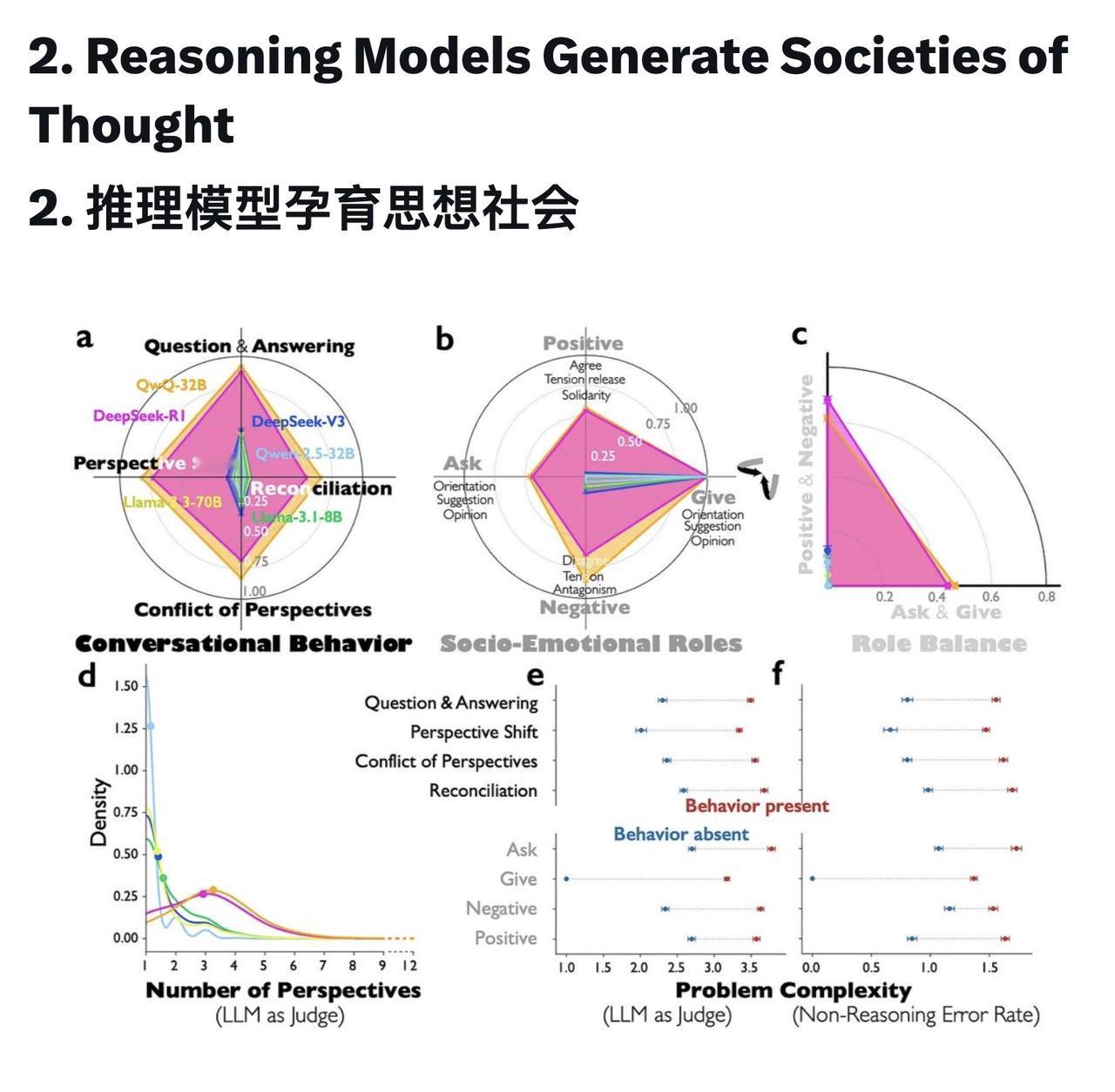
DeepSeek-R1 和 QwQ-32B 这样的模型中增强的推理能力并非仅仅源于扩展的计算,而是源于模拟类似多智能体的交互——一个“思想社会(society of thought)”——从而能够在具有不同个性特征和领域专业知识的内部认知视角之间进行多样化和辩论。 多智能体内部动态: 通过机制可解释性分析,推理模型展现出比指令调整模型更大的视角多样性,在推理过程中激活了异质个性和专业知识相关特征之间更广泛的冲突。 对话行为提升准确性: 多主体结构体现在问答、视角转换和冲突观点的调和等方面。这些构成对话特征的社会情感角色解释了推理任务中准确性的优势。 从准确性奖励中涌现: 受控强化学习实验表明,当仅因推理准确性而获得奖励时,基础模型自然会增加对话行为,这表明这种结构是从优化压力中自然产生的。 通过脚手架(scaffolding)加速改进: 利用对话式脚手架对模型进行微调,可以加速推理能力的提升,为增强推理能力提供了一条切实可行的途径。 与集体智慧平行: 研究结果表明,推理模型建立了一种与人类集体智慧类似的计算方法,其中多样性在系统地构建时能够实现更卓越的问题解决能力,为智能体组织开辟了新的机遇。