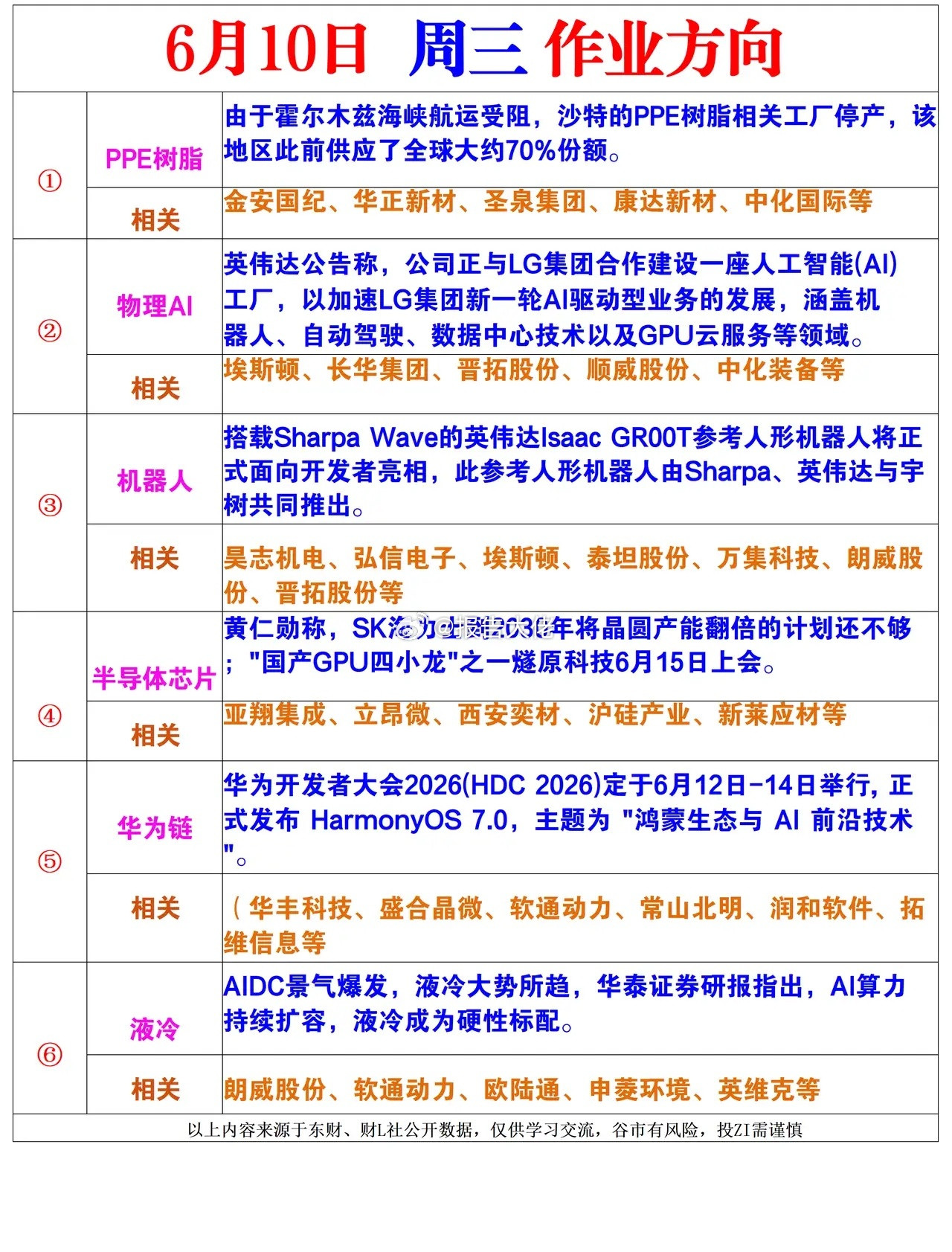
"训练速度快且成本低",非洲开发者集体转向中国AI 美国《外交政策》杂志6月8日发文惊称,中国正在提供"能真正读懂非洲语言的人工智能",文章不得不承认,在被西方科技巨头长期忽视的非洲大陆,一场AI革命正在悄然发生。 由于中国开源模型训练速度更快、成本更低,越来越多的非洲开发者正集体转向DeepSeek、Qwen和Kimi等中国平台。 这不是什么"技术输出",更不是所谓的"数字新殖民",而是非洲开发者用脚投票的结果。 当西方还在为AI的"安全"和"伦理"争论不休时,中国已经把真正能用、好用、用得起的AI工具送到了非洲人民手中。 非洲有多少种语言,你猜得到吗?答案是超过两千种,两千多种活语言,散落在这片全球最大的大陆上,但主流AI大模型能真正"听懂"其中多少?2025年的一项研究发现,在全球主流语言模型里,非洲语言里只有41种得到了支持,剩下超过98%的语言,根本没有任何有效覆盖。 两千种语言,41种被看见,剩下那一千九百多种,就这么被硅谷的精英们无声无息地抛在了数字时代的门外。 谷歌有钱,微软有钱,OpenAI有钱,但他们的模型就是不说卢干达语、不说沃洛夫语、不说奥罗莫语。 这不是技术问题,研究人员早就指出,这是结构性问题,根源在于几十年来数字基础设施投入的严重失衡。 说白了就是:这些语言的用户穷,没有商业价值,西方科技公司不感兴趣,就在这个当口,一个乌干达人做了一件让西方媒体目瞪口呆的事。 SunbirdAI的ErnestMwebaze要开发一个能够理解乌干达31种本地语言的大模型,但他没有去找谷歌、微软或OpenAI,而是在阿里巴巴开发的中国开源模型Qwen3上直接动手。 这个项目叫做Sunflower(向日葵),开发出了Sunflower14B和32B两个版本,可以覆盖乌干达绝大多数本地语言,实现了当地语言AI理解能力的最高水准。 这位研究者不是不知道谷歌、微软的名字,他只是发现在他要解决的问题面前,中国模型更好使、更省钱、还开源免费。 Mwebaze的选择不是个例,非洲开发者已经大规模转向DeepSeek、Qwen、Kimi等中国平台来构建各自语言的AI模型。 在非洲AI领域的权威研究者、QhalaCEOShikohGitau看来,中国平台训练速度快、成本低、还开源,这个组合对开发者来说实在太有吸引力了。 