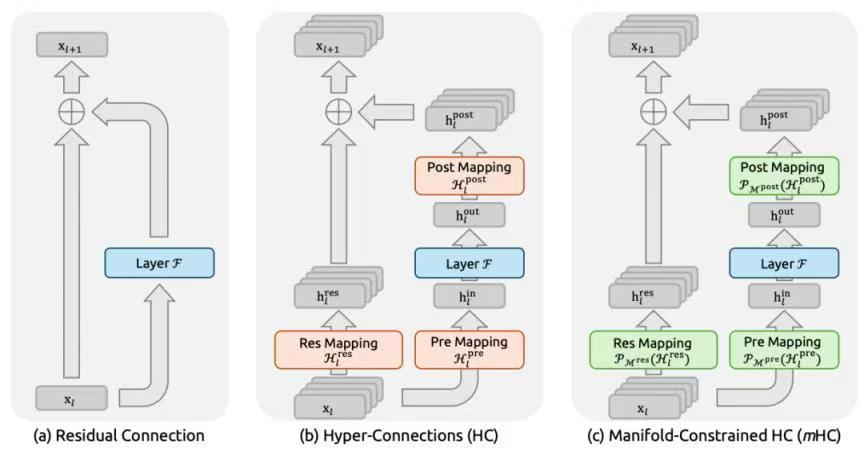
1月1日,当全球还沉浸在新年的假期氛围中,国内顶尖大模型团队DeepSeek悄然投下了一枚“深水炸弹”。一篇关于全新架构mHC(Manifold Constrained Hyper-connectivity,流形约束超连接)的论文正式发布。这一技术名词对于普通大众或许晦涩,但在AI科研圈,它意味着大模型训练中最棘手的“稳定性”难题,可能迎来了一种极具性价比的全新解法。这不仅是技术层面的迭代,更是在全球算力博弈背景下,对现有计算效率的一次极限挑战。 长期以来,深度学习领域存在一个著名的“取舍”难题:超连接架构虽然能让模型在推理和任务处理上获得显著的性能提升,但在大规模训练过程中却极不稳定。这就好比给赛车安装了涡轮增压,速度虽然快了,但引擎过热、随时报废的风险也成倍增加。DeepSeek的这篇论文,恰恰提出了在“mHC”架构下,既能保持超连接带来的性能红利,又能通过流形约束机制将训练过程牢牢锁定的技术路径。 对于一直关注这一领域的观察者来说,DeepSeek这个名字早已不陌生。杭州深度求索人工智能基础技术研究有限公司,这家公司近年来在开源模型界的表现可谓势如破竹。根据百度百科资料显示,其推出的AI助手于2025年1月15日正式上线,距离这篇mHC论文的发布仅过去不到半个月。这种从理论突破到产品落地的“中国速度”,正在重塑行业格局。 值得注意的是,DeepSeek的产品实力并非空中楼阁。数据分析平台QuestMobile在2025年2月21日公布的一组数据极具说服力:从上线至2月9日,DeepSeek App的累计下载量已突破1.1亿次,周活跃用户规模最高峰更是接近9700万。特别是1月20日至1月26日这一周,用户增长曲线呈现出惊人的陡峭度。这庞大的用户基数,实际上成为了验证其技术架构最真实的“试验田”。mHC架构如果真能如论文所言,解决大规模模型训练的不稳定性,那么未来在处理像DeepSeek这样亿级用户并发、复杂多模态请求时,其优势将转化为实实在在的成本优势和响应速度。 在这一系列技术光环和亮眼数据背后,DeepSeek的创始人梁文锋却显得异常神秘。在网络热议的评论区,这种“技术极客”与“幕后隐士”的反差感成为了焦点。来自宁夏的网友“静致明”感慨,梁文锋及其团队的默默奉献是我国科技大爆发的缩影;而青海的网友“初衷之语7a”则指出,梁文锋从不公开露面,网络上仅有一张他上台发言的照片。这种低调行事、高调做事的风格,恰恰符合当下硬科技领域“板凳甘坐十年冷”的务实精神。 技术的演进从来不是孤立的。浙江网友“星子13”在评论区的见解颇具深度,他提到了“认知编译统一语法”、“价值对齐”、“认知免疫”以及“递归涌现”等概念。这些看似深奥的词汇,实际上指出了大模型发展的下一阶段——不仅仅是算力的堆叠,更是对底层逻辑和认知理解的深度重构。DeepSeek此次提出的mHC架构,某种程度上正是在为解决这些深层问题打地基。只有底座足够稳固、训练足够收敛,上层建筑的价值对齐和认知免疫才有可能实现。 把目光拉回到国际视角,当前全球AI竞争已进入白热化阶段。传统的Transformer架构在参数规模不断膨胀的今天,正面临着算力墙和能耗墙的双重挤压。如何在有限的硬件资源下训练出更强、更稳的模型,是所有科技巨头都在攻克的堡垒。DeepSeek在1月1日发布的这项研究,无疑提供了一个区别于单纯 scaling law(缩放定律)的新思路。它试图通过数学上的流形约束,来几何级地提升计算效率,这不仅是工程学的胜利,更体现了算法设计的智慧。 从1月1日的论文发布,到1月15日的产品上线,再到2月21日QuestMobile近亿级的用户数据验证,这一连串精确的时间节点串联起了DeepSeek的成长轨迹。mHC架构的出现,或许标志着国内大模型研究已经走过了单纯模仿的阶段,开始进入对底层架构进行自主创新和优化的深水区。 对于开发者和行业从业者而言,DeepSeek的开源精神意味着这些最新的理论成果将有机会被迅速复现和应用。如果mHC架构能够被广泛验证,那么未来中小企业训练高性能大模型的门槛将被大幅降低,整个行业的生态将因此变得更加繁荣。 在这个信息爆炸的时代,我们见证了太多昙花一现的概念,但DeepSeek用扎实的代码和论文,以及在自然语言处理、机器学习、跨模态学习等八大领域的出色表现,证明了技术落地的可行性。1月1日这篇论文的发布,或许在未来的AI发展史上,会被标记为一个关键的转折点——它让我们看到,在通往通用人工智能(AGI)的道路上,除了堆叠显卡,还可以用更聪明的数学方法,走出一条更稳、更远的路。科技爆发并非偶然,它正是由无数个像梁文锋团队这样,在键盘前默默攻克一个个“流形约束”难题的瞬间所累积而成的。 以上内容仅供参考和借鉴