[LG]《Defeating the Training-Inference Mismatch via FP16》P Qi, Z Liu, X Zhou, T Pang... [Sea AI Lab] (2025)
在强化学习(RL)微调大型语言模型(LLMs)时,训练与推理之间存在数值精度不匹配问题,导致训练不稳定。传统方法多依赖复杂的算法修正和工程调整,成本高且效果有限。本文指出,问题根源在于浮点数精度的选取:目前主流的BF16格式虽动态范围大,但精度不足,易产生累计的舍入误差,造成训练与推理策略不一致。
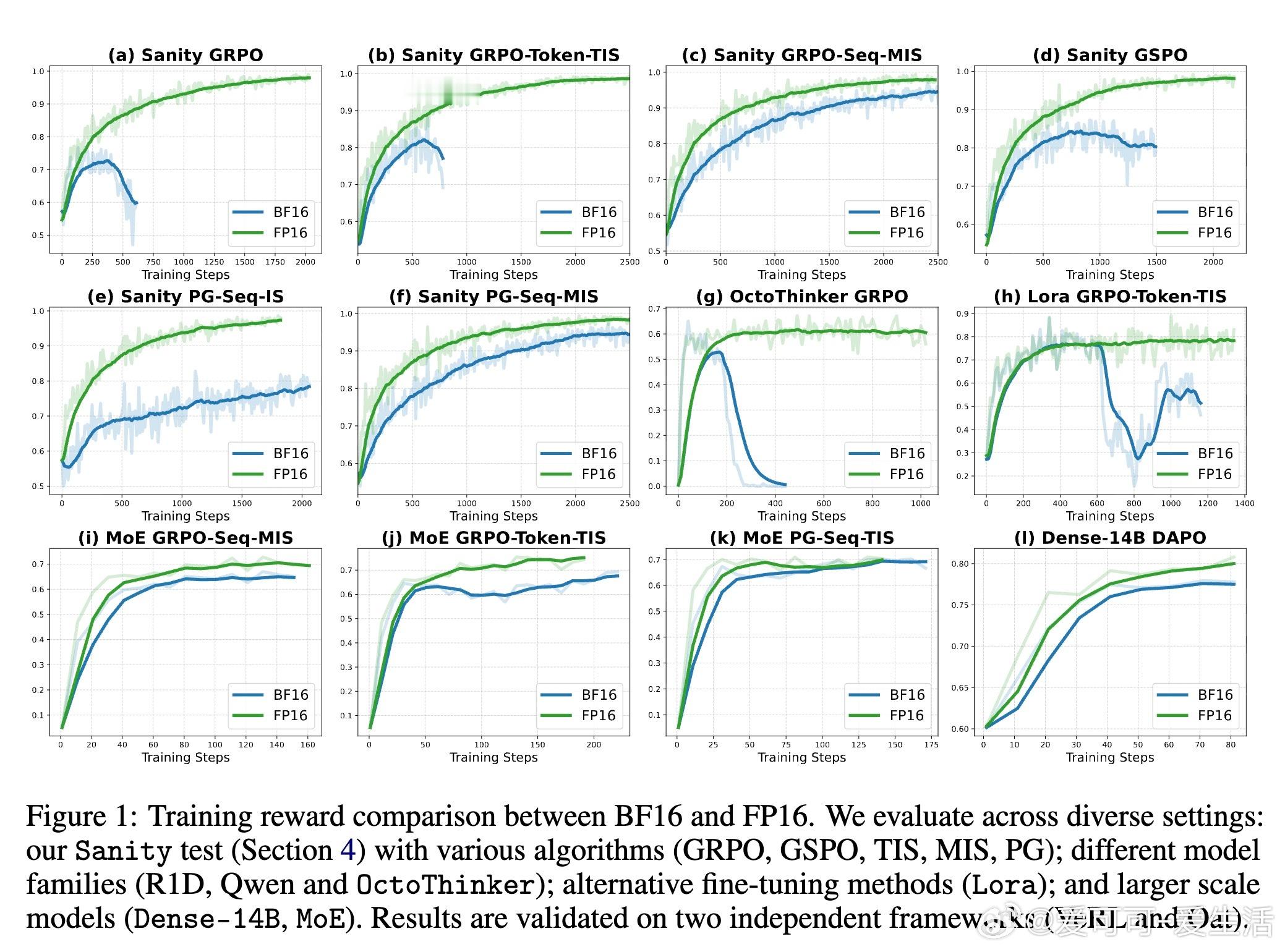
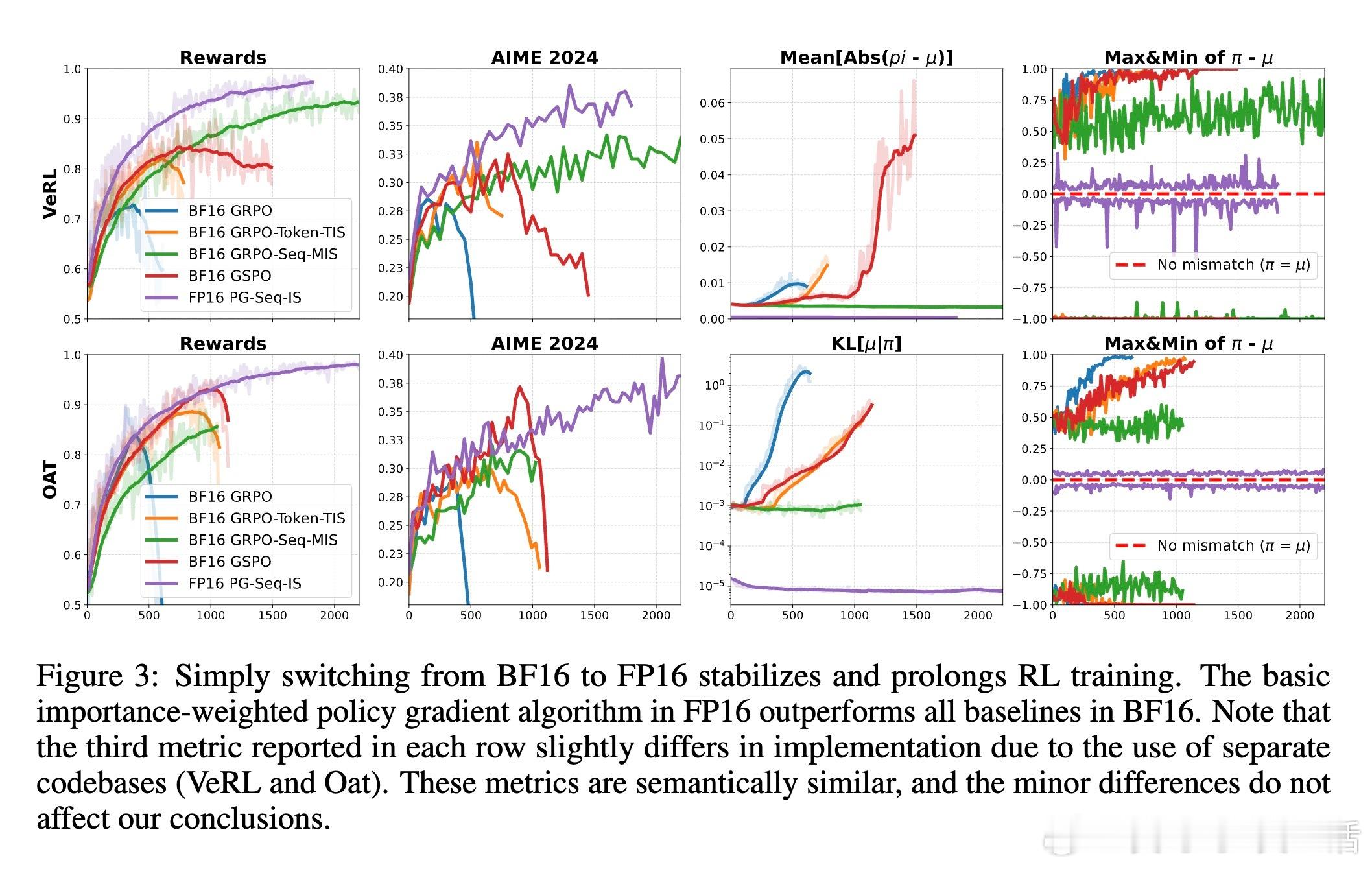
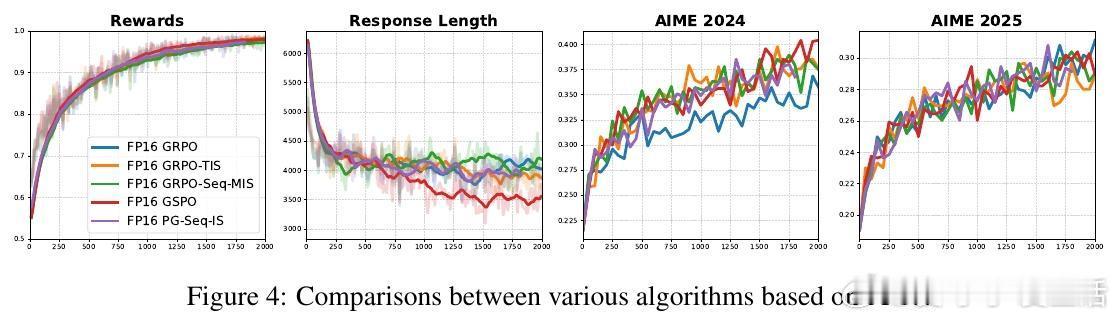
