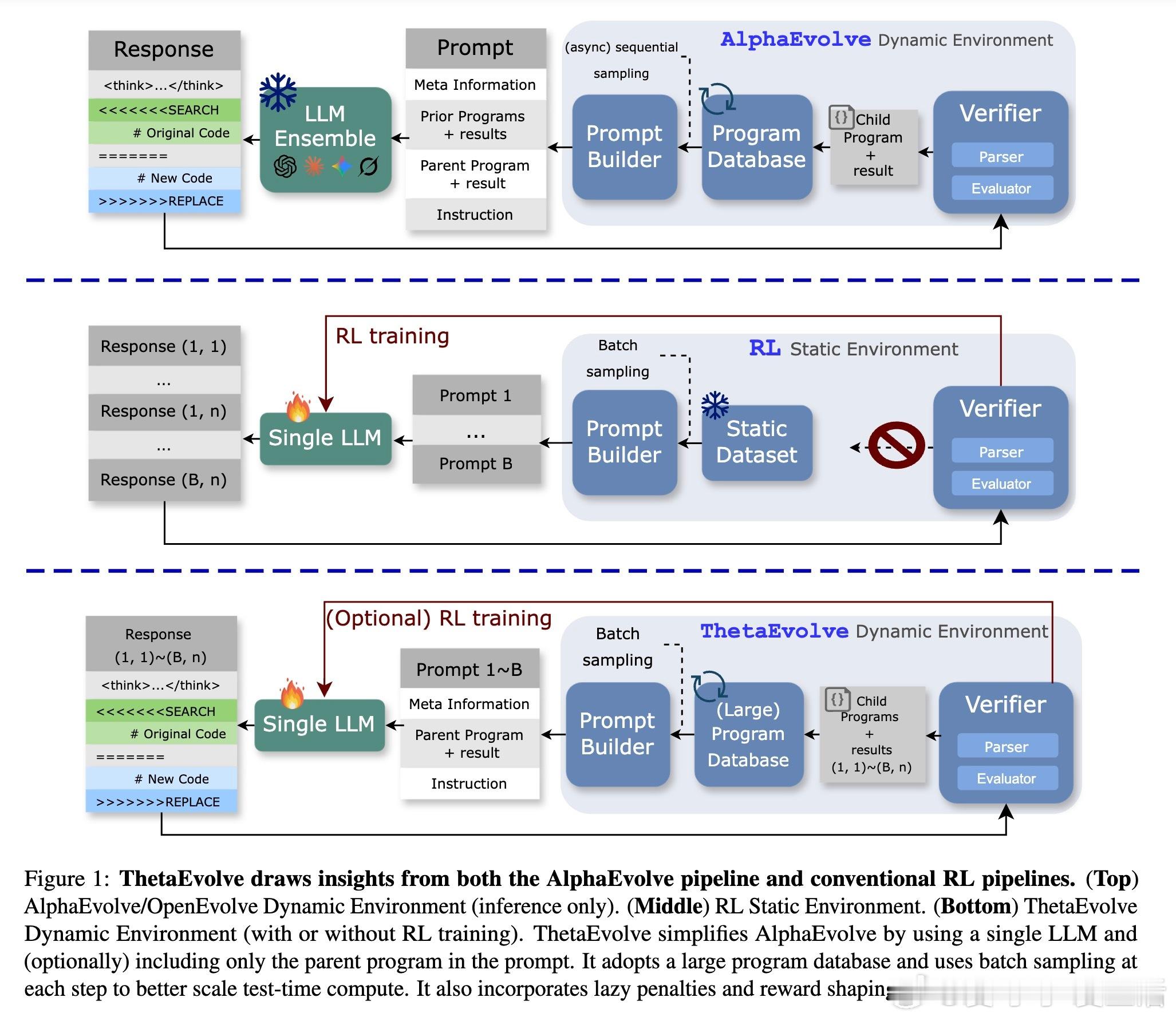
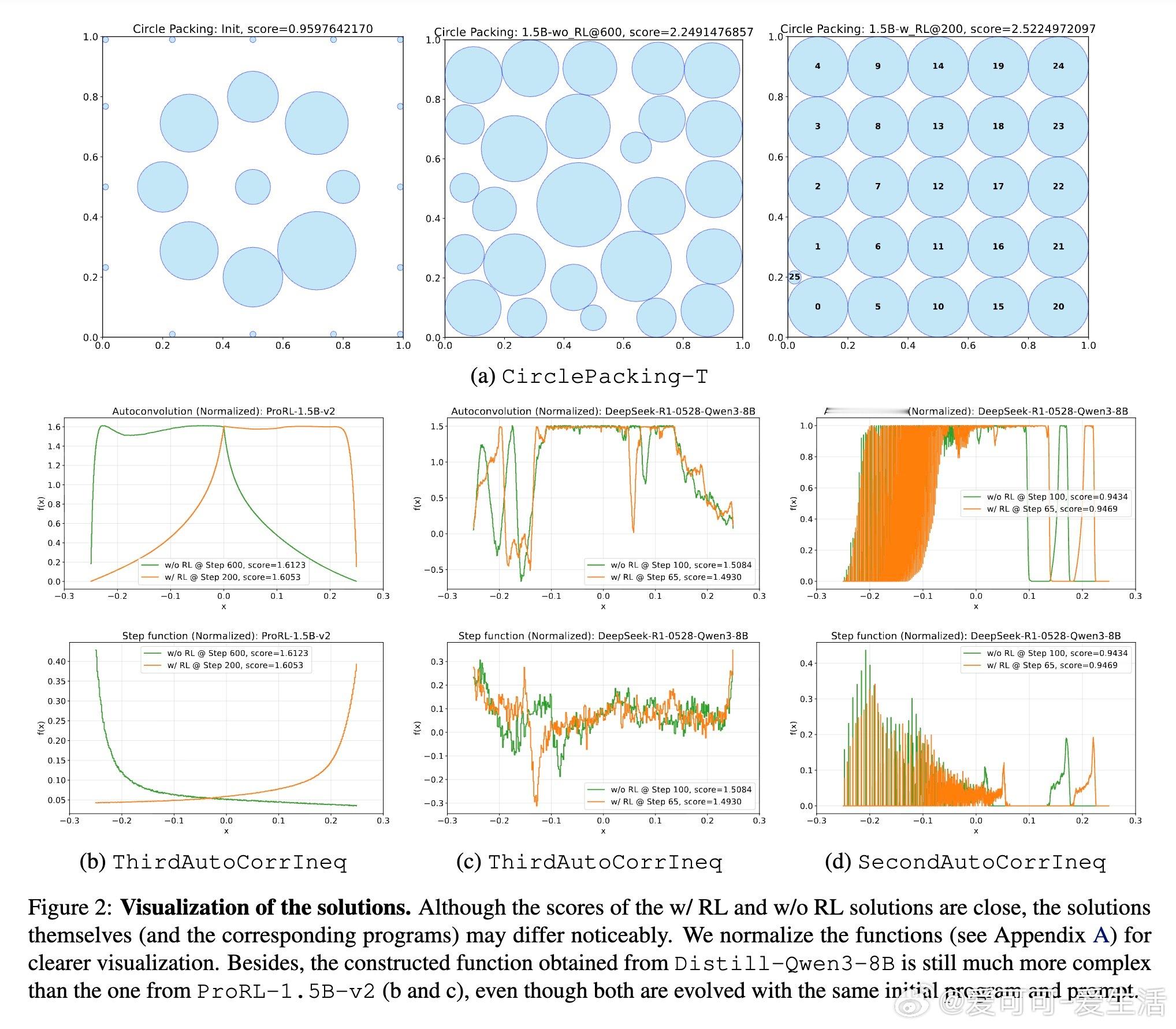
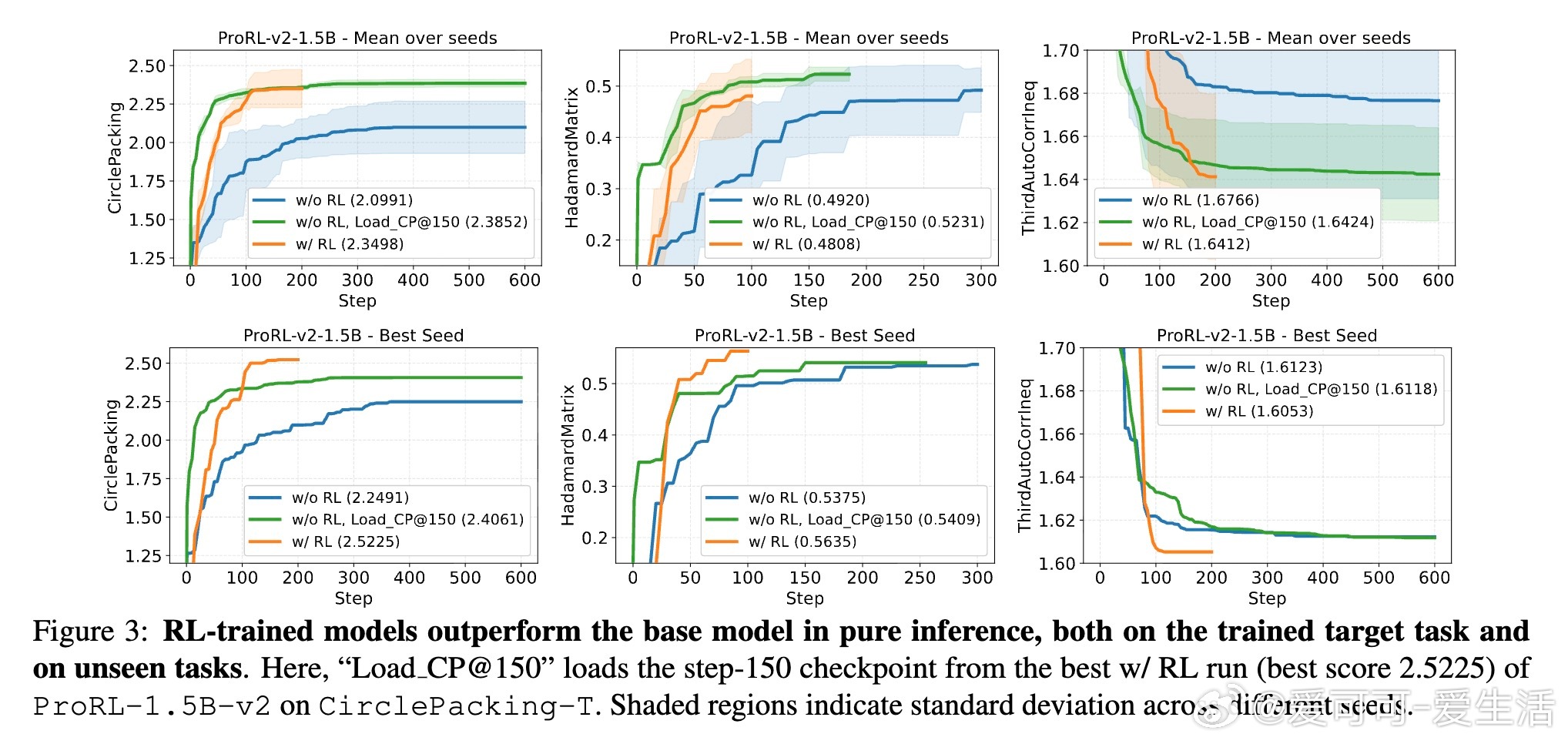
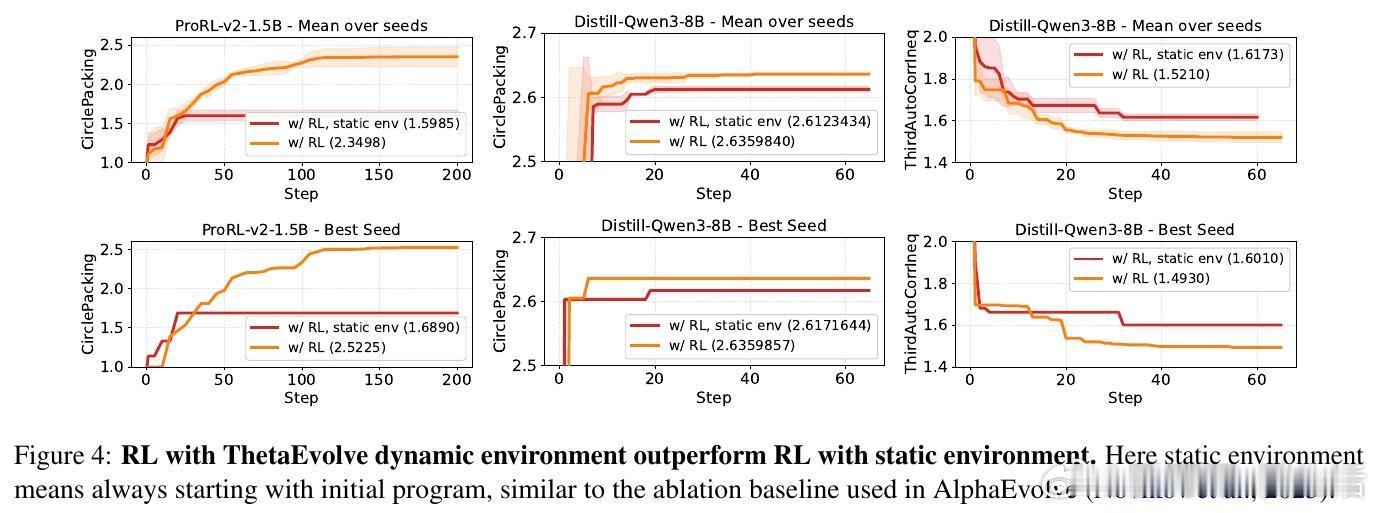
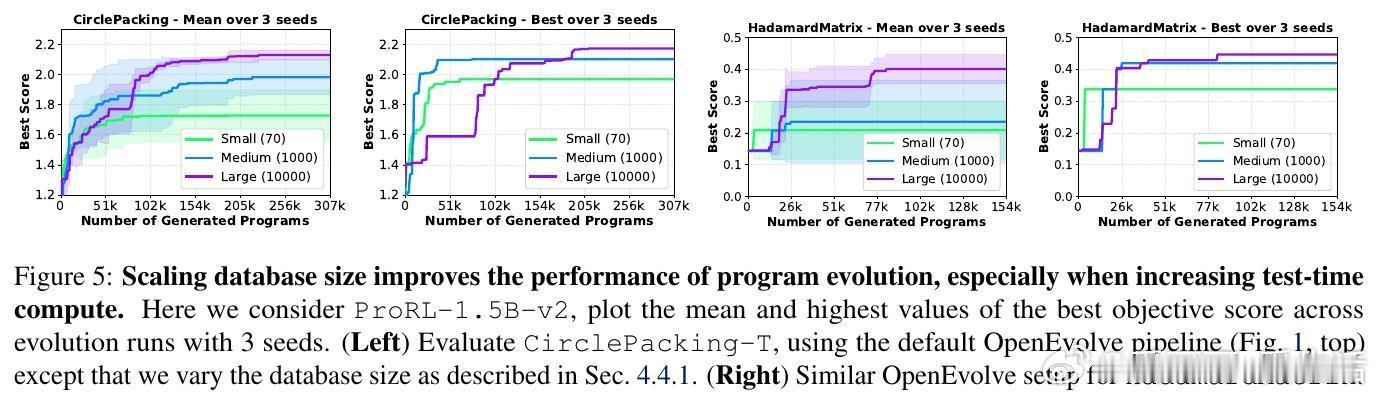
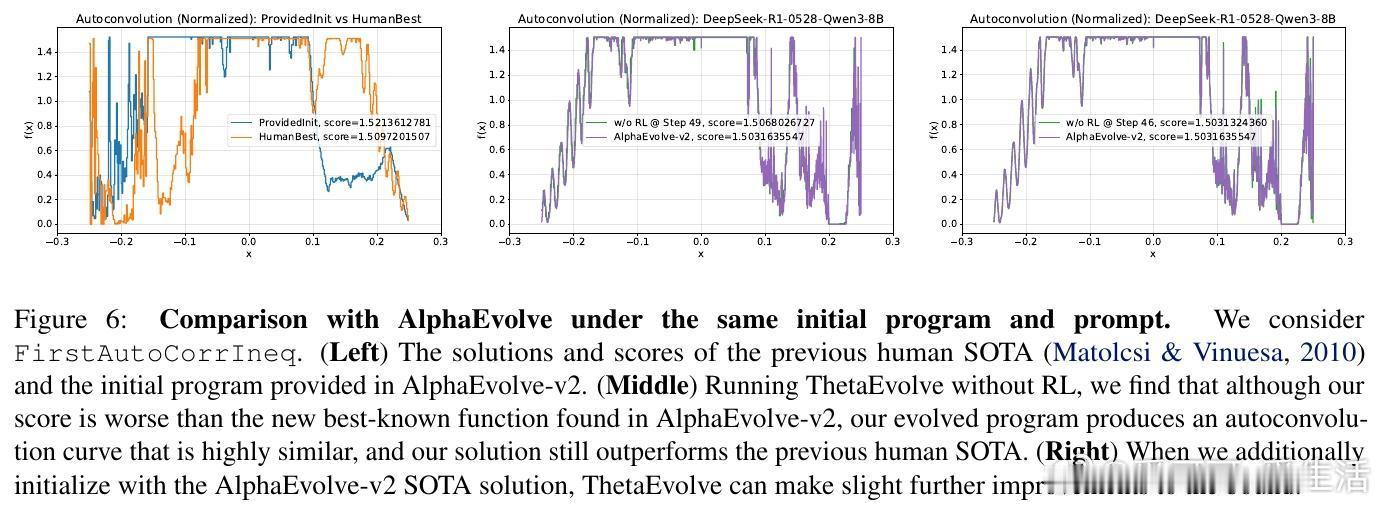
