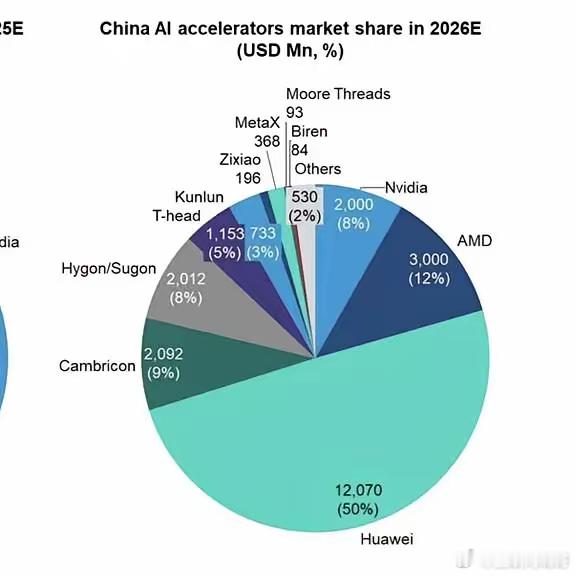
还记得前两年搞人工智能的公司最怕什么吗?不是招不到人,也不是写不出代码,而是买不到显卡。 那时候大家见面第一句话就是:“你有卡吗?” 手里要是没几张英伟达的高端货,都不好意思说自己是做大模型的。 那种焦虑是真真切切的,因为美国人把高端芯片一卡,咱们这边连试验的资格都快没了。 但就在2026年4月24日,DeepSeek这家公司扔出了一个重磅消息,发布了他们的V4模型。 这一下子,整个圈子都安静了,随后就是沸腾。 为什么?因为这不仅仅是一个软件升级,而是一次彻底的“换芯”。 咱们先来看看这个DeepSeek V4到底有多厉害。 以前大家总觉得,中国的模型跟美国比总是慢半拍,得追着人家跑。但这次V4交出的成绩单,让很多人闭上了嘴。 它分了两个版本,一个叫V4-Pro,一个叫V4-Flash。 别看名字花哨,实力那是杠杠的。 在权威的Artificial Analysis评测里,那个Pro版已经能和谷歌的Gemini 2.5 Pro、Anthropic的Claude 4.5 Sonnet这些世界顶级的闭源模型掰手腕了。 特别是在写代码和解决复杂数学题这块,V4-Pro的表现甚至超过了所有公开的开源模型。 有个搞开发的朋友跟我说,他们现在公司内部写代码,已经开始用V4来代替以前的国外工具了,效率高不说,关键是好用。 但这还不是最让人震惊的。最绝的是它的价格。 以前用国外的模型,那叫一个烧钱,动不动就是几十美元、几百美元地往里砸。 现在DeepSeek V4把价格直接打到了“白菜价”。V4-Flash版本的输入价格,低到每百万个词才几分钱。 就算是最强的Pro版,打完折之后的输出价格也比国外便宜了百分之九十七以上。 这就好比同样是一顿饭,以前去高档西餐厅吃一顿得花一个月工资,现在去实惠的馆子,一顿早饭钱就能吃饱吃好。 这种降价不是赔本赚吆喝,而是通过技术手段,把算力的消耗硬生生降了下来。 据说他们在算法上做了大优化,同样的任务,消耗的电力和计算资源只有以前的一小部分。 那么,支撑起这么强性能和这么低价格的背后,到底用了谁的芯片? 这就是这次发布最劲爆的地方——华为昇腾。 以前咱们总觉得,国产芯片只能干点边缘活,真要训练这种万亿参数的大模型,还得靠英伟达。 但DeepSeek V4这次彻底打破了这个迷信。 它不是那种先把模型在英伟达芯片上跑通了,再勉强搬到国产芯片上试试看的“凑合”方案。 相反,DeepSeek从一开始写代码、搭架构的时候,就和华为昇腾的工程师们坐在一起,针对昇腾950芯片的特性专门做了优化。 这叫“原生适配”,也就是根子上就是一起长的。 华为昇腾950这颗芯片,这次是真的扬眉吐气了。 单卡算力比英伟达专门卖给中国的特供版H20强了近三倍。 在DeepSeek V4的测试里,用昇腾芯片跑起来的速度飞快,推理时延低到让人惊讶。 这就意味着,以后国内的互联网大厂们不用再去求着英伟达供货了,也不用担心哪天又被断供。 华为现在的订单接到手软,字节、腾讯、阿里都在排队加单。 这就是实实在在的生产力,也是咱们科技行业的底气。 回想一下,美国搞芯片封锁,本来是想把中国AI的发展摁住,让我们永远跟在他们屁股后面吃灰。结果没想到,压力越大,反弹越强。 DeepSeek这种“算法瘦身”加上华为“国产算力”的组合拳,硬生生走出了一条新路。 这条路不用堆砌成千上万张昂贵的显卡,而是靠聪明的算法和高效的国产硬件配合,照样能做出世界顶级的产品。 这对咱们普通人意味着什么呢? 意味着以后我们用到的各种AI服务会更便宜、更普及。 以前只有大公司才用得起的高级功能,现在小团队甚至个人开发者都能玩得转了。 这就是技术平权。当成本不再是门槛,创新就会像野草一样疯长。 现在回过头看,那些曾经的“缺芯”焦虑,反倒成了催命符,逼着国内的产业链上下游拧成了一股绳。 DeepSeek证明了算法可以弥补硬件的某些不足,华为证明了国产芯片完全能挑大梁。 这种“模型+算力”的全栈国产化闭环一旦形成,威力是巨大的。 以前我们总盯着那几个月的性能差距看,觉得差一点就低人一等。 但现在看来,谁能把成本降下来,谁能把效率提上去,谁能用自主可控的技术服务更多人,谁才是最后的赢家。 DeepSeek V4和华为昇腾的配合,就像是给中国AI装上了一台强劲的“中国心”。 未来的全球AI牌桌上,咱们终于可以挺直腰杆,用自己的筹码,制定自己的规则了。 看着这一幕,不禁让人感慨,当年的卡脖子之痛,终究是化作了今天突围的动力。 这条路走通了,后面的路就好走了。 各位不妨想想,当AI技术变得像水电一样便宜又普及时,你所在的行业会发生什么样翻天覆地的变化? 信息来源:DeepSeek 官方,中国经营报