LoRA Without Regret:高效微调大模型的新时代
当今顶尖语言模型拥有上万亿参数,预训练用数十万亿token,规模越大表现越好。但后续微调往往数据集较小,专注于更窄的领域,用庞大权重调整小规模数据,资源消耗巨大且效率低下。
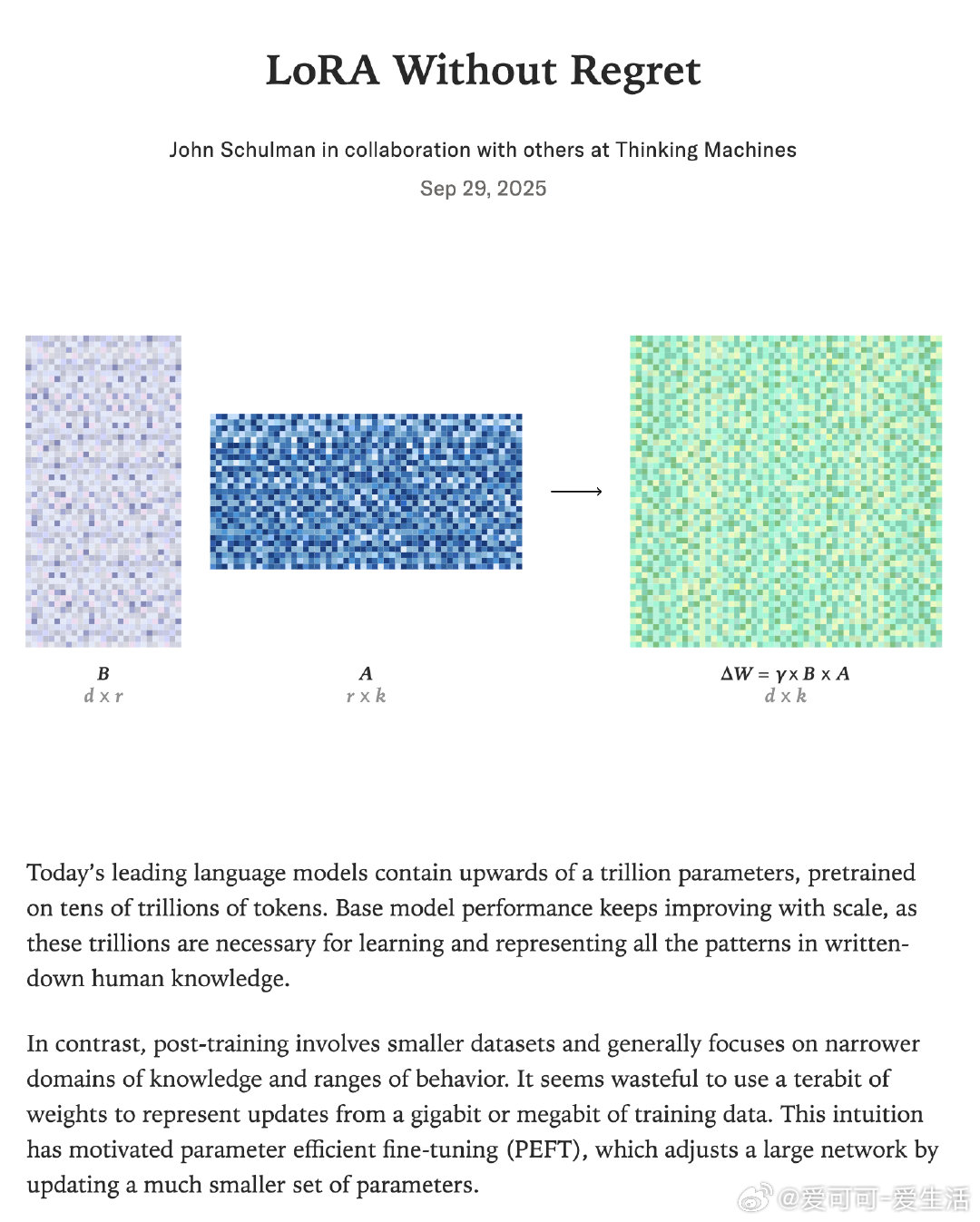
LoRA(Low-Rank Adaptation)提出:用低秩矩阵B、A替代权重更新,模型参数=原权重+γBA,极大减少微调参数量,实现参数高效微调(PEFT)。优势显著:
- 多租户服务:多个LoRA适配器共享原始权重,节省内存,支持并发推理。
- 训练布局小:显著降内存需求,训练更经济、更便捷。
- 便于加载与迁移:参数少,适配器轻量,易于部署。
核心发现:
1. 样本效率无损:在大多数后训练场景,LoRA在适当参数规模下,效果等同于全量微调(FullFT)。
2. 全层应用更优:不仅仅是注意力层,MLP及MoE层也需覆盖,才能充分发挥LoRA潜力。
3. RL任务更低容量需求:强化学习中,LoRA即使秩极低也能匹配FullFT表现,信息理论支持此结论。
4. 学习率差异显著:LoRA最佳学习率约是FullFT的10倍,且对秩变化不敏感。
5. 批量大小敏感度:LoRA对大批次训练更不耐受,可能因矩阵乘积参数化导致优化动力学不同。
6. 计算效率提升约33%:单步计算量仅为全量微调的2/3,有助加速训练。
此外,研究揭示LoRA的训练动态具有内在不变性,降低了调参难度。其成功不仅推动了高效微调技术的发展,也深化了我们对模型容量、数据复杂度与样本效率的理解。
未来挑战包括精确预测LoRA表现边界、理论解释学习率差异、以及探索MoE层的最佳LoRA策略等。
详细阅读👉 thinkingmachines.ai/blog/lora/