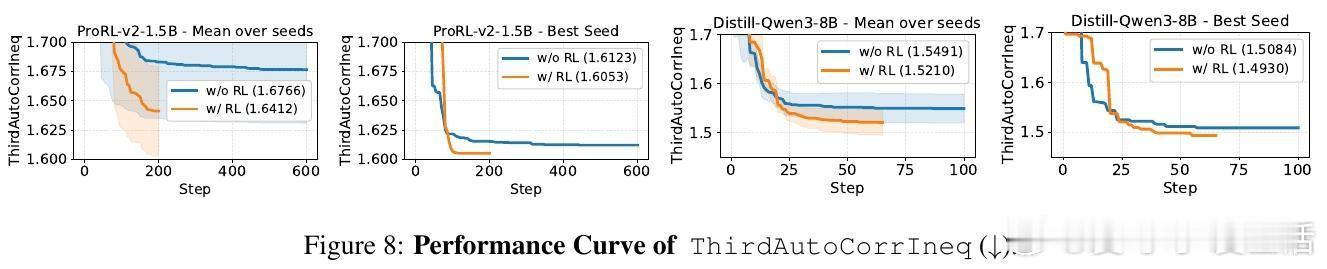
[LG]《ThetaEvolve: Test-time Learning on Open Problems》Y Wang, S Su, Z Zeng, E Xu... [Microsoft & University of Washington] (2025) ThetaEvolve:面向开放数学优化问题的测试时学习新框架近期,AlphaEvolve通过多模型集成实现了数学发现的突破,但存在封闭源代码、复杂管线和纯推理限制,无法让模型内部吸收进化策略。