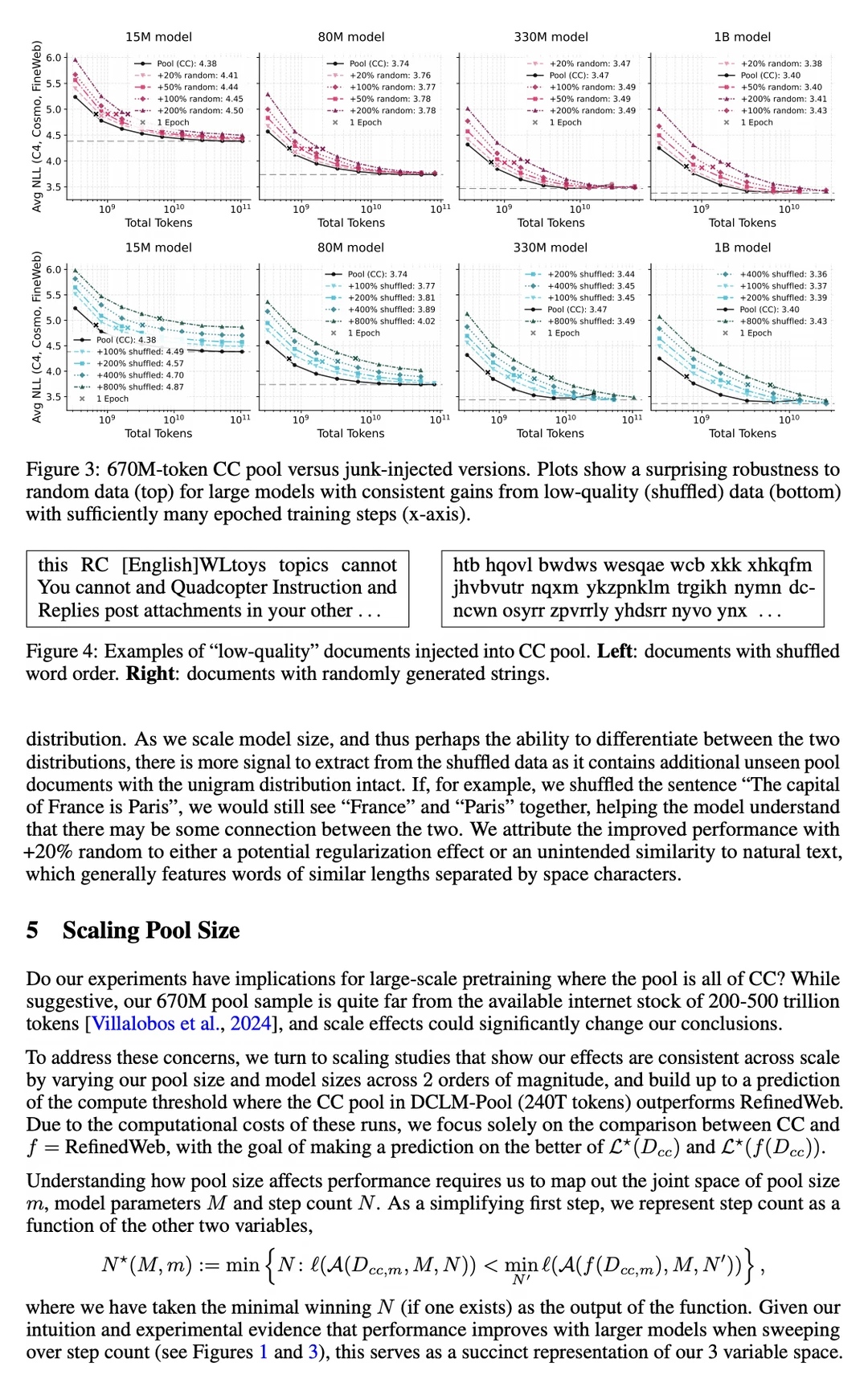
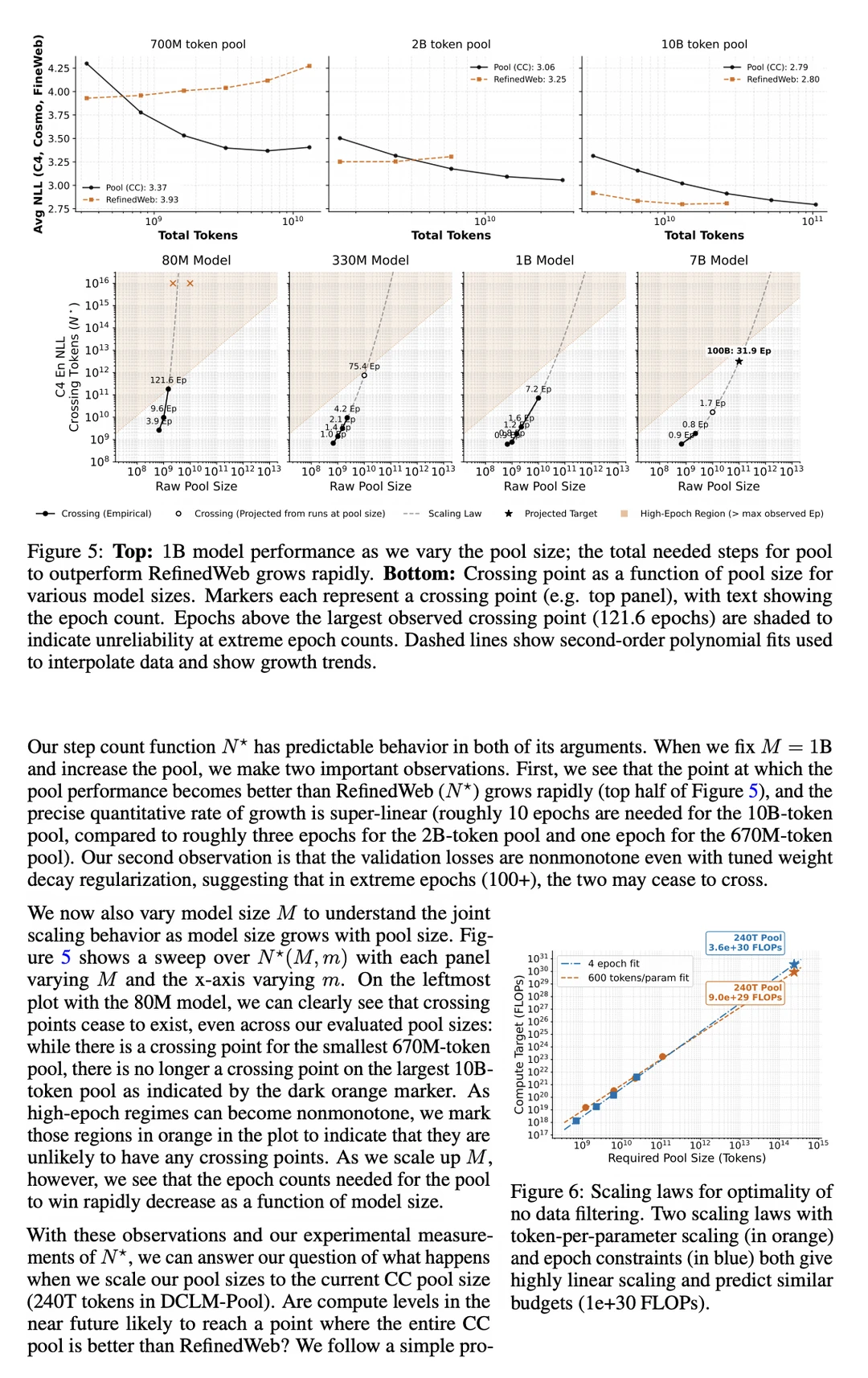
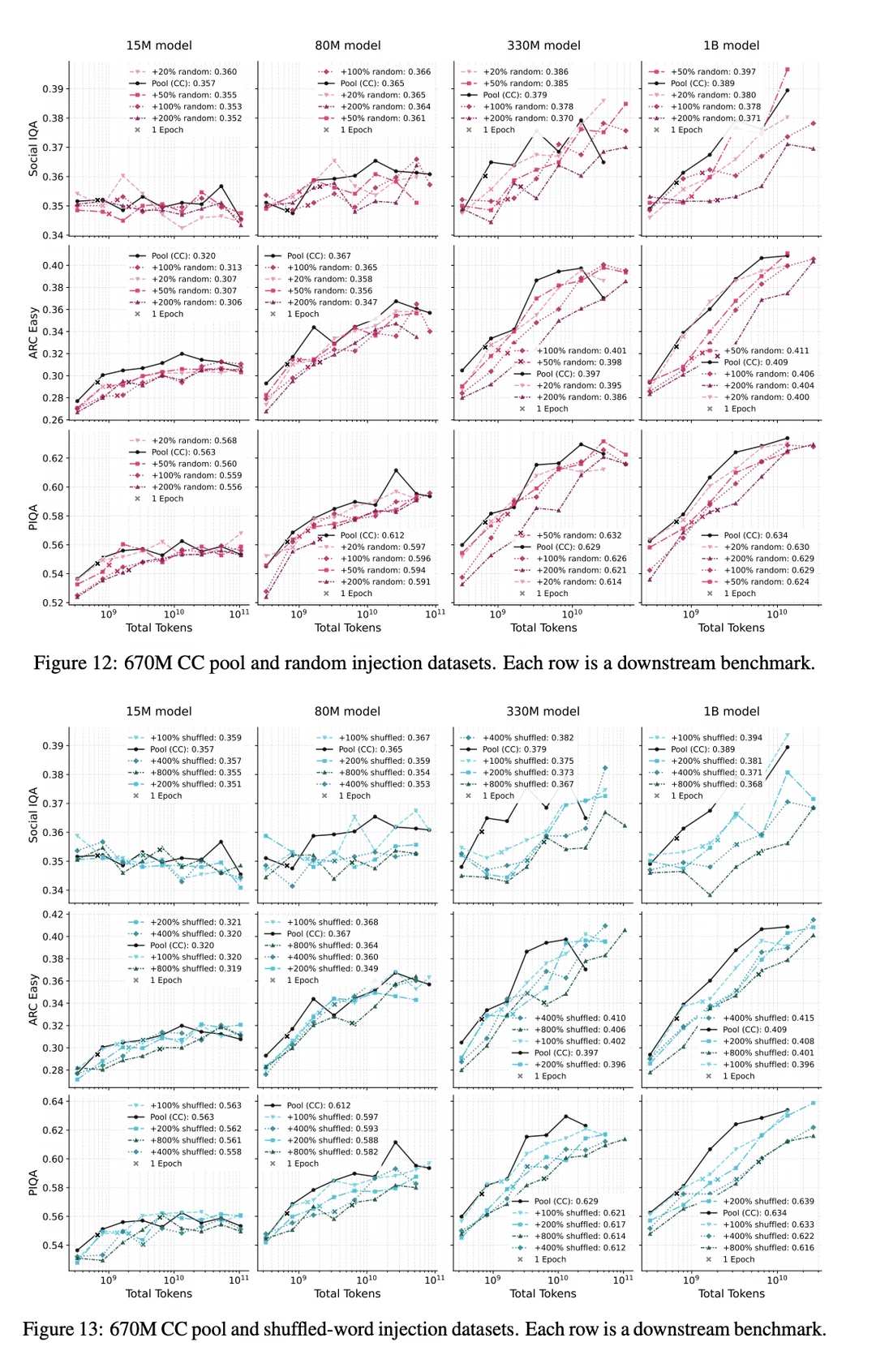
大模型圈一直有个共识:「垃圾进,垃圾出」(Garbage in, Garbage out)。为了洗出高质量的预训练数据,各大团队不惜耗费巨额算力和人力,构建复杂的分类器和规则。
斯坦福团队最新发布了一篇论文《A Bitter Lesson for Data Filtering》,直指在足够大的计算规模下,最好的数据过滤器就是「没有过滤器」。
