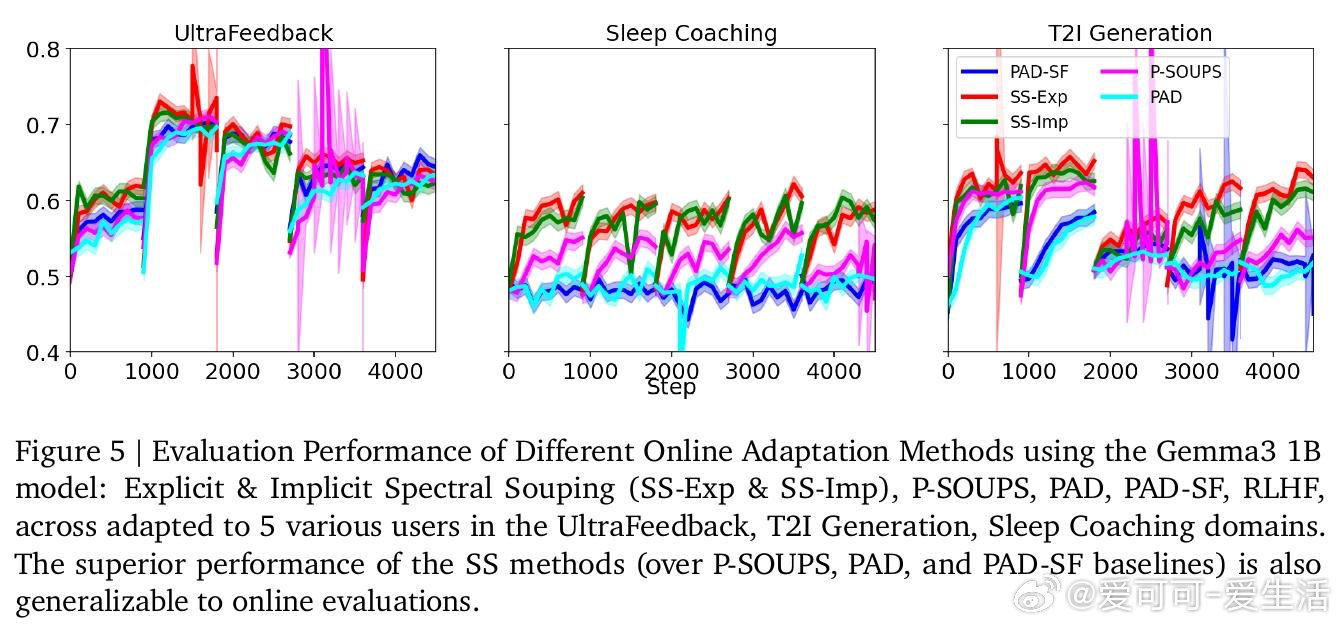
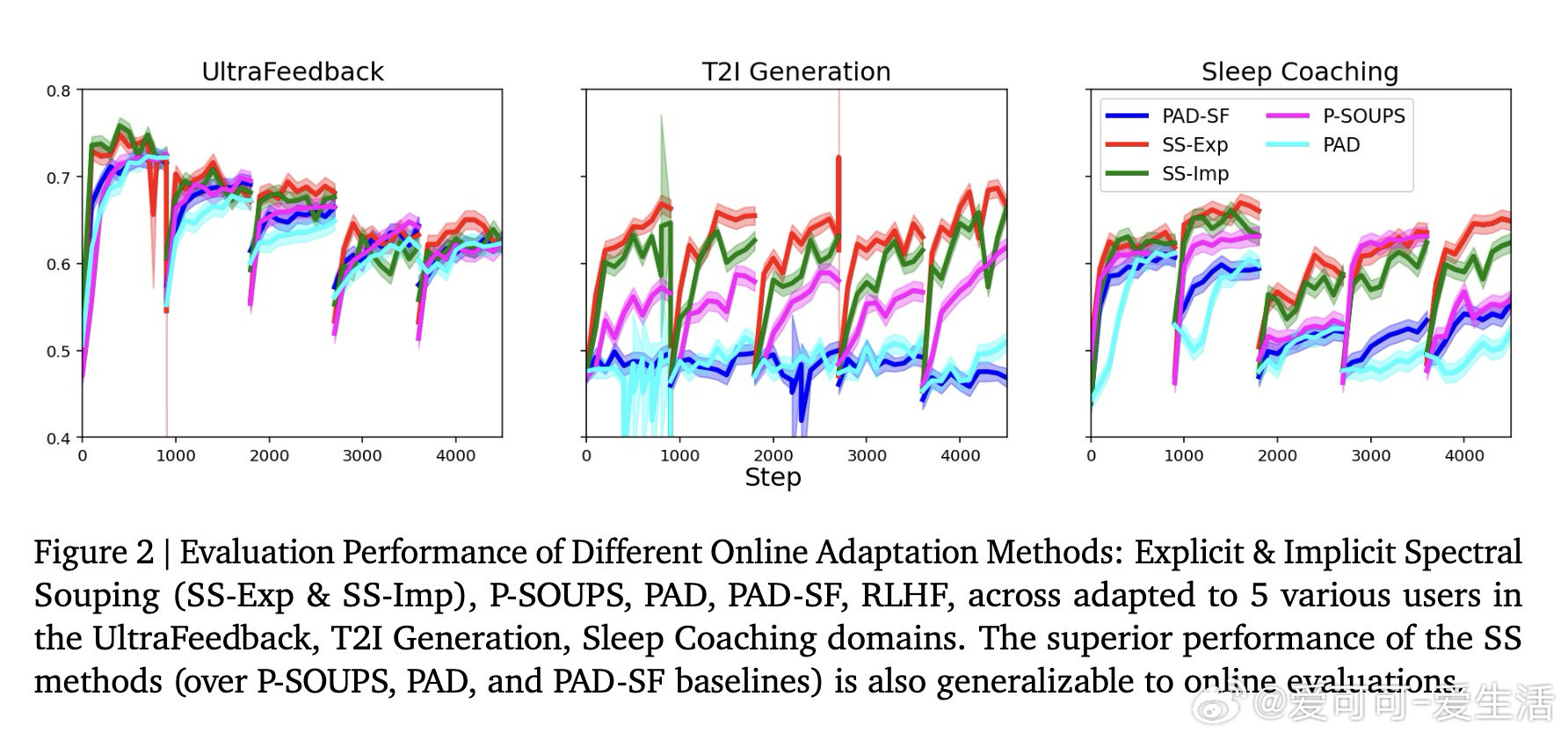
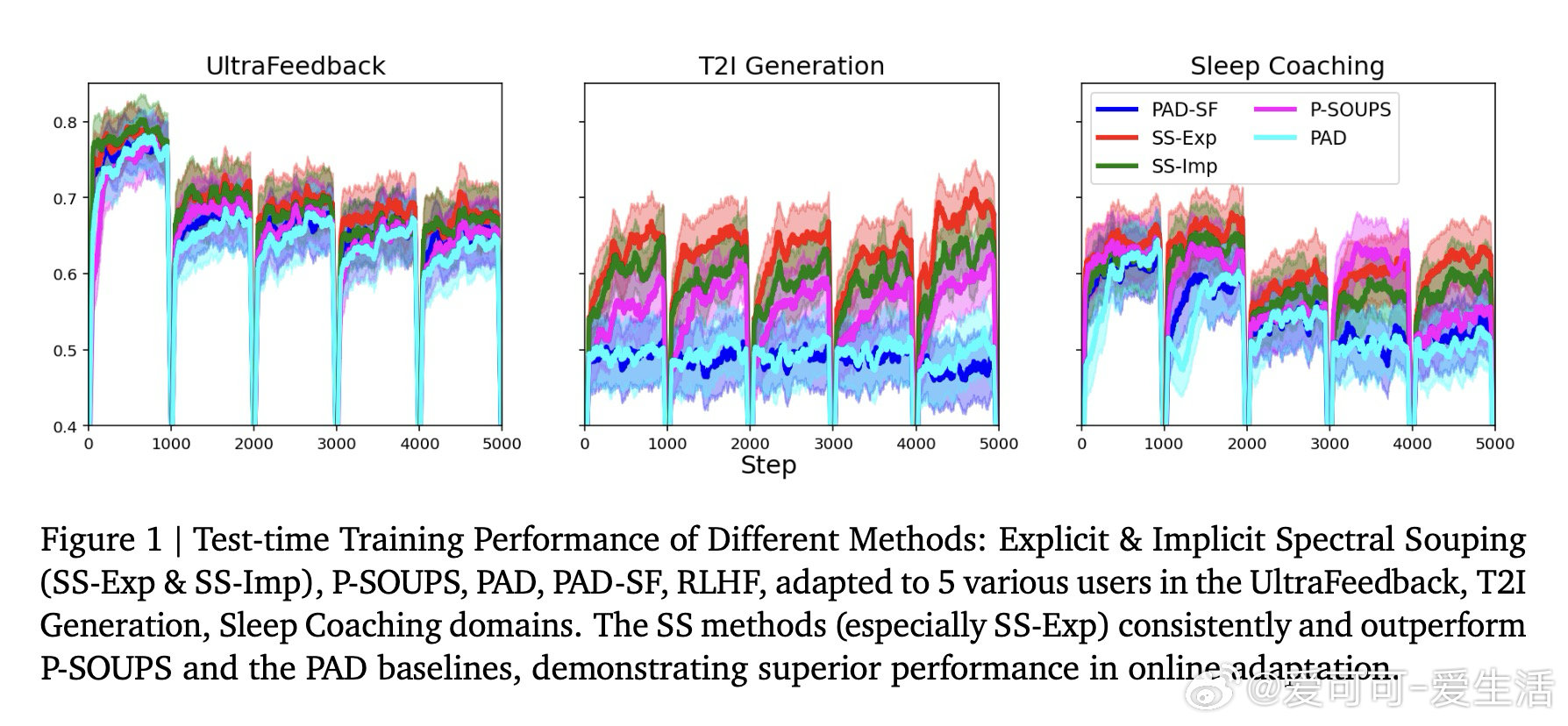
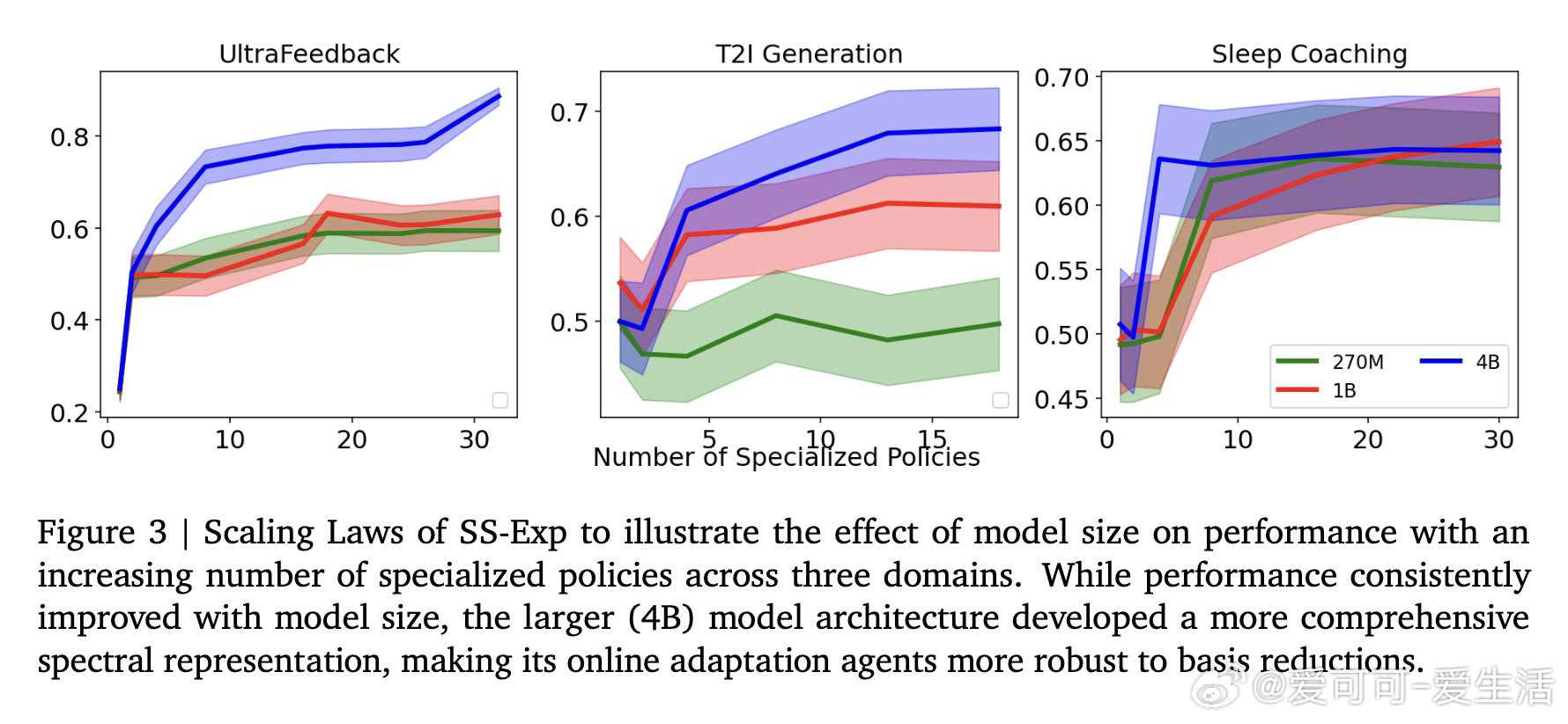