为此,ThetaEvolve提出了一种开放源代码的简化且扩展性强的框架,支持单模型驱动、规模化程序数据库、高吞吐量批量采样、懒惰惩罚机制及可选的强化学习(RL)奖励塑造,实现模型在测试时持续学习和演化。核心创新包括:1. 单一LLM替代多模型集成,极大降低系统复杂度。2. 大规模程序数据库(容量1万级),提升探索多样性与最终表现。3. 批量采样与生成,显著提高推理效率(速度比ShinkaEvolve快约25倍)。4. 懒惰惩罚机制,防止模型重复输出无改进程序,有效促进探索。5. 可选的RL奖励塑造,稳定训练信号,提升模型演化能力。实验证明,ThetaEvolve基于开源8B模型DeepSeek-R1-0528-Qwen3-8B,在圆盘打包(CirclePacking)和第一自相关不等式(FirstAutoCorrIneq)两大开放问题上刷新最佳已知界限,且RL训练显著优于纯推理,且训练后的模型在未见任务上也表现出更快的进步和更优的最终性能,展现了跨任务的能力迁移。此外,ThetaEvolve在数据库管理、批量采样、奖励塑造等关键设计上的消融实验,进一步验证了各模块对整体性能的贡献。相比AlphaEvolve及其开源变体OpenEvolve,ThetaEvolve实现了更高效且更容易复现的数学程序演化。这一工作不仅推动了开放数学优化问题的自动发现,也为模型测试时持续学习开辟新路径,强调动态环境与强化学习在复杂搜索中的重要性。未来,ThetaEvolve可拓展至多任务训练和更广泛的优化领域,助力构建能自主演进的智能系统。详情请见:arxiv.org/abs/2511.23473