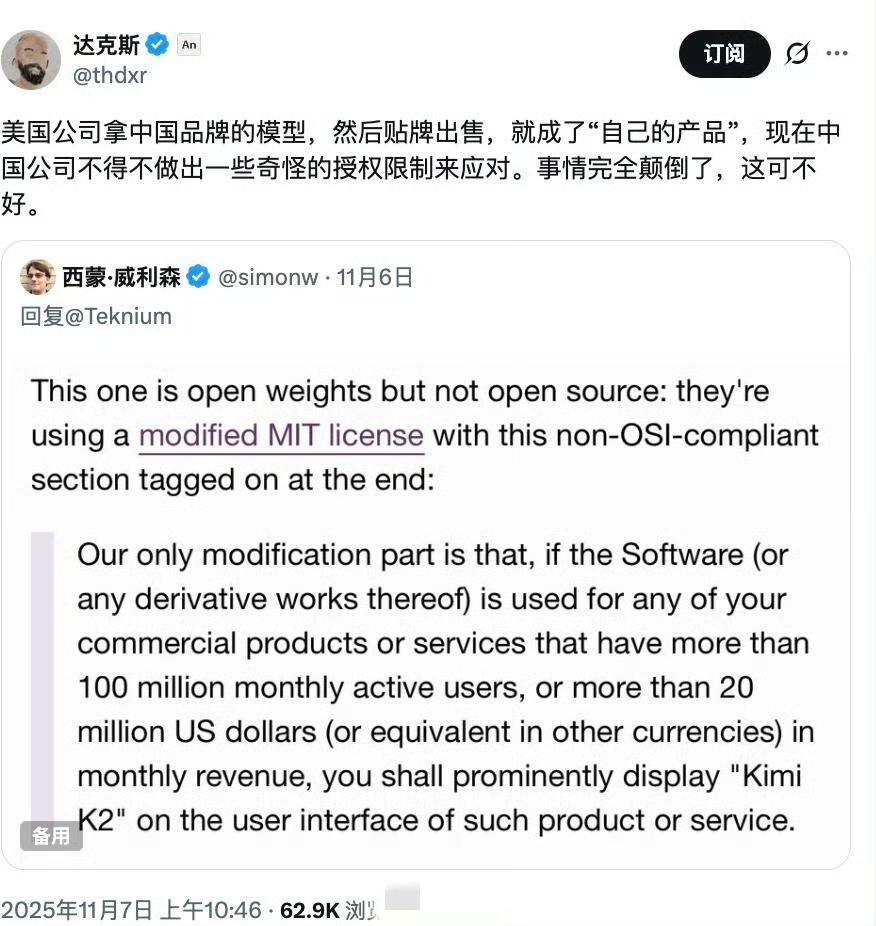
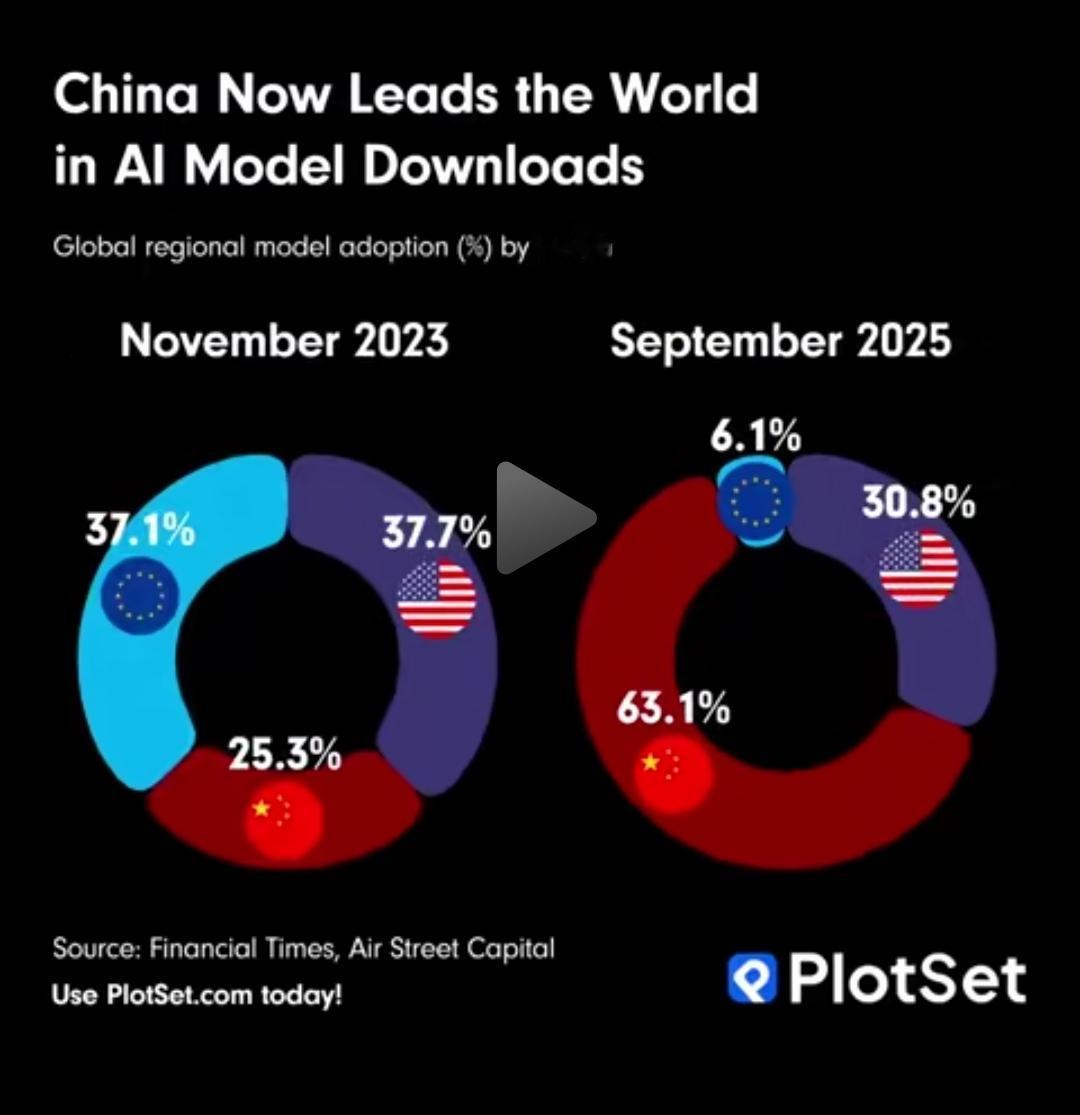
这不仅是一次AI多模态融合的技术突破,也是在全球开源AI竞速中,中国团队的又一次“抢发车”。
体验入口已上线:chat.qwen.ai/?models=qwen3-omni-flash
GItHub:github.com/QwenLM/Qwen3-Omni





大神父王喇嘛
omni个玩意,gpt好几年前就有了,要吹也换个角度吹