说人话就是:西方平台要么贵,要么不开放,要么根本不管你那几十种小语言死活,中国模型摆在那,直接用,改了就能跑,谁不用谁傻。 另一款中国模型Step3.5Flash的定价已经压到了每百万token仅0.10美元,比GPT-4o便宜约25倍,但数学推理能力却与之相当。 这种价格差放在非洲开发者面前,选哪边还需要想吗?再说开源这件事,在西方AI圈子里,"开源"不一定是真开源,各种使用限制、商业授权门槛,让很多开发者叫苦不迭。 Qwen3.5遵循Apache2.0协议,没有使用限制,可以自由商用、本地部署、二次微调,这对资金有限、计算资源有限的非洲开发者来说,意味着他们可以把模型下载到本地服务器上跑,不依赖任何外部云服务,不受任何商业平台的牵制。 你自己的数据,自己的服务器,自己说了算,这种自主性,对很多非洲国家来说不仅是技术问题,还是数字主权问题。 再回过头来看中国模型为什么在多语言这件事上做得更好,2026年2月,Qwen一个系列的月下载量就达到了1.536亿次,是其他八家主流开源模型厂商总和的两倍还多。 如此庞大的用户基础,意味着全球各地的开发者都在基于Qwen做本地化微调,数据反哺、生态积累,自然越来越强。 这是一个正向循环,西方平台如果持续对非洲语言不上心,差距只会越拉越大,其实中国模型走到今天这一步,本身就是逼出来的。 自2022年美国收紧对华高端芯片出口管制以来,中国AI实验室被迫在软件效率上大下功夫,由此倒逼出了一系列技术突破,而这些突破如今正惠及全球开发者。 美国本来是想卡住中国的脖子,结果逼着中国把模型做得更轻、更快、更便宜,反而帮中国AI打开了发展中国家的市场。 这剧情,说是"搬起石头砸自己的脚"也不为过,西方媒体发现这件事之后,第一反应是给它贴标签,有人说这是"数字新殖民",有人说这是"技术输出战略",好像非洲人自己没有判断力,被中国牵着鼻子走一样。 但真实情况是怎样的?非洲AI研究者明确说了,开发者会选择最适合自己需求的技术,目前为止,那个答案就是Qwen、DeepSeek和Kimi。 没有人逼他们,没有补贴、没有政治交换,纯粹就是因为好用。 当西方科技公司在全球AI伦理峰会上讨论"如何负责任地开发AI"的时候,中国的开源模型已经悄悄跑在乌干达程序员的笔记本电脑上,帮他们的农民用母语查询病虫害防治方法了。


![不可能有这种情况吧[捂脸哭]](http://image.uczzd.cn/7210742256315846152.jpg?id=0)