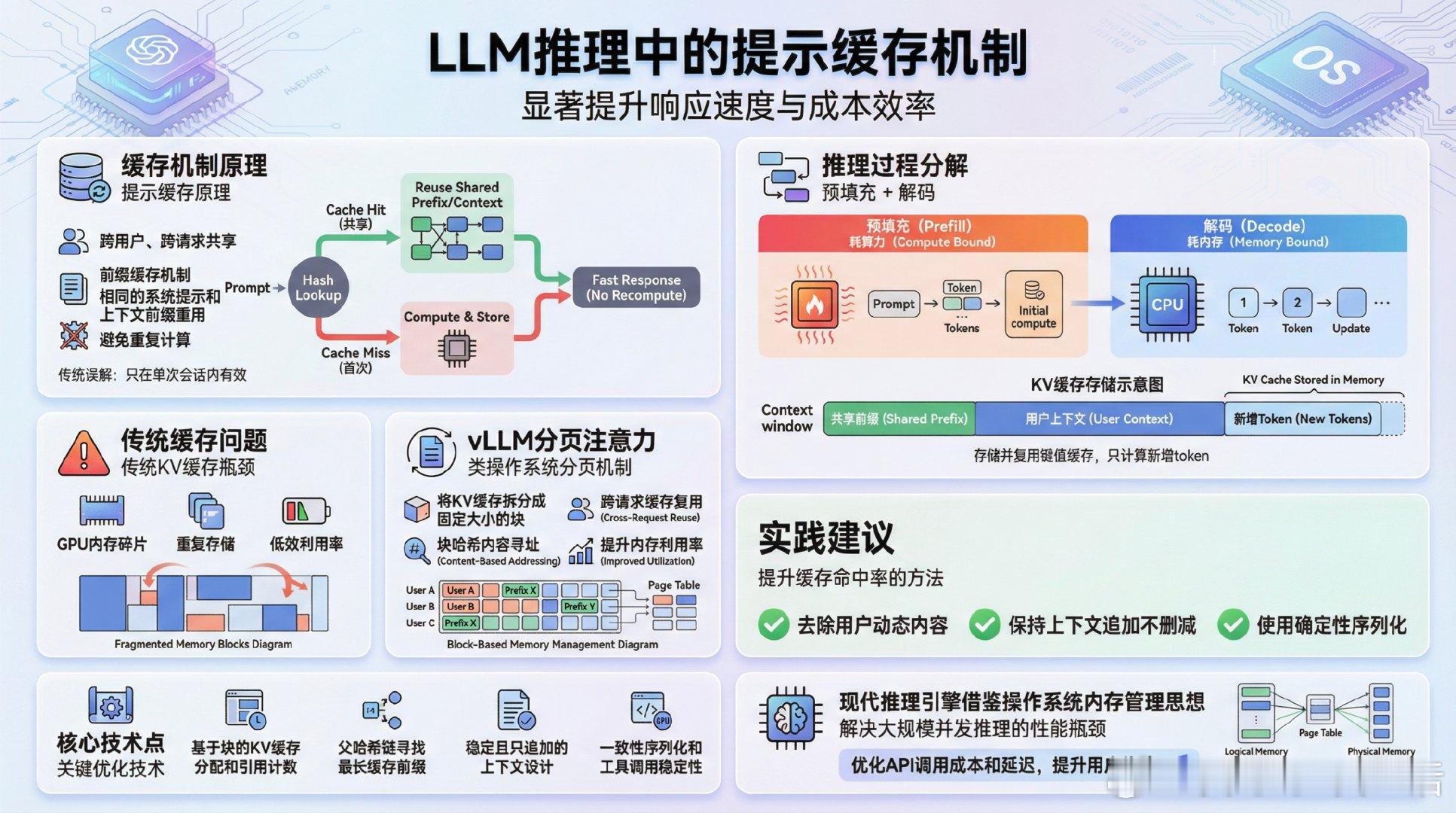
《How prompt caching works - Paged Attention and Automatic Prefix Caching plus practical tips》作者分享了关于大语言模型(LLM)推理中“提示缓存”(prompt caching)的深入解析,结合自己在工作中的实践经验,揭示了缓存如何显著提升响应速度与成本效率。起初,他误以为缓存只在单次会话内有效,后来发现,提示缓存实际上是跨用户、跨请求共享的,关键在于“前缀缓存”——相同的系统提示和上下文前缀能被不同请求重用,避免重复计算。推理过程分为“预填充(prefill)”和“解码(decode)”两步。预填充耗算力,解码耗内存。通过存储和复用键值(KV)缓存,模型解码时只需计算新增token,大幅减少计算量。传统KV缓存面临GPU内存碎片和重复存储的问题。vLLM引入了类操作系统分页的“分页注意力(paged attention)”,将KV缓存拆分成固定大小的块(block),通过块哈希实现内容寻址和共享,支持跨请求缓存复用,极大提升内存利用率和服务并发能力。关键技术点包括:- 基于块的KV缓存分配和引用计数,支持多请求共享同一缓存块- 父哈希链保证因果关系,确保前缀完全一致才能缓存命中- 调度器寻找最长缓存前缀,跳过已缓存块的预填充计算- 稳定且只追加的上下文设计,提升缓存命中率- 一致性序列化和工具调用定义的稳定性,避免缓存失效作者还总结了实际提升缓存命中率的建议,如去除用户动态内容、保持上下文追加不删减、使用确定性序列化等。这篇文章不仅讲清了提示缓存的原理,更深入剖析了现代推理引擎如何借鉴操作系统内存管理思想,解决大规模并发推理中的性能瓶颈。理解这些机制,有助于开发者优化API调用成本和延迟,提升用户体验。原文:sankalp.bearblog.dev/how-prompt-caching-works/