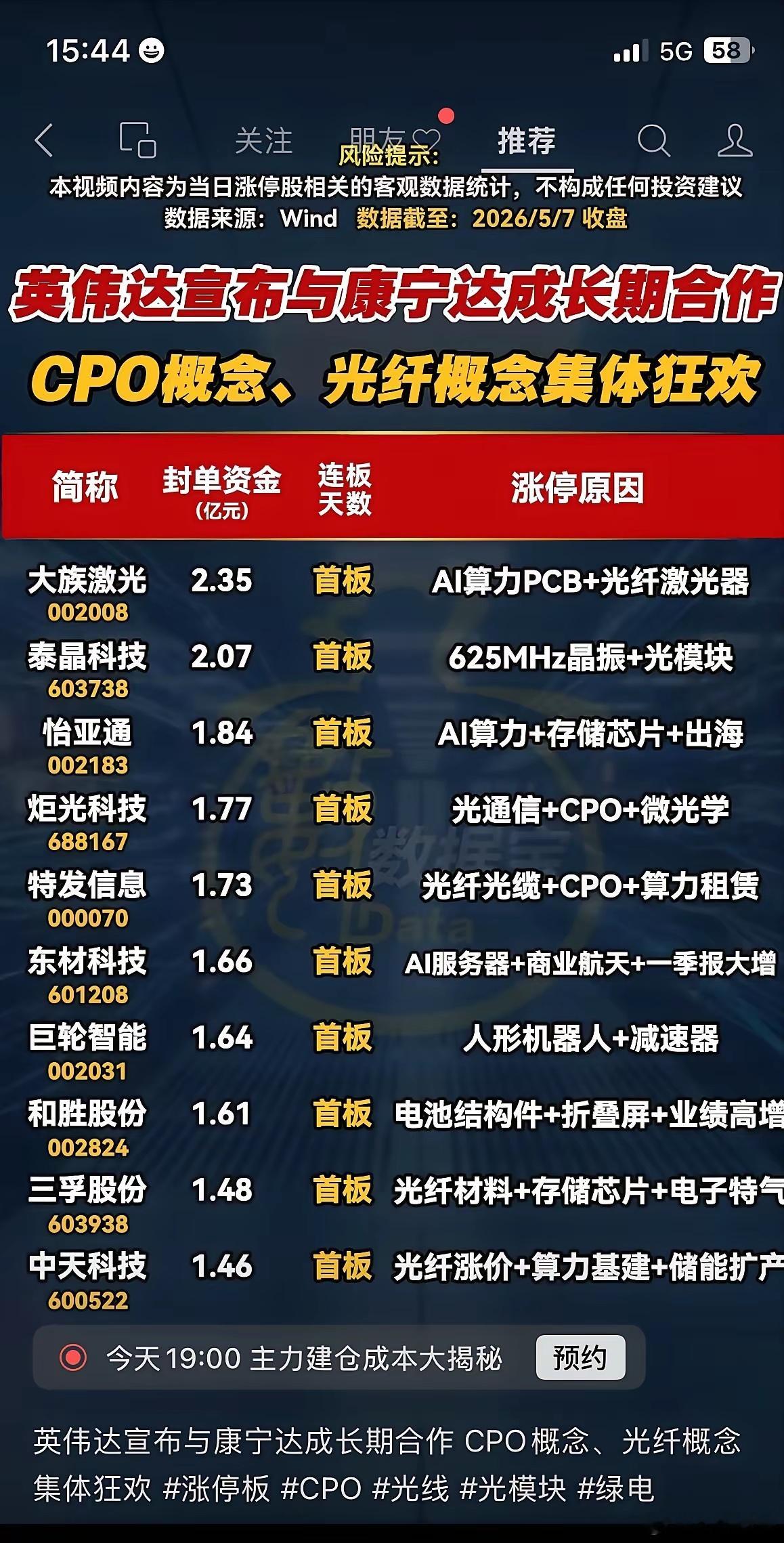
美国的外交电报突然发往全球。白纸黑字只有一句话:警告所有国家,离那个叫DeepSeek的中国模型远点。就在这份警告信满世界飞的时候,杭州的办公大楼里,DeepSeek的团队甚至连发布会都没开。他们只是在官网上默默更新了一份技术报告,V4预览版直接上线。 很少有人知道,DeepSeek的起点在2023年7月17日。 杭州深度求索人工智能基础技术研究有限公司这天正式成立,由幻方量化孵化,创始人梁文锋是浙江大学毕业,初期资金全靠幻方量化支持,目标就是做能抗衡海外顶尖AI的国产大模型。 成立初期团队没做任何宣传,闷头扑在算法和算力调优上。 2023年11月2日,他们先推出DeepSeek Coder,主打低成本代码生成,在开发者小圈子里攒下口碑;29日,初代通用大模型DeepSeek-LLM发布,用混合专家架构走低成本路线。 那时候海外AI被OpenAI和Google垄断,行业普遍觉得没有顶级芯片和巨额融资,做不出第一梯队模型,梁文锋没辩解,只是带着团队继续深耕。 2024年12月26日,DeepSeek-V3毫无预兆上线并开源,参数6710亿、激活370亿,在14.8万亿词元上预训练,训练成本仅557.6万美元,不到OpenAI同类模型零头,多项评测追平GPT-4o。 国外开发者疯狂下载,网站一度宕机,美国科技界的危机感开始浮现。 2026年4月24日,也就是美国电报曝光当天,DeepSeek-V4预览版上线开源,分V4-Pro(1.6万亿总参数)和V4-Flash(284B总参数),都支持百万级上下文。 更关键的是,V4完成全栈国产化适配,迁移到华为昇腾CANN框架,针对昇腾950PR芯片优化,不用英伟达高端芯片也能跑通顶级模型,直接戳中美国芯片管制的要害。 英伟达CEO黄仁勋4月底公开表示,DeepSeek在华为平台首发,会对美国AI产业造成灾难性冲击。 4月26日,DeepSeek宣布API价格下调90%,V4-Flash输入缓存低至0.02元/百万Token,比OpenAI便宜97%,全球开发者大量接入,美国的担忧彻底加剧,电报不过是无力的应对。 2026年5月6日,外媒曝出DeepSeek首轮融资谈判,估值最高近500亿美元,这背后是一个月的股权调整。 4月22日首次爆料时,估值仅200亿美元,腾讯、阿里洽谈入股;27日,公司注册资本从1000万增至1500万,梁文锋直接 持股升至34%,合计控制84.29%股权,保住技术控制权。 5月6日,国家大基金三期确认领投,投后估值约450亿美元,这是国家大基金首次投资大模型公司,把顶尖AI模型列为战略资产。 本轮募资超500亿元,梁文锋个人出资200亿元,腾讯出资60亿元获2%股权,资金全部用于扩充昇腾算力、扩招研发和搭建开源生态。 美国国家标准与技术研究院5月1日评测显示,DeepSeek-V4 Pro仍落后最前沿模型数月,这也说明它不是神话,而是在竞争中稳步前行。 《荀子》里有句话,不诱于誉,不恐于诽。这句话恰如其分,DeepSeek面对吹捧和打压,始终低调专注技术。