🔆核心颠覆性发现
1️⃣ 大模型对「垃圾数据」有神级耐受力
实验表明,当模型参数量足够大(>330M)且算力充沛时,直接在未经过滤的互联网原始数据(Raw Data)上训练,最终的 Loss 和表现,反而反超了那些在精细过滤数据上训练的模型!
2️⃣ 「脏数据」里藏着金子
传统过滤器在剔除噪声的同时,把大量有价值的「边际数据」(Marginal Data)也误杀了。这些看起来不够完美的网页,其实包含着丰富的语言多样性和长尾知识。大模型不仅不怕这些噪声,还能把它们转化为泛化能力。
3️⃣ 别怕谣言和错误事实
有人担心不过滤会导致模型学坏?论文分析发现,互联网海量数据中,主流依然是正确事实。大模型强大的统计学习能力,会自动在海量数据中把噪声「平均化」或对冲掉。它自己,就是一个最顶级的隐式过滤器。
这篇论文的名字,显然是在致敬 AI 巨擘 Richard Sutton 那篇著名的《苦涩的教训》(The Bitter Lesson)。
AI 历史无数次证明,人类试图通过手工特征、精细规则、精选数据去「教」AI 走捷径的努力,最终都会在绝对的「算力 + 规模(Scale)」面前溃败。
未来超大规模预训练,可能不再需要复杂的重度数据清洗管道,直接上原始(或极弱过滤)数据池反而是更优解。
「大力不仅能出奇迹,大力还能洗净数据。」你怎么看这次的数据范式颠覆?