[LG]《Spectral Souping: A Unified Framework for Online Preference Alignment》Y Chow, G Tennenholtz, T Yun, J Harrison… [Google DeepMind & Google Research] (2026)
在个性化LLM对齐领域,在线适配是一个悬而未决的难题。过去的方法受困于为每个用户重新训练,本质原因是多样偏好被压成单一奖励,模型难以低成本切换取向。
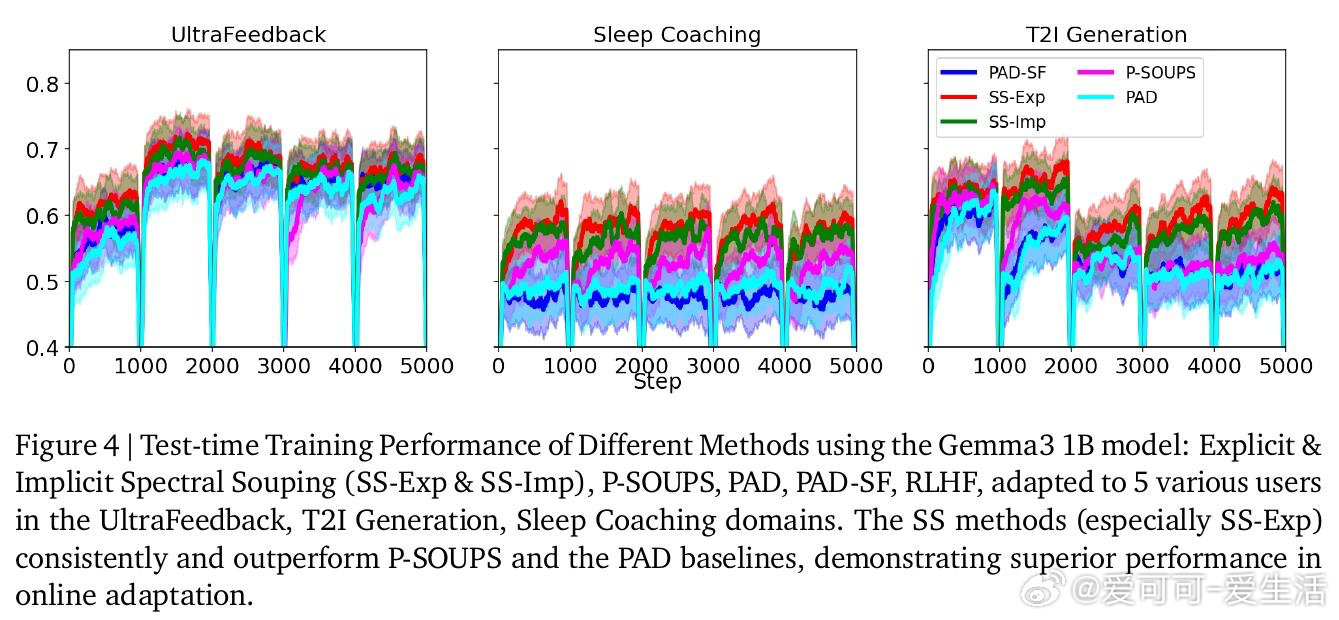
本文的核心洞见是:把个性化策略重新看作少数偏好基策略的谱空间组合。由此,先离线训练专门策略,再在线调整混合权重,就能在推理时“调汤”出贴合用户的模型。
这项工作真正留下的遗产是给模型合并补上可证明的结构。它为后来者打开的新门是低维偏好基上的快速个性化,但尚未跨过的门槛是更紧理论界、自动发现偏好基与跨模态扩展。
arxiv.org/abs/2605.20408 机器学习 人工智能 论文 AI创造营