[CL]《SPICE: Self-Play In Corpus Environments Improves Reasoning》B Liu, C Jin, S Kim, W Yuan... [FAIR at Meta] (2025)
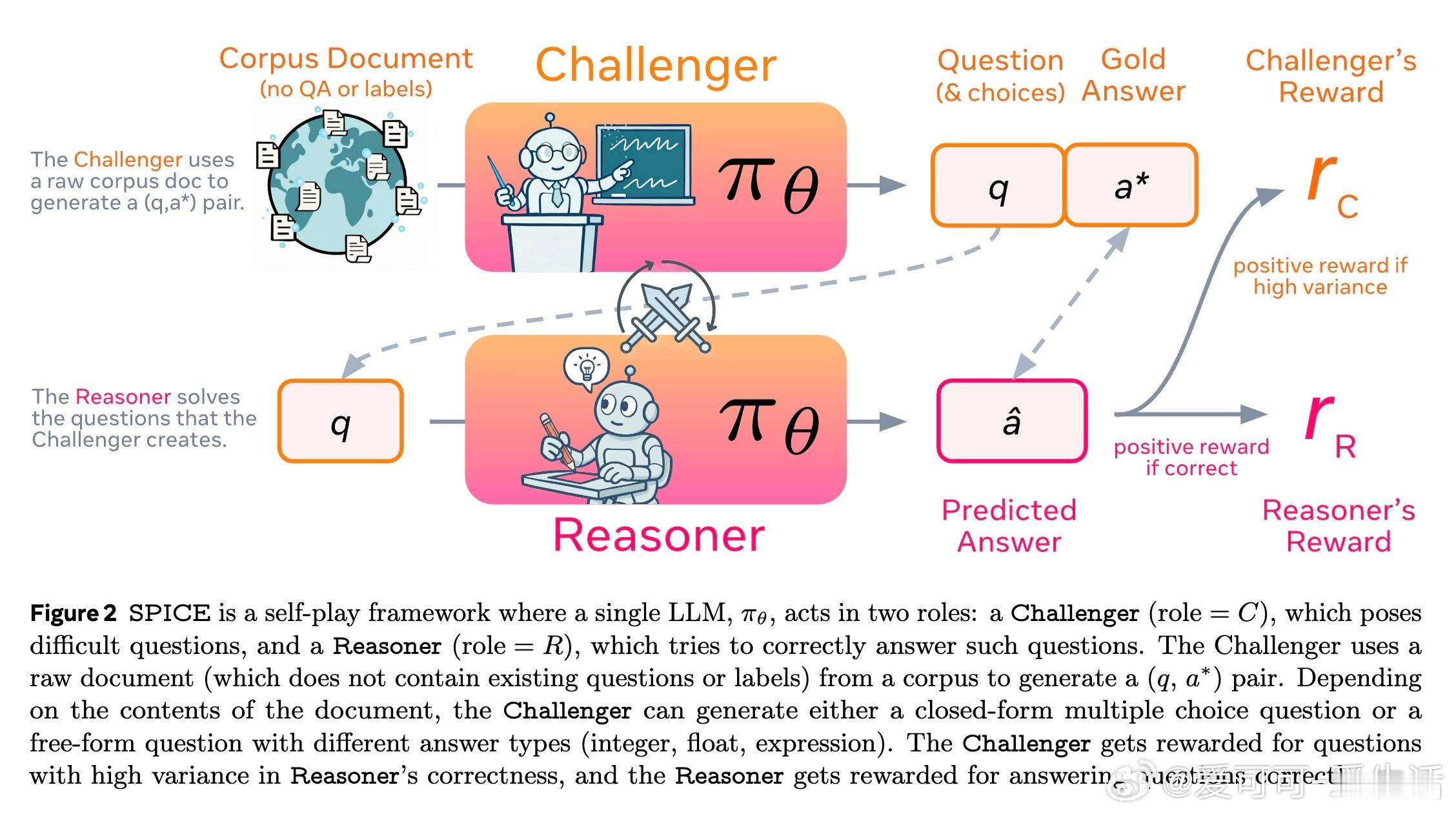
在追求自我提升的人工智能领域,SPICE(Self-Play In Corpus Environments)提出了一种创新的自我对弈强化学习框架,显著突破了传统无外部知识支撑的自我对弈方法的瓶颈。SPICE通过让同一个大语言模型(LLM)扮演两个角色:一方面作为“挑战者”(Challenger)从大规模文档语料库中挖掘信息,生成带有事实依据的多样化推理任务;另一方面作为“推理者”(Reasoner)在无文档访问的情况下解决这些问题。