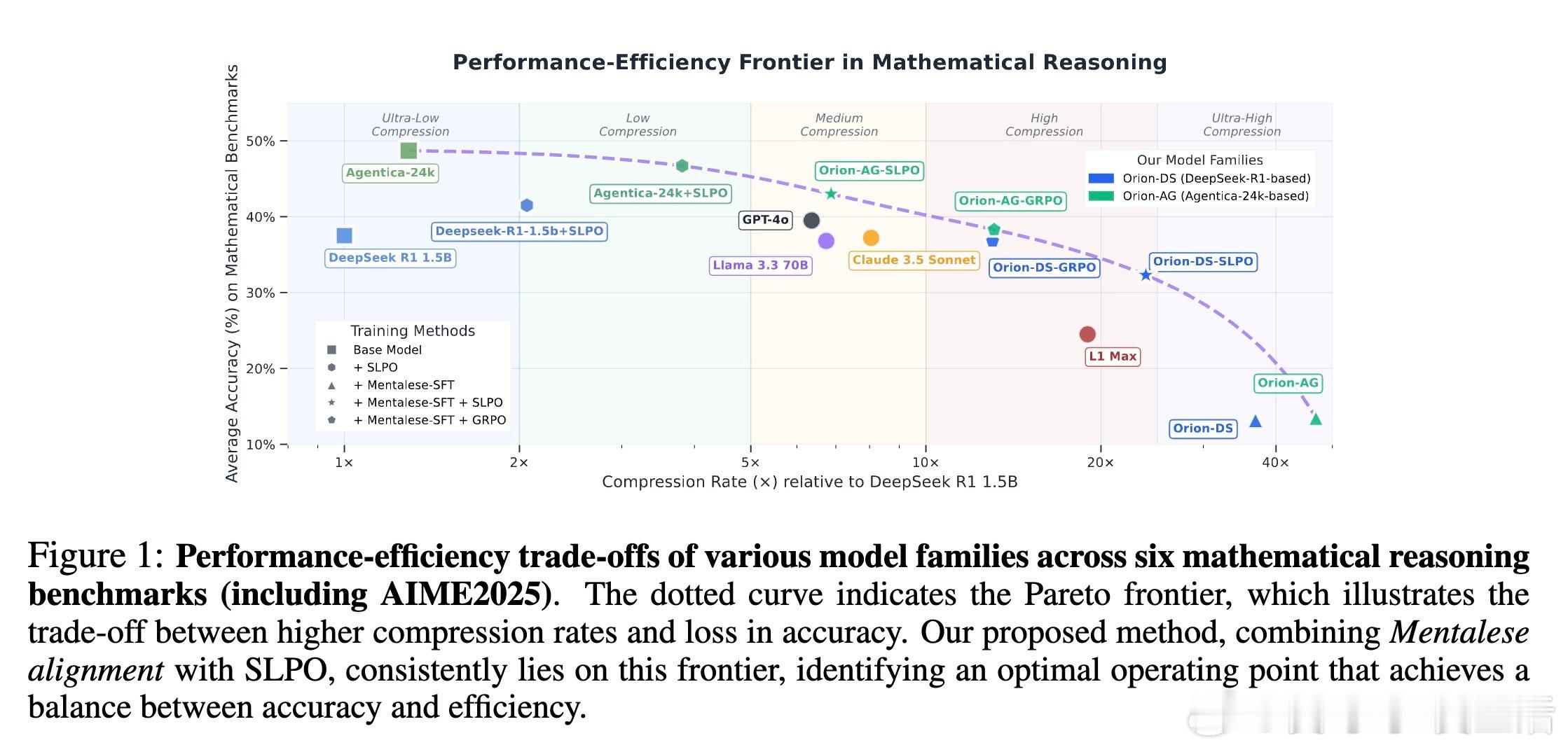
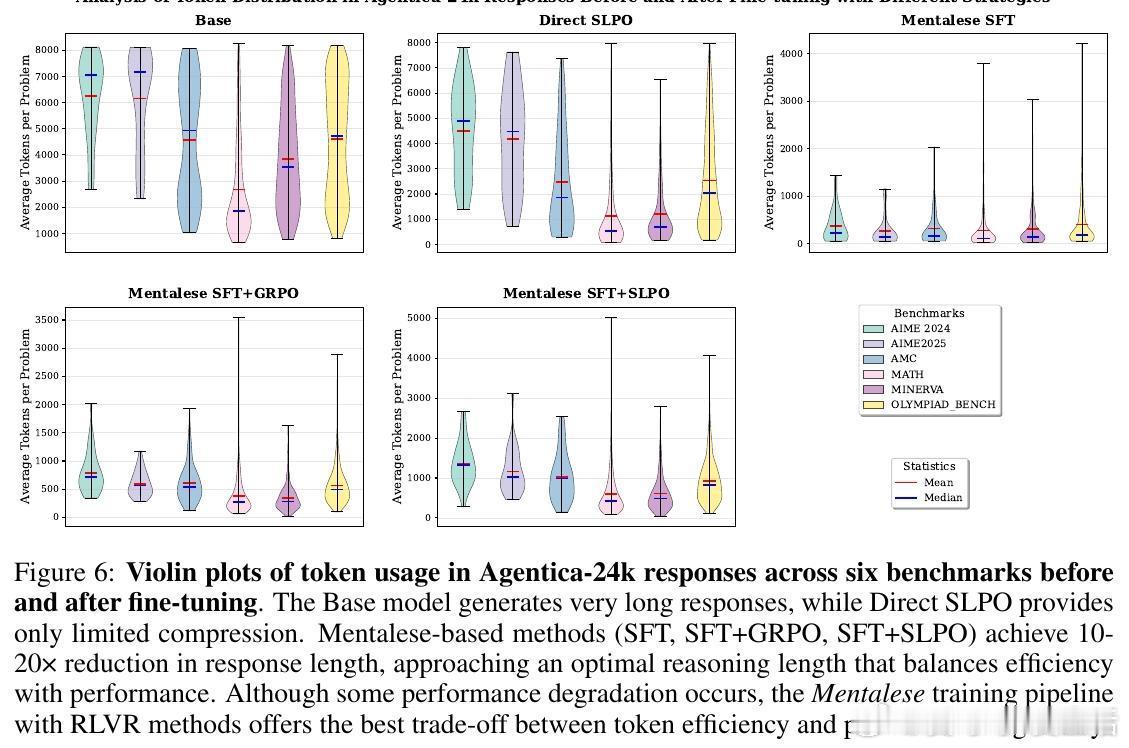
[LG]《ORION: Teaching Language Models to Reason Efficiently in the Language of Thought》K Tanmay, K Aggarwal, P P Liang, S Mukherjee [Harvard University & Hippocratic AI & MIT] (2025) 本文介绍了ORION,一种灵感源自“思维语言假说”(Language of Thought Hypothesis)的语言模型推理新框架。现有大型推理模型往往依赖冗长且重复的“思考”文本,导致推理效率低下且路径不自然。ORION通过引入“思维语言”Mentalese——一种紧凑且符号化的推理表达方式,实现了推理链条长度缩短10倍以上,同时保持90%-98%的准确率。核心创新包括:1. Mentalese:基于符号操作和表达式的形式推理语言,替代传统自然语言链式思考,极大压缩推理步骤,提升认知对齐和可解释性。2. 