全模态建模并不遵循均匀的Scaling Law,以后不能一股脑堆料训练了?
以前我们聊大模型增长,默认就是 “均匀堆料”,参数、数据、算力一股脑往上堆,能力就跟着线性涨,这是最初大家摸透的增长规则。
但现在行业突然发现,之前的逻辑全不对了。
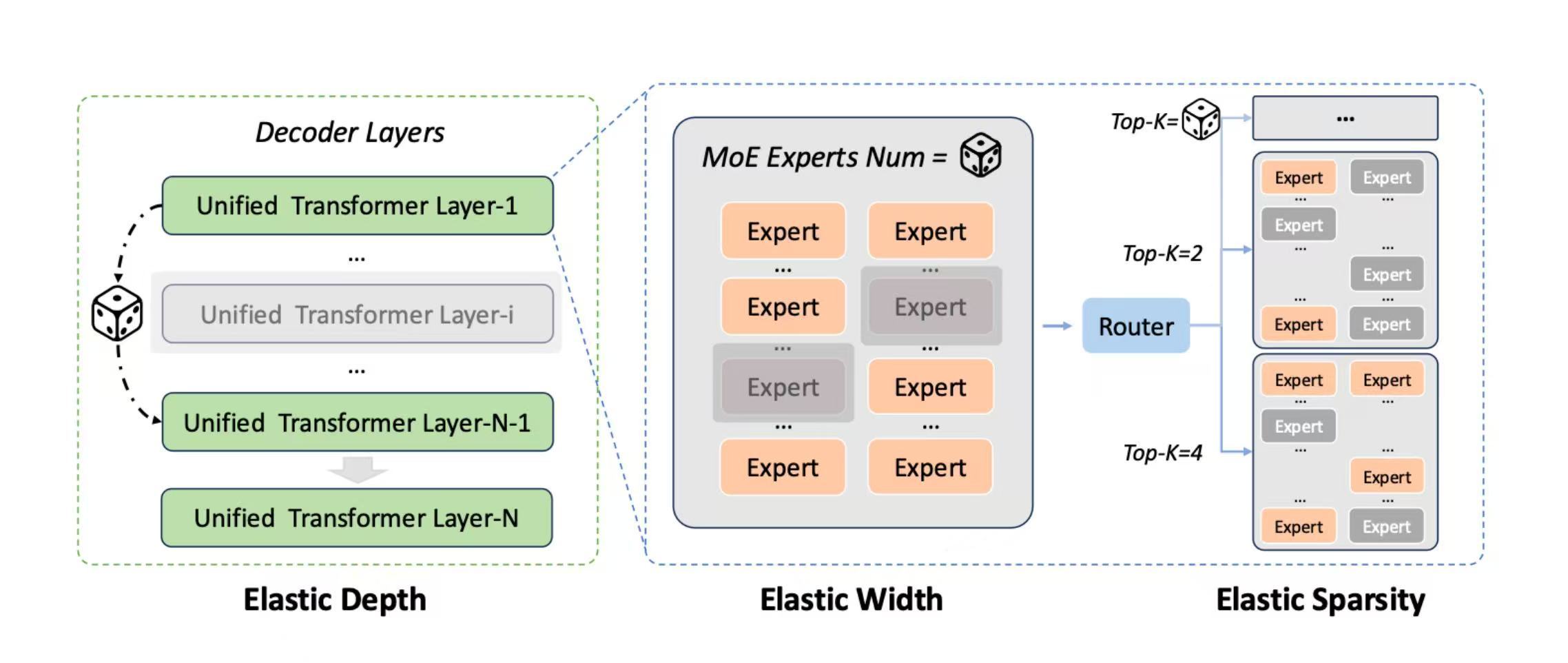
全模态的Scaling根本不是均匀的,不同模态要的资源完全不一样,语言模态对参数容量的敏感度更高,视觉模态对训练计算量的需求更大,模型根本不会平均分配算力和参数,而是动态向高需求模态倾斜。
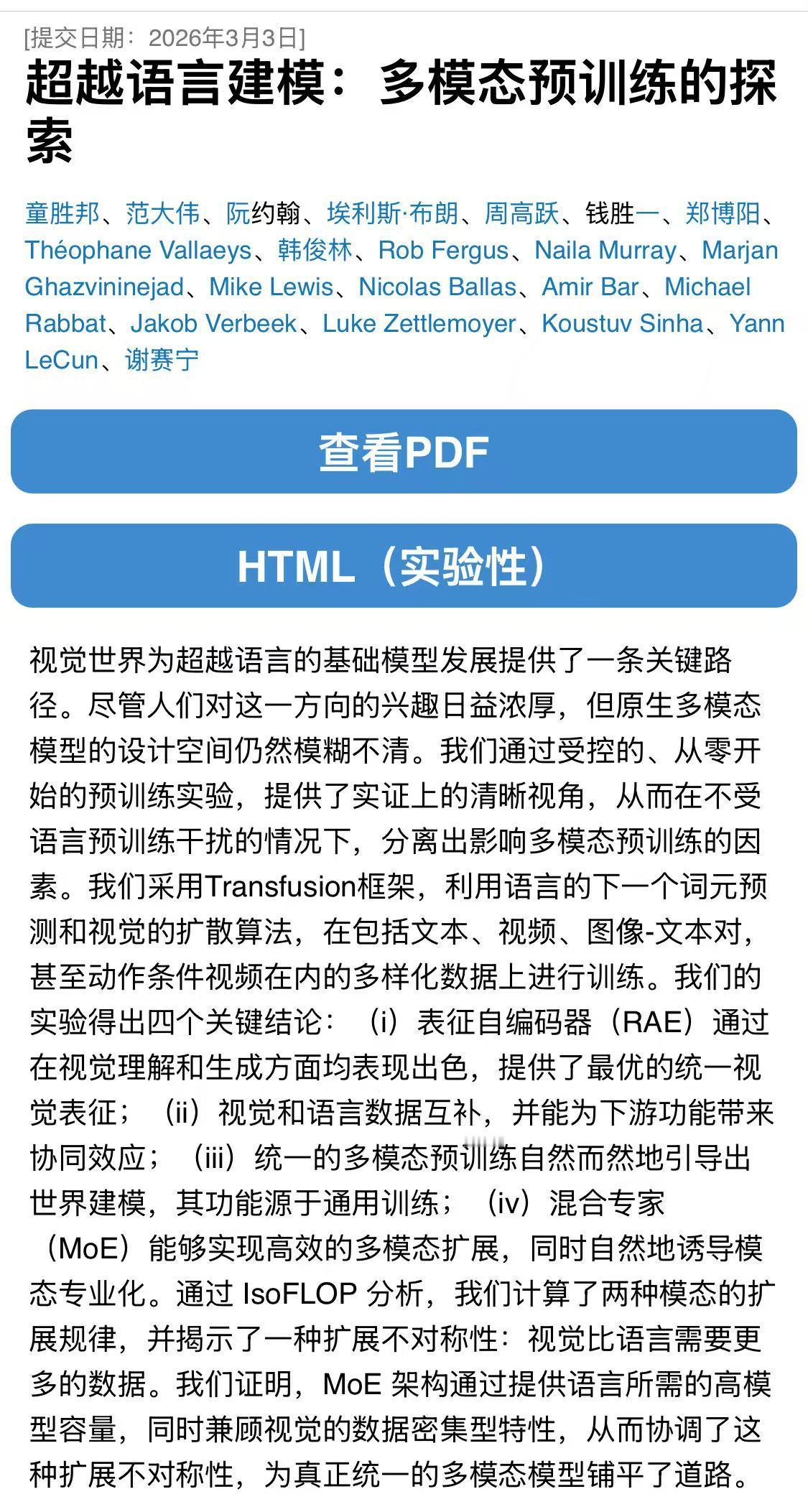
杨⽴昆和谢赛宁在最新发表的论⽂中,就引⽤了某国产模型的技术报告,指出尽管使⽤了旨在⿎励均匀利⽤的辅助负载均衡损失,但统⼀多模态预训练分配给⽂本的专家数量仍显著多于视觉专家。
该发现和某大模型技术报告中的发现⼀致,就是语⾔是“参数需求型”的,⽽视觉是“数据需求型”的,所以模型会通过MoE⾃然地为语⾔分配更多专⽤容量。
这些最新研究都在表明,模型其实是“偏⼼”的。Scaling Law并不会把语⾔和视觉能⼒⼀起做强。所以,模型不再被假定为在不同模态上均匀扩展,⽽是需要根据模态进⾏差异化配置与优化。
这么看,原⽣多模态模型设计的基本认知被颠覆了。这是否意味着,下一代大模型的竞争,可能就不是比谁堆的参数多了,而是转向精细化的非均匀增长?