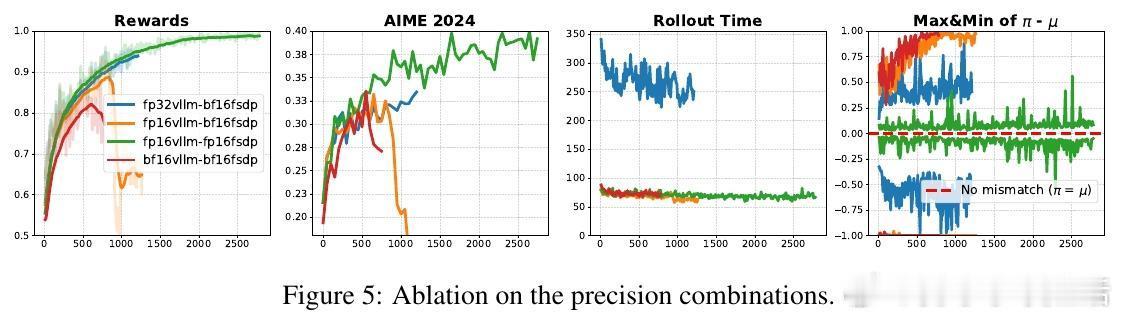
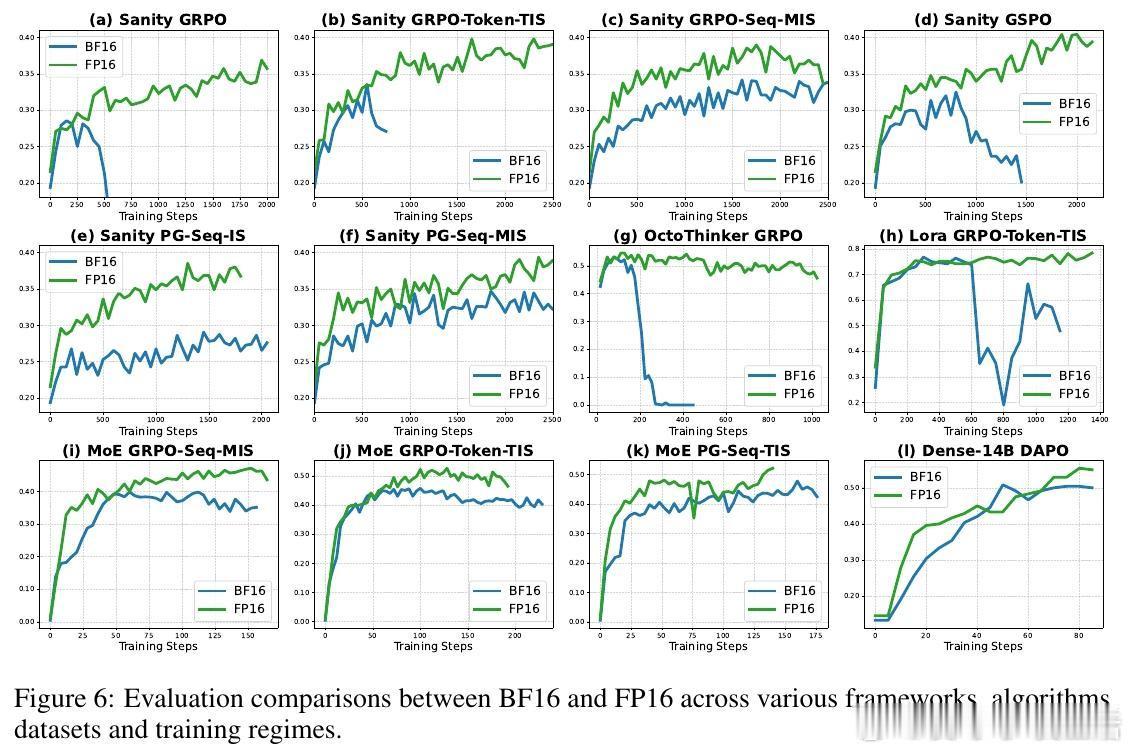
作者提出一个简单但颠覆性的解决方案:将训练和推理的数值格式从BF16切换回FP16。FP16拥有更多的尾数位(10位对比BF16的7位),精度显著提升,极大降低了训练推理间的数值差异。这一改变不需改动模型结构或训练算法,只需少量代码修改,即可实现。实验覆盖多种算法(GRPO、GSPO、PG等)、模型结构(Qwen、OctoThinker、Dense-14B、MoE)、以及不同训练框架(VeRL、Oat),均显示出FP16带来的训练稳定性提升、收敛速度加快和性能增强。
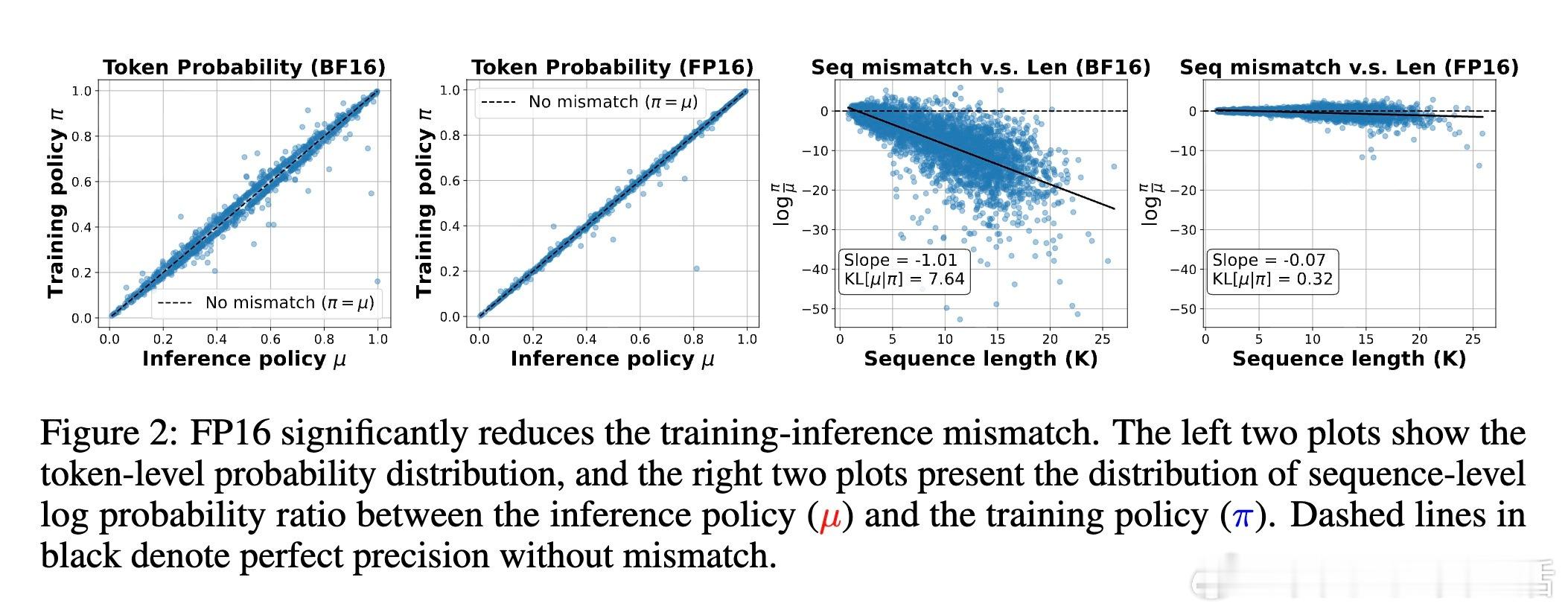
