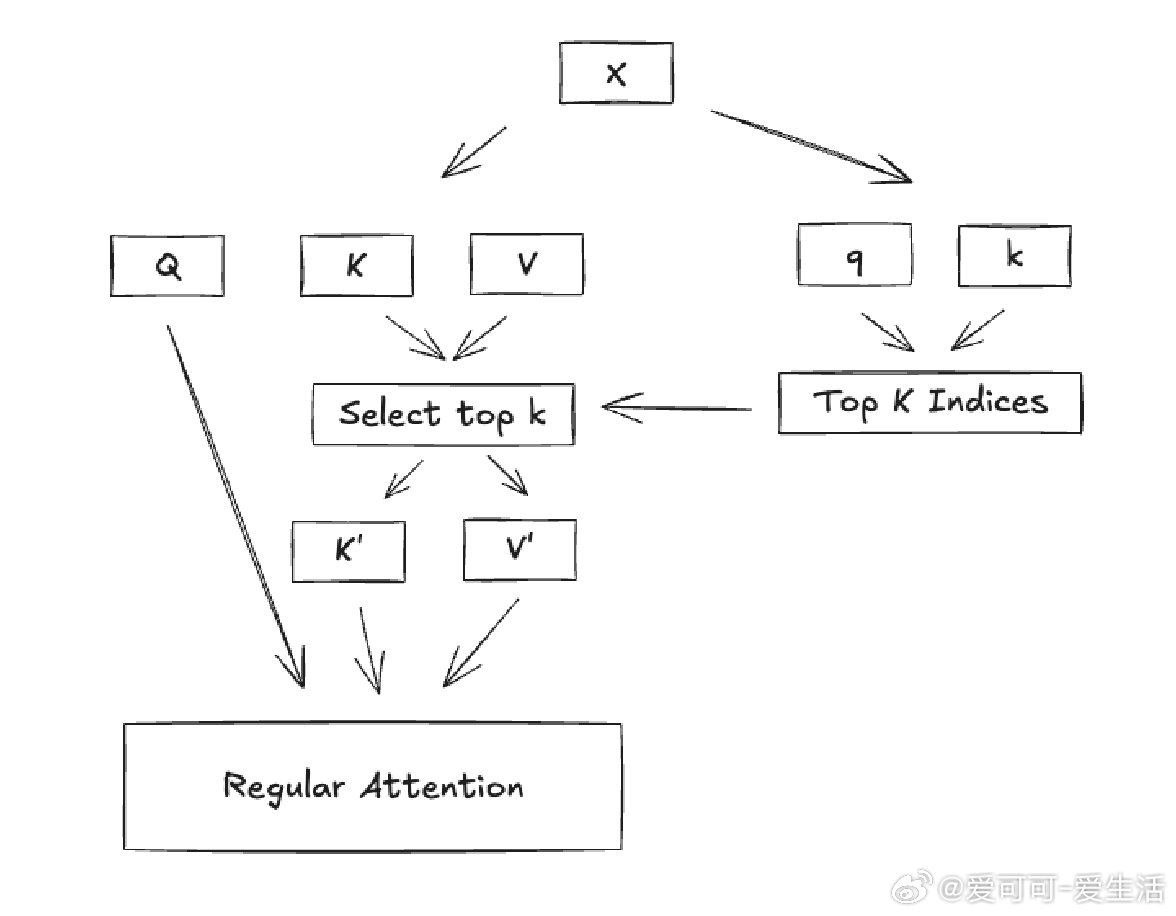
Awni Hannun分享了DeepSeek v3.2中稀疏注意力机制的简洁设计思路:
- 先用一个完整的注意力层(或如DSV3中的MLA)。
- 同时用一个轻量级注意力层,仅计算query-key分数。
- 从轻量层中选出每个query的top-k索引。
- 用这些top-k索引限制完整注意力层关注的key和value范围。
轻量层虽然仍是二次复杂度,但设计得非常快(v3.2中只用一个key头,维度128)。这种两阶段过滤机制,兼顾效率与效果,值得与滑动窗口注意力及混合层方案如Mamba2对比性能和内存占用。
大家讨论中也提到:
- 轻量层的开销是否还优于滑动窗口,尤其在长序列上?
- Softmax 机制面临被替代的趋势。
- 这种设计思路体现了AI在效率和精度之间的平衡创新。
这不仅是技术细节,更是未来模型架构优化的重要方向。期待更多实测和分析,推动稀疏注意力更广泛应用。
原推文链接: x.com/awnihannun/status/1972763521185436088