此设计实现了信息不对称,挑战者拥有文档信息,推理者则仅凭模型内化知识作答,避免了幻觉放大和信息对称导致的学习停滞。
SPICE的核心创新包括:
1. 文档语料库作为外部环境:利用海量且多样的真实世界文档,提供丰富且可验证的训练信号,防止模型陷入自生成数据的虚假循环,实现持续的自我提升。
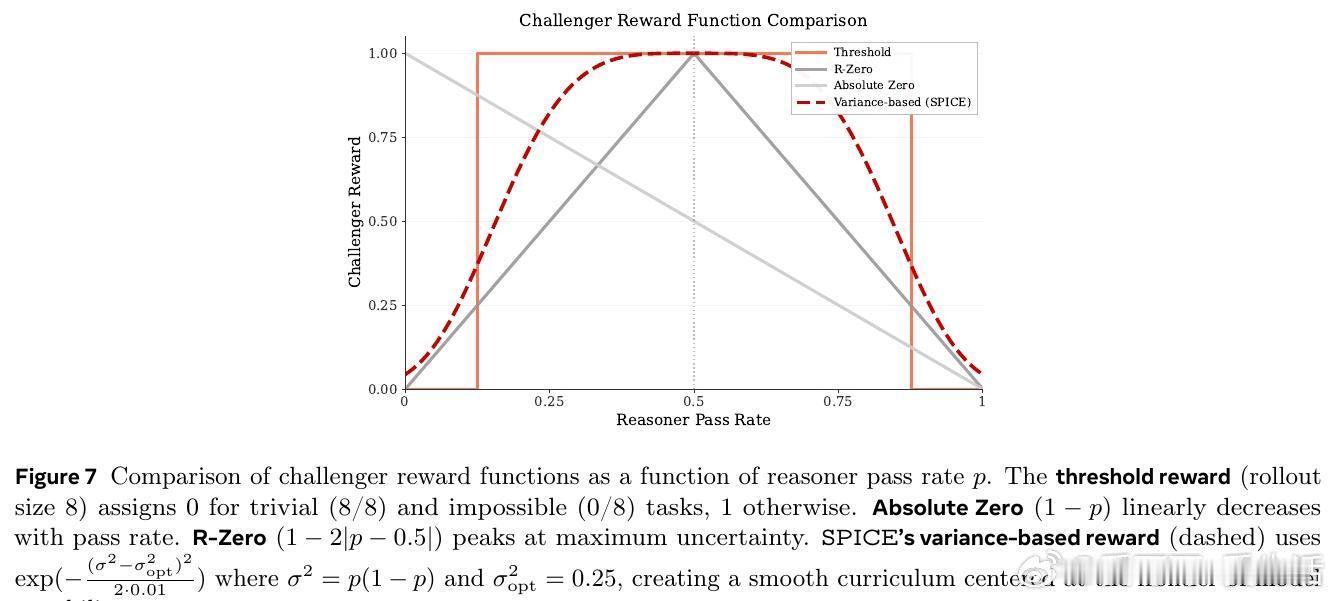
2. 自动难度调节的对抗式训练:挑战者依据推理者的表现,动态生成难度适中的问题,奖励函数设计为对推理者答题正确率方差的高斯函数,最大化学习边界的挑战任务,形成自动课程。
3. 多任务格式支持:结合多项选择题与自由形式问题,既保证了答案验证的可靠性,也鼓励了模型的灵活推理能力。