更重要的是,FP16有效解决了长期存在的“部署差距”问题——即训练时优化的策略与实际推理使用的策略不匹配,导致性能下降。现有算法修正只能缓解偏差梯度但无法根治部署差距,而FP16通过根本上减少数值误差,使训练与推理几乎一致,消除该差距。
此外,本文创新性地设计了“完美可提升数据集”作为“理智测试”,剔除过易或过难题目,精准评估RL算法的可靠性。结果证明,使用BF16时多数算法训练不稳定甚至崩溃,而FP16下所有算法均表现优异且差异缩小,说明数值精度是影响训练稳定性的关键因素。
论文还详细解析了FP16与BF16的技术差异及FP16训练中常用的“损失缩放”技术,确保训练过程数值稳定。实验证明FP16不仅适用于标准模型,也适合LoRA微调、MoE模型及超大规模模型训练,具备广泛适应性。
总结来看,本文提供了一个极简且高效的方案,呼吁社区重新审视FP16在RL微调中的价值。它不仅提升了训练的稳定性和性能,还降低了实现复杂度,对推动大型语言模型的强化学习微调具有重要意义。
详细论文链接:arxiv.org/abs/2510.26788
> 关键观点总结
- 训练-推理数值不匹配是RL微调不稳定的根源
- BF16精度不足导致累计舍入误差,产生策略偏差和部署差距
- 切换到FP16大幅提升数值精度,几乎消除训练-推理不匹配
- FP16无需复杂算法修正,简单易行且兼容主流框架
- 多模型、多算法、多环境均验证FP16优越性
- 引入“完美可提升数据集”作为算法可靠性理智测试
- FP16有助于解决偏差-方差权衡,提升训练稳定性和性能
- 重新思考数值精度选择对RL微调的重要性,推动技术进步
这项研究为RL微调大型语言模型提供了清晰且直接的技术路径,值得业界广泛关注和采纳。