短长度偏好优化(SLPO):一种强化学习算法,智能权衡推理简洁性与正确性,不采用固定长度惩罚,而是通过奖励相对更短的正确推理路径,自适应地处理不同复杂度的问题。3. 训练流程:先通过监督微调使模型适应Mentalese格式,再通过带验证器奖励的强化学习(RLVR)恢复性能,避免了直接强化学习中常见的训练不稳定与推理路径冗长问题。4. 实验验证:在数学竞赛题库如AIME 2024/2025、Minerva-Math、OlympiadBench、Math500和AMC上,ORION模型产生的推理路径长度较基线DeepSeek-R1缩短4-16倍,推理延迟降低最多5倍,训练成本节约7-9倍,且准确率超越Claude和ChatGPT-4o达5个百分点。5. 通用性与稳定性:ORION在非数学领域(GPQA、LSAT、MMLU)同样表现出良好泛化能力,且训练过程更稳定高效,避免了直接SLPO训练时的崩溃现象。这项工作表明,推理无需冗长表达,符号化、结构化的“思维语言”结合智能优化策略,可以打造既高效又准确的推理模型。ORION为实时、高效、低成本的认知智能系统提供了新思路,特别适合对推理效率要求高的智能代理系统。全文详见:arxiv.org/abs/2511.22891代码即将开源于:网页链接——“真正的智慧,往往藏于简洁之中。推理的力量,不在于字数,而在于结构。”