4. 统一模型共享权重,角色切换训练:通过单模型在两个角色间切换,实现协同进化,推理者解题能力与挑战者出题能力共同提升。
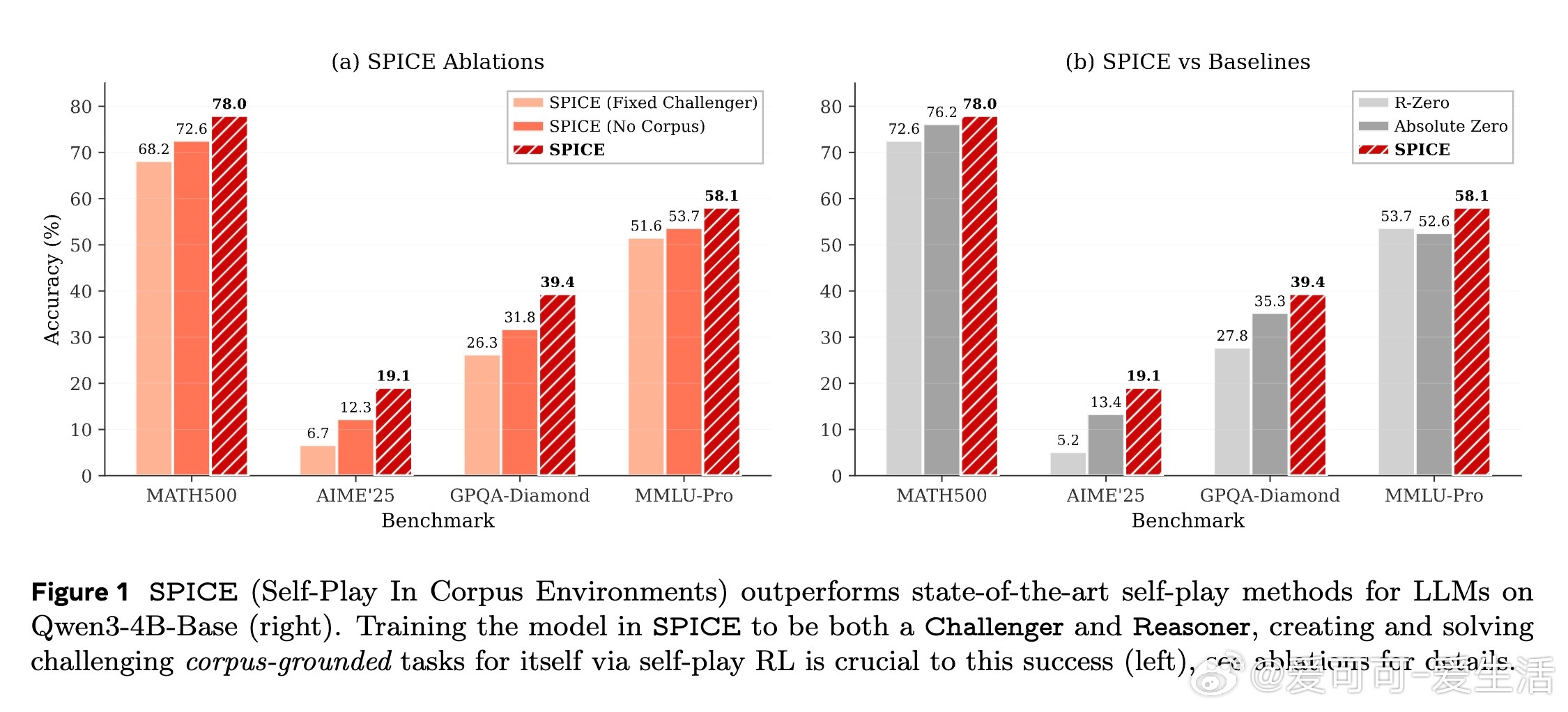
实验结果显示,SPICE在四个基础模型上均实现了显著性能提升,数学推理任务提升约8.9%,通用推理任务提升约9.8%,全面超越了包括纯自我对弈(R-Zero)、固定强挑战者(Strong Challenger)及代码执行验证自我对弈(Absolute Zero)等多种先进基线。详细分析揭示,文档基础的外部知识是持续提升的关键,缺失文档支撑的模型表现提升有限且易陷入停滞。
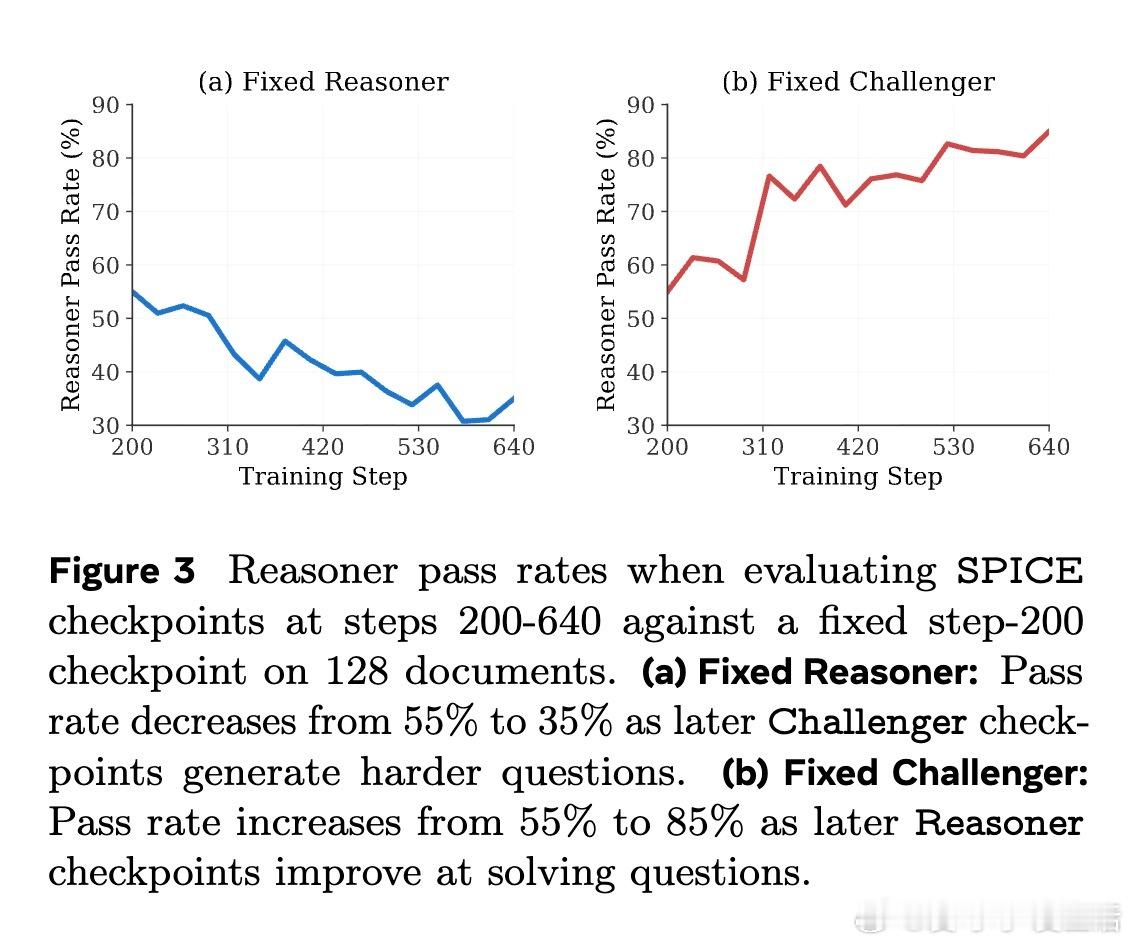
定性研究显示,随着训练进展,挑战者逐渐生成更复杂、多步骤、多概念综合的题目,推理者的解题策略也由直觉猜测转向严谨的分步推理和结果验证,体现了真实的思维进化而非简单记忆。
消融实验进一步验证:
- 语料库多样性(数学语料与自然推理语料结合)带来最佳整体提升。
- 同时使用多项选择与自由形式题型相比单一题型更优。
- 挑战者奖励设计中基于答题正确率方差的高斯奖励优于线性或阈值奖励,更有效引导模型生成边界难度题目。
SPICE的提出标志着自我提升推理系统从封闭循环的内省式学习向开放交互式学习转型,借助真实、可验证的外部知识环境,突破幻觉与信息对称的根本限制,实现了无人工监督下的持续自我进化。此框架为未来通用人工智能的发展提供了新范式。
完整论文链接:arxiv.org/